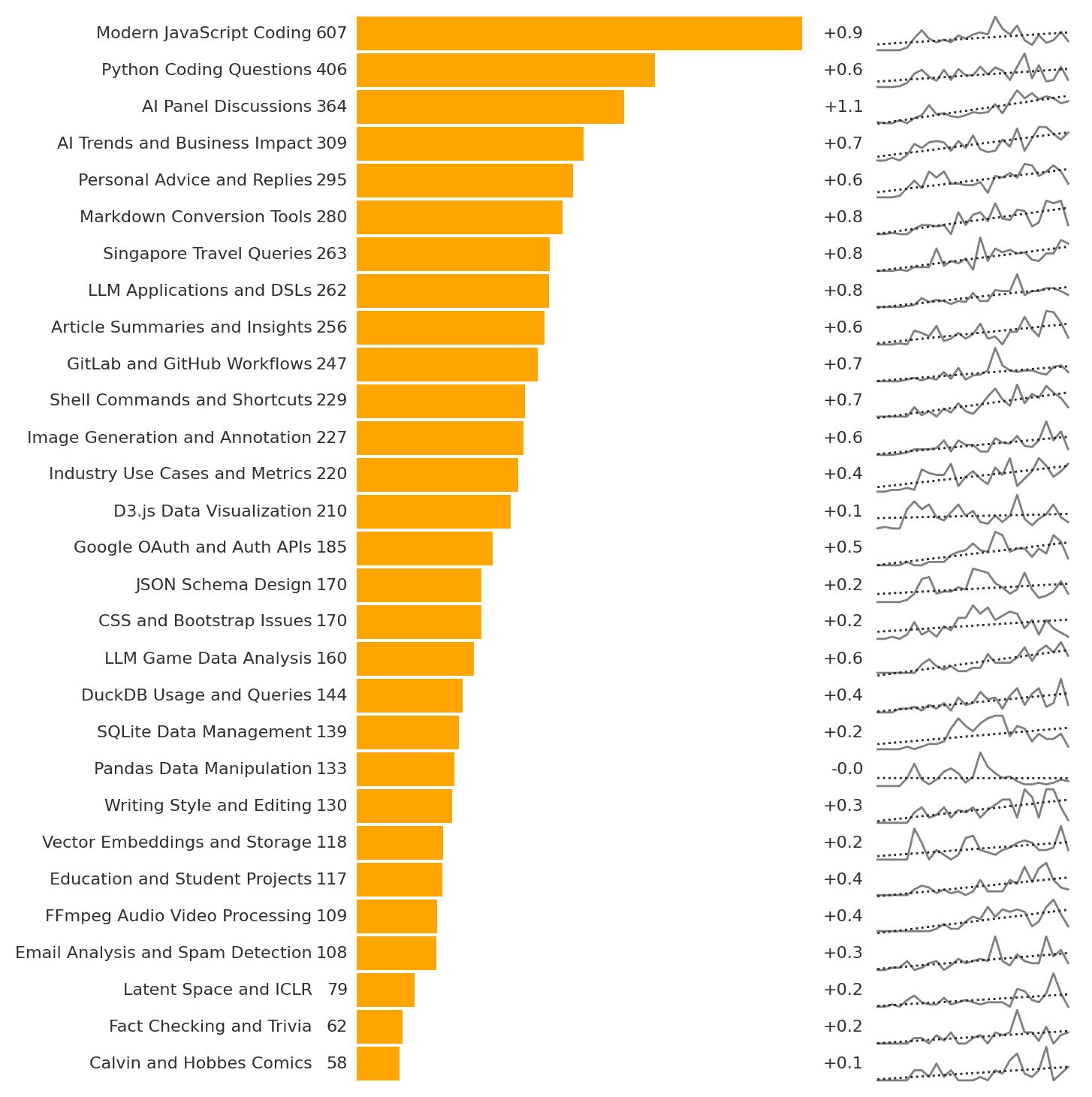
This week, I learned:
Never use a toothpick on a tooth with a dental crown. Only use a flosser or water flosser. CSS attr() is one of the most powerful features in modern CSS. It lets you control CSS via HTML attributes. Notes from Anthropic’s How we built our multi-agent research system: Sub-agents are like humans -> society. The improvement is dramatic. “Sub-agents facilitate compression by operating in parallel with their own context windows, exploring different aspects of the question simultaneously before condensing…” “Each sub-agent also provides separation of concerns—distinct tools, prompts, and exploration trajectories … (enabling) independent investigations.” Using sub-agents spends ~15x more tokens. (That explained ~80% of the improved accuracy!) Particularly effective when tasks are independent and parallelizable. This also speeds it up. Teach the orchestrator how to delegate: how many sub-agents, what objective + output format + task boundaries (MECE to avoid overlap with other agents) in prompt, what tools. Teach the orchestrator how to improve agents: e.g. tools to test and rewrite tool descriptions Even if you evaluate a few examples, evals are surprisingly effective. Agents are stateful. Errors compound. Allow agents to resume. Prune history gracefully. Log everything to debug user-reported failures. Also monitor the kinds of decisions it took to help debug at scale. The Bitter Lesson likely applies to system prompts. Don’t hard-code stuff. I’m impressed that there is no system prompt in the default pydantic-ai Agent. The MCPs developers seem to use the most are: filesystem, playwright, github, slack, notion. Anecdotally, Claude 4 Sonnet seems a better coding model than Claude 4 Opus. Dan Becker, Armin Ronacher #ai-coding Cursor offers background agents that run in a remote container. #ai-coding Fabric has a collection of re-usable prompts that you can use via llm-templates-fabric like: cat file.py | llm -t fabric:explain_code Ref As of Jun 21, Claude 3.5 Sonnet > Claude 3.7 Sonnet > O3 Mini > Human > Gemini 1.5 Pro lead the Vending Bench. Gemini 1.5 Pro also leads my System Prompt Override benchmarks. I’m losing faith in the LM Arena. Perhaps the Gemini models aren’t improving as much as we think. This is the core of agents (LLMs running tools in a loop): Sketch blog Full script Notes on AI coding / vibe-coding from multiple sources. #ai-coding Sources How I program with LLMs How I program with agents The 7 Prompting Habits of Highly Effective Engineers AI Assisted Coding A Glimpse of the Future Agentic Coding Recommendations My First Open Source AI Generated Library We Can Just Measure Things I Shipped a macOS App Built Entirely by Claude Code Measuring the Impact of Early-2025 AI on Experienced Open-Source Developer Productivity Why AI coding? Reduces mental energy (by creating the first draft). letting you create more. Reduces starting trouble, eases effort. Helps figure out how easy / tough a task really is!! Most code is short-lived or has few users. AI building “throw-away” code is useful. Why NOT AI coding? Slows you down if you know the repo well Doesn’t work well on large/complex/niche repos Leads to over-optimism and atrophy Tips Use for reversible decisions (2-way doors). Avoid for irreversible ones (1-way doors). Fail early. Try tough bits first. Fail often. Restart instead of fixing. Go concurrent. Trigger multiple tasks. Ask for multiple drafts and options. Give it workflow. Break down the implementation into: 1. Planning. 