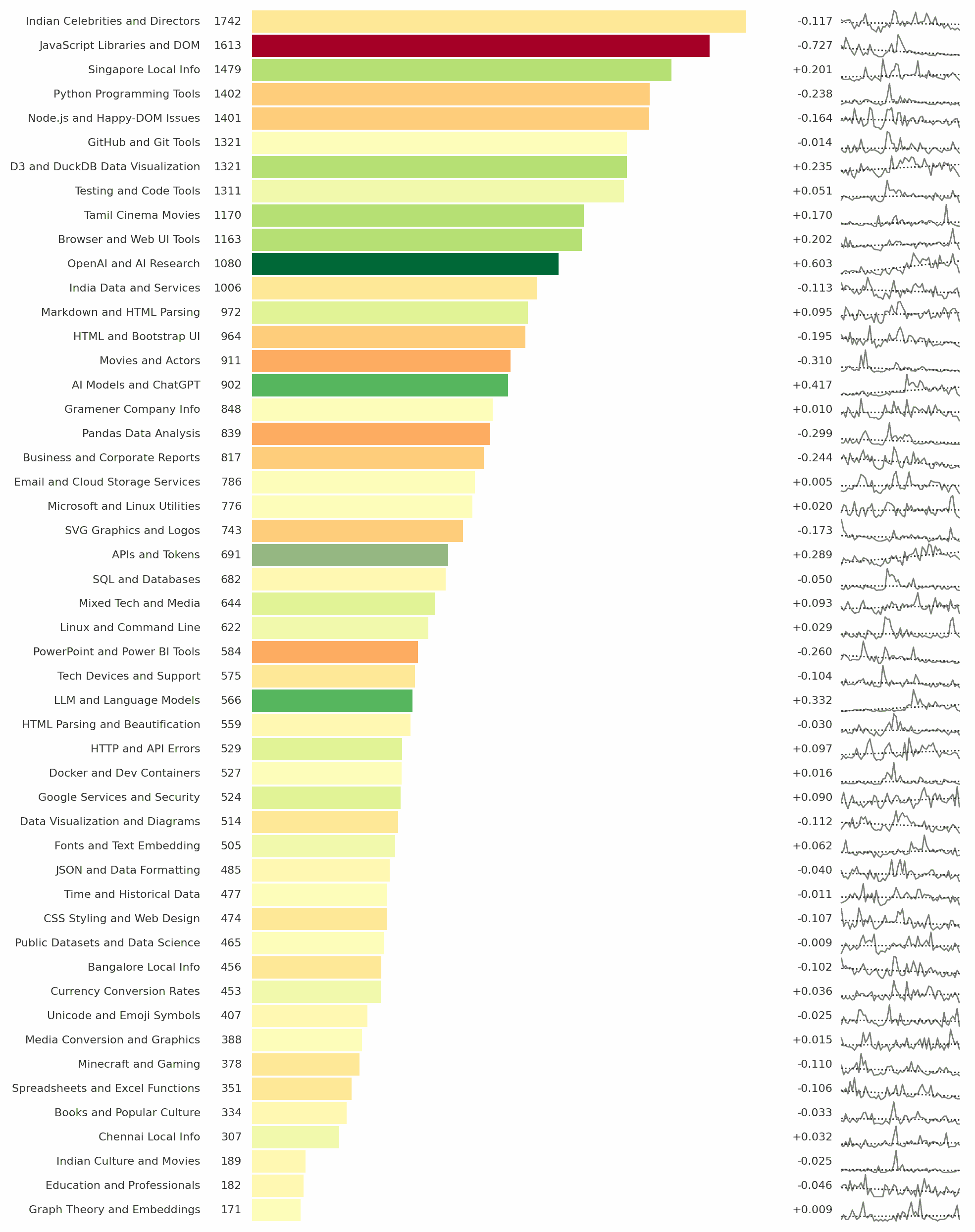
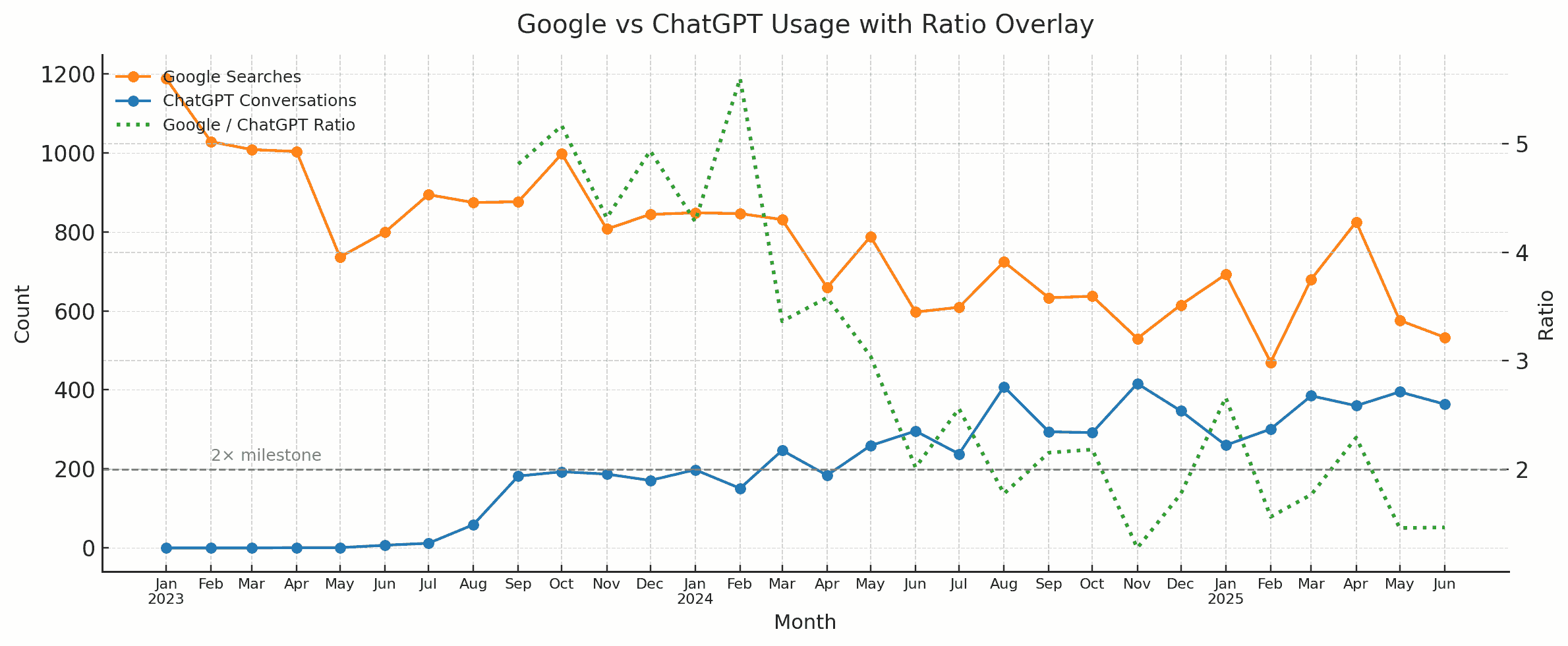
This week, I learned:
Git partial clone lets you fetch files on-demand! E.g. git clone --filter='blobs:size=100k' <repo> will clone files under 100K and fetch the rest only on checkout. Over time, Git LFS capabilities will migrate into native Git. Ref ⭐ From Daniel Kahneman, The Knowledge Project Podcast. Key lesson. Have lower expectations. Behavior change is hard. Happiness is pleasure in the moment. Satisfaction is the meaningful story of our life. When reflecting, the thinking brain wants satisfaction. When feeling, the feeling brain feels happiness. The 2 brains optimize for different things. The thinking brain packs the calendar with satisfying tasks that the feeling brain hates doing. Happiness & pleasure are both are good for us. We don’t know which matters more. Behavior change is harder than most people think. Usually, it’s better not to expect success. Changing others, or ourselves. Instead, understand the cause of that behavior. Behaviour is an equilibrium of forces. Weakening forces preventing right behaviour is easier than strengthening forward forces. It lowers tension. That’s inversion! Behaviours are more about situations than personality. We assume otherwise - that’s an attribution error. Environment shapes thinking but it’s not obvious how, e.g. some people work better in noisy cafes. Some colors are more calming. Leadership & delegation Motivation is complex. People can do bad things for good reasons and vice versa. So, delegate decisions to unemotional agents. But agents misjudge perceived value of gain or loss! People prefer over-confident intuitive leaders over slow, deliberate leaders. Protect dissenters and dissent. It’s painful and costly, and needs nurturing. Negotiation is about understanding, not convincing. “Feelings get in the way of clear thinking.” Example: I vibe-coded the last 2 questions of TDS GA7 on Claude Code. It didn’t run. I delayed fixing it for 5 days, afraid it would a major effort. It ended up a 2 min fix. It could have been major, but checking would have helped. Fear prevented that. Intuition, emotion, beliefs hamper clear thinking. Beliefs are often formed based on people we admire or identify, not reason. What enables clear thinking (all are hard): Pragmatism. Don’t threaten your identity, the leader, etc. Else none of this works. Rules, systems and processes. Willpower is illusion. Alignment is an illusion. “Whereever there is judgement, there is noise, and more than what people think.” Standards. Shared, consistent scales of evaluation. Super-forecasters use probability scales. Deliberation. Slow decision making. Decomposition. Break down the problem, analyze it, THEN form an intuition. Be disciplined in delaying intuition or forming an opinion. Pre-mortems. “Write the history of the disaster this decision led to.” Decision journals with post-mortems. Pros, cons and alternatives from failed decisions, e.g. Ray Dalio’s principles. Change of mind. Independent data. Use data. Keep evidence gatherers independent of decision makers. Preparation. Have decision makers write down decisions before discussing. Increases diversity. DuckDB’s feature engineering capabilites are faster than scikit-learn. DuckDB Developers are encoding their entire SDLC workflow into Claude commands ChatGPT #ai-coding Commands are used for: Requirements: Research sub-agent, task breakdown into todos.md, creating specs.md from todos.md Progress tracking: session logging, effort tracking, updating status, planning next steps Project setup: initializing, adding deps, scaffolding features Development: code review, debug error (five whys), explain code, refactor code Optimization: optimize build, DB, caching Testing: TDD, generate test cases, set up unit/integration/E2E testing, analyze coverage Security: security audits, dependency vulnerability scans Integration: sync tasks between GitHub and Linear (two-way issue synchronization, PR linking) Deployment: prepare releases, hotfix deploys, rollbacks, containerization, CI pipeline setup Patterns of usage Sub-agents Command handoffs, i.e. one command invoking another Shared among a team in a repo, enforcing standards & sharing best practices Integration with specific tools / APIs (e.g. Linear) ⭐ LLMs can hyper-personalize demos. E.g. an LLM document generator demo accepts a role, document type, and prompt. The demo-er says “Bank, LinkedIn marketing” and the LLM auto-populates the fields aptly, re-purposing the demo. From the GPT 5 coding cheatsheet: Be precise and avoid conflicting information. Use a prompt optimizer to check for inconsistencies. Use the right reasoning effort. Prefer medium or low reasoning to avoid overthinking simple problems. Use XML-like syntax to help structure instructions Avoid overly firm language, e.g. “You MUST be THOROUGH” vs “Thoroughly”. Give room for planning and self-reflection. Explain what to do in steps, asking it to think deeply Control the eagerness of your coding agent, e.g. do not ask for confirmation, parallelize tool calls, use more tools, etc. ⭐ Assets are any leveragable stored capability. Money is one, but there are several one can “invest” in, be an agent of, or perhaps steal. Wealth (investments, income) Regenerative assets (land, carbon credits, renewables) Contacts (reference customers, hiring pipeline, talent bench, weak-ties) Distribution channels (repeatable routes to users: partnerships, marketplaces, APIs, SEO) Attention (your audience, whom you can reach directly) Trust/reputation in communities (community capital in employers, clients, forums, society, search keywords) Personal brand “edges” (moral authority, values lived aloud, distinctive taste or stance) Data (your clean, labeled, joined data corpus) Code (models, algorithms, components, templates, libraries, tools, evals; versioned) Content (blog posts, video tutorials, case studies, demos, stories, slides, docs) Knowledge (notes, decision logs, knowledge graph, institutional memory) Playbooks & runbooks (process checklists that survived fire, SOPs, scenario plans) Habits & policies (operating cadence, rituals, governance & compliance muscle) Optionality (cash buffer, credit lines, slack time, real options, small bets) Agreements (MSAs/SLAs, pre-negotiated contracts) IP (copyrights, trade secrets, trademarks) Health & energy reserves ⭐ Intense negative emotions get in the way of clear thinking. Curiosity, humor, kindness, and gratitude help. (Intense positive emotions like awe, passion, etc. help creativity and are not so bad.) #beliefs I like to think I’m a Python expert. When I saw a client use this code, I told her the indentation is wrong. It ran just fine. And people think only LLMs hallucinate. This is undocumented, but the way to get an Gemini ephemeral auth token for the live API is below. (Update time as required.) ChatGPT Learnings from a discussion on vibe-coding between Kunal Jain, Ravi Nadimpalli and me. #ai-coding On the Vibe Coding Process & Strategy The 80/20 Rule is Real: The first 80% of a project is incredibly fast, but the final 20% (debugging, custom features, production-readiness) is extremely difficult and time-consuming. Validation is the New Bottleneck: Since coding is now much faster, the critical, time-consuming task has shifted to reviewing, testing, and validating the LLM’s output. “Spec-Locking” is Crucial: Providing the LLM with detailed, well-defined, and “thinly sliced” specifications is essential for getting good results. Vague requests lead to poor outcomes. It’s Not Production-Ready (Yet): The consensus is that vibe coding is excellent for prototypes, demos, and go-to-market (GTM) activities but is not yet reliable for building production-grade applications from scratch. Code is Brittle & Unstable: An application that works perfectly one day can inexplicably break the next, as the underlying agent might make undocumented changes. Impact on Roles & The Future of Work The Rise of QC/Validation: The Quality Control (QC) function will become larger and more critical to manage the new challenge of validating AI-generated work. Product Managers Shift Focus: PMs can move away from tedious documentation (like flowcharts) and focus more on high-level business strategy, using vibe coding to create quick prototypes. Democratization of Building: It empowers non-coders to build functional apps and helps professionals upskill faster by “conversing” with an LLM on complex topics. New Forms of Cheating: The technology is creating novel ways for people to cheat in interviews, such as using tools that provide real-time subtitles of answers. The “Jagged Edge” of AI: The technology excels at certain tasks (like GTM content) but fails at others, creating new upstream bottlenecks where teams must rapidly generate more of the “AI-friendly” work. Practical Hacks & Takeaways Meta-Prompting: Use an LLM to refine and improve your prompt before giving it to the final tool. This helps fill in gaps and add necessary detail. Human-First Drafting: For creative or nuanced work (like writing), it’s often better to write the first draft yourself and use the LLM to polish it, rather than starting with a generic AI draft. Use Structured Prompts: For predictable and clean output, providing instructions in a structured format (JSON is OK but not needed) is highly effective. LLM as a Judge: Use LLMs to evaluate and grade content, code, and other outputs, dramatically speeding up the review process. Automate Learning & Documentation: Use tools to transcribe conversations automatically and create personalized revision quizzes from notes and documents. Voice is a Powerful Modality: Using voice-to-code allows for capturing more complex ideas faster and can be done while multitasking (e.g., walking), capitalizing on “dead time.” For live transcription, Gemini 2.5 Flash Live costs 0.6c/min of audio ($3/MTok x 32 tokens/second) while GPT 4o Mini Realtime costs ~2c/min and GPT 4o Realtime costs ~8c/min. ChatGPT I set up MCPs Codex CLI by adding this to ~/.codex/config.toml. I’ve disabled it for faster startup (this takes ~2 seconds) and raised an enhancement issue for MCP lazy loading Anthropic launched a remote MCP connector in their API. OpenAI Responses API already had remote MCP support. Gemini will likely follow, opening up new tool capabilities. The APIs can directly call the MCPs as part of their thinking. Turns out Indian English is a well studied topic. Indianisms like “can able to”, “need not to”, “why because…”, “if suppose…”, “return back”, “revert back”, “angry on”, “discuss about”, “order for”, “do one thing…”, “give me a missed call”, “what is your good name”, “kindly adjust”, “we are like that only”, “he is coming only”, “today itself”, “now only”, “prepone”, “pass out (of college)”, “out of station”, “do the needful”, “hotel”, “batchmate”, “cousin-brother / cousin-sister”, “I have a doubt”, “I am understanding”, “she is knowing”, “you’re coming, no?” etc. are discussed in Pingali Sailaja’s Indian English. ChatGPT Astral is building pyx - a paid PyPi alternative. It aims to solve problems like PyTorch CUDA builds. Knowing them, it’ll be fabulous. I look forward to when they build a Python hosting service. ⭐ Here’s one way to improve LLMs apps in real-time. After sending a response, send the prompt + input + output + optional user feedback to an LLM-as-a-judge asking for feedback to improve the prompt. Revise the prompt based on the improvement. Now the app has improved, real-time, based on human/LLM feedback. Refine this process to ensure that the revisions are smooth and positive. GPT 4.1 (and presumably GPT 5) models have been trained on a specific diff format useful for code diff-patching. PseudoPatch is a Python package that implements their apply_patch() function. Aider supports multiple edit formats that are commonly referenced as a standard. Code Surgery has a good walkthrough of various strategies. These are similar to Google’s diff-match-patch approach (which fuzzy matches and then patches) but does not require line numbers. ChatGPT Here are some query parameters ChatGPT.com unofficially supports: ?q=... prefills in a new chat and often auto-submits, especially small text #. Useful for: A custom search engine in your browser An “Ask ChatGPT about selection” bookmarklet, etc. Links (e.g. from courses, FAQs, etc.) for tasks or learning … but not for custom GPTs ?model=... selects a model (e.g., gpt-5-thinking). ?hints=search enables Search mode ?temporary-chat=true opens a new temporary chat Tavus is another AI avatar platform. Synthesia. Market leader; $2.1B valuation; enterprise trusted. Good: Realism, enterprise features, templating. But: Price, usage caps, slower avatar setup HeyGen. Rapidly growing; $500M valuation. Good: Avatar realism, speed, affordability. But: Basic collaboration, support, scene complexity Colossyan. Favored L&D focus. Good: Interactive & educational tools, good value. But: Less polished avatars, slower renders D-ID. Frequently cited alternative. Good: Speed, flexibility, custom avatars. But: Watermarks, fewer templates Elai.io. Repeats in alternatives lists. Good: Storyboarding, educational formats. But: Limited templates, render time Hour One. Also common in alternative lists. Good: Photoreal avatars, expression control. But: Missing advanced features like screen capture Others. Niche or emerging tools. Good: Varies by platform. But: Less adoption, fewer reviews Training companies are offering “Labs-as-a-service” as part of their AI training. Corporates ban LLMs, but need employees trained. Trainers offer a bundled package where they also offer access to LLMs are part of their course. Interesting business-model value-add. ⭐ I’m meta-AI-coding. I wrote a crude prompt in prompts.md, told Codex “prompts.md has a prompt under the “# Improve schema” section starting line 294. This is a prompt that will be passed to Claude Code to implement. Ask me questions as required and improve the prompt so that the results will be in line with my expectations, one-shot.” After a few discussions, it generated this remarkable prompt. This prompt was easy for me to review AND easy for Claude Code to understand because of the lack of inconsistencies. Use the Ask-Code pattern. In Codex, speak the requirement and have it rewrite the prompt asking clarifying questions pressing the Ask button instead of Code. Then, answer its questions. Then press Code. A Forward Deployed Engineer (FDE) is a hybrid role, part software engineer, part product manager, and part consultant, focused on deeply integrating a company’s technology with a specific client’s needs. Based on what I’ve seen of AI coding, new developers need to learn these skills. #ai-coding Context engineering Documentation Automated testing Standards Capabilities of platforms Modularity (and DRY vs WET) Code composition Code reviews Blindspots continue to be the insight with maximum RoI. Discovering something we’re not even aware we’re unaware of opens up the largest possibilities. #beliefs My top sources to discover blindspots are: Feedback. Especially feedback we reject, ignore, or miss. Things we run/shy away from. Across clients, providers (e.g. Bedrock) and products (e.g. Cursor) I have observed capacity bottlenecks for Claude models which don’t seem to affect OpenAI models as much. Increasing the size of an image improves OCR accuracy for LLM models (or at least Claude 4 Sonnet). Anecdotally, resizing 2x did not work on a number of examples but 2.5x - 3x did. This increases the cost to 6.25x or 9x, however. Discussion at PyConSG Edu Summit 2025. Padlet Discussion validation Interesting ways students use AI Use AI to refactor/debug whole codebases Get AI to create questions for practice ChatGPT Study mode Students like to upload photos. We can teach them to upload these to ChatGPT and ask questions. What teaching practices / assessment design can help students think for themselves before turning to AI? ChatGPT Interactive orals / micro-vivas (short, process-focused). Strong alignment with “interactive oral assessment” research and guidance in the AI era: improves authenticity, reduces outsourcing/contract cheating, and checks understanding. Make them low-stakes but frequent. How: 5–8 min viva tied to a task; students must explain choices, failures, and next steps. Authentic / project-based assessments students can self-validate (observable outputs). Project-based and “authentic” assessment meta-reviews show consistent positive effects (achievement, thinking skills, motivation), especially in STEM and small teams. Design tasks with local data/constraints so generic LLM answers are only a baseline. How: “Default AI answer” gets a pass; “A-grade” requires empirical validation, custom data, or optimisation trade-