2. API stubs. 3. Implementation. Give local context. Naming conventions, folder structure, coding style, tools (compile, test, lint), etc. Conserve context. Use sub tasks and sub agents to conserve context. Suggest libraries. Agents prefer writing code than using libraries, by default. Give examples to follow, e.g. Write it like @filename. & -> & but &x -> &x. Give screenshots and logs. These are very effective. Provide goals, not instructions. Saves effort, teaches you new things. Farm out research. Have specialized tools research API docs, etc. and include those in the context. Keep related things together. Have it write a checklist, e.g. saving it temporarily in a file. Have it run code to catch its own errors. Have it write tests, mocks for tests. Have it see and use the app, click, play around, etc. (e.g. via playwright-mcp) Have it create playbooks, examples, troubleshooting guides. Have it refactor code AFTER comprehensive tests. Have it think more. Use ultrathink. Log extensively, by default. Improves future debugging. Report errors well. What happened, why, and what to do. Prefer monorepos for more context. # Prefer popular libraries. LLMs know these better. Prefer fast tests, tools, and libraries. Speed helps iteration. Prefer small files and packages. Reduces context. Prefer simple code. Avoid magic, e.g. pytest fixture injection. Functions over classes. SQL over code. Composition over inheritence. Prefer specialized functions for common scenarios over DRY abstractions. Prefer fewer abstraction layers. Prefer re-implementing over DRY since code is cheap. Look for new tricks to learn from its code. Agent behaviors: Simple tasks perform better. More context = more confusion. Verifiable tasks are clearer for LLMs and and easier to review. Useful coding agent tools: bash(cmd), patch(hunks), todo(tasks), web_nav(url), web_eval(script), web_logs(), web_screenshot(), keyword_search(keywords), codereview() Skills: LESS Coding LESS Research LESS Documentation LESS Operations configuration (IaaC, CI/CD, etc) LESS Editor usage and expertise required MORE Tests (to test the code) MORE Code reviews (to test the code) MORE Prompting and context creation (to write the code) MORE DevOps (micro-feature deployments, deploy in parallel) MORE Specs: features, requirements, APIs, tests, structure, etc. MORE Analysis: security, performance. MORE Tool design. Linters, SAST, DAST, Performance, etc. Semgrep, Bench Suite MORE Observability: Especially for tools and LLM calls. Telemetry, log analysis and issue creation. Sentry, LogFire, etc. Trends: Agents took time to evolve because LLMs need to be good at tool calling and long instruction following, which is just happening. Agents are slow. Parallelizable tools (e.g. multiple Redis instances, container-use, CI/CD) will grow. Tool speed (e.g. fast test engines with caching) will become more important. Agents generate diffs/PRs. Tools to edit and comment on these online will emerge. Context gathering will widen: screenshots, logs, etc. Code review process will be re-invented. Personalized features. User drops a feature request via Slack. Personalized version deployed at their endpoint to test. PR sent after they are happy Poor coding teams get less out of AI coding. Good communication, reviews, coding practices, testing, etc. help. Agent Experience (AX) is emerging and explores: how much context to take, when & how often to ask the user questions, to how make review easier, etc. Humans running multiple tasks in parallel is productive. Breaking a complex requirement into tasks (like Codex now does) helps create that task queue. Agents generate technical debt faster than humans. Solving this will become a major problem/opportunity. “makework”: made-up work that fills time or serves short-term needs. From GPT 4.1 Prompting Guide Use more precise prompts. Earlier models inferred user intent. GPT 4.1 follows prompts more closely. Avoid STRONG untested instructions. E.g. “you must call a tool before responding to the user” can lead to tool input hallucination. For agents, include these three system instructions: You are an agent. Keep going until you’re sure the user’s query is completely resolved. If you are not sure, use your tools: do NOT guess or make up an answer. Plan extensively before each function call. Reflect on the outcomes of the previous function calls. DO NOT do this entire process by making function calls only, as this can impair your ability to solve the problem and think insightfully. Use tools field rather than injecting tools into system prompt. Model has been trained to use tools field. Keep tool descriptions concise. Provide examples for complex tools in system prompt. Place instructions at the top of the context; ideally at the end, too. Format prompts as Markdown, XML, not JSON. It sometimes dislikes large repetitive output (e.g. analysis of hundreds of items) and needs nudging. It handles diffs well and can apply patches Metaprompting. Have frontier LLMs revise prompts. They’re GOOD! Ref Increase clarity, providing step-by-step instructions. Resolve conflicting instructions. Expand instructions to cover all scenarios and edge cases. Notes from Pydantic AI GitHub CI: UV_PYTHON sets default Python version COLUMNS increase terminal width uv run supports --extra for extra packages cloudflare/wrangler action has a deploy that allows deployment to specific URLs or subdomains Adding QR code to all slides in a deck (linking to the slides) helps. People take photos of random slides and this lets them get the link wherever. PyOpenLayers adds interactive mapping via OpenLayers to Marimo and Jupyter Conversation is about positioning. For example: TechCrunch interviewer: Anthropic released Claude Opus 4 thought it blackmailed people. Is Anthropic is becoming less safety conscious? Kaplan: We have very strong testing. So we’re more more likely to spot AI dangers early. We share such reports to set higher standards for transparency. From LLM Evals: Common Mistakes: Using foundation model evals instead of application evals is like evaluating a candidate on SAT scores. It’s fine, but you also want to evaluate them on their specific job description. Evals must be done by the users and not outsourced. Evals are not draining. Small samples have high value. When using LLM as a judge, be VERY VERY specific about the criteria. Prefer binary LLM evals over scales. Monitor performance online, not just while deploying From Andrew Ng on AI Agents: AI is like electricity. It’s hard to define what is good for because it is good for so many things, most of them new that never existed before If experimentation is cheap, it makes sense to run far more experiments. Rather than think hard about what to prototype, explore how to build many diverse prototypes. Prototyping is now very fast but other steps like reliable evaluations for deployment still take time. But the speed of prototyping is putting pressure on other parts of the organization to go faster. While large language models and applications were serving human needs so far, increasingly they will serve the needs of AI and other tools. Since unstructured data is now more valuable, there will be a growth in data engineering on unstructured data. Models.dev is an open source database and API of LLM models Logprobs are back on models in Vertex AI. Ref For all AI code, review it, learn from it and share learnings. That prevents bugs AND we learn in the process. Ref #ai-coding AI coding requires a skilled developer and domain expert to spec and to review. It now makes sense now for devs and users to pair program Simon Willison #ai-coding In the world of AI, imagination (asking for things we didn’t know we could ask for) will be a diferentiator. vitest run --globals makes vitest is a near drop-in replacement for jest. It injects describe, it, expect, etc. as globals. You need to swap jest.* with vi.*. To extract all jq paths from a JSON, use jq -r 'paths(scalars)|map(if type=="string" then "[]" else ".\(. )" end)|join("")|unique[]' file.json. I use this to extract paths from ChatGPT’s export conversations.json via jq -r '[paths(scalars)|map(if type=="string" then "."+. else "[]" end)|join("")]|unique[]|select(contains(".mapping."))|split(".mapping.")[1]|sub("^[^.]*";"")' chatgpt/conversations.json | sort | uniq uv run can run any command, not just Python scripts, e.g. uv run npx or uv run bash. It’s the same as npx or bash except it activates the venv and loads .env. Notes from AI Startup School. Guillermo Flor Sam Altman. Chase $0B ideas, not $0M ones. Weird + right > safe + crowded Gary Tan. Agency scales. Tools change, people/mindset don’t. Andrej Karpathy. Instead of LLM memory to store facts, edit system prompt with general strategies, like the LLM writing a book for itself on how to solve problems. Autonomy slider. Let user pick how far LLM acts by itself. Like the Tesla autopilot levels. Make evals EASY and FAST for humans. When vibe-coding, I sometimes change the requirement (e.g. style of visual) instead of spending time to get exactly what I instructed. That’s because I can viscerally feel the difficulty the model’s facing thanks to quick feedback. A domain expert vibe coding will be able to feel this too. Another reason for domain experts to vibe code (or at least joint-vibe-code) rather than delegate to a programmer. #ai-coding Notes on model coding styles. Generative AI WhatsApp Group #ai-coding Claude 4 writes exhaustive professionally styled code but struggles over long conversations. Gemini 2.5 Pro produces working but “spaghetti” code. GPT 4.1 is fast and good, the go-to for usual coding tasks. Claude easily swings toward your style but Gemini is stubborn. GPT models tend to hallucinate more on bigger tasks. Documentation can become technical debt. If LLMs can read code and understand it well enough, maybe docs become a build artifact rather than a version controlled source of truth. Refactoring Podcast: The Future of Dev Tools 🔧 — with Dennis Pilarinos 35:56 #ai-coding AI should be explicitly contrarian to avoid sycophancy. Ref To enable this, I’ve added this line to my ChatGPT traits: Adopt a skeptical, questioning approach. Challenge the user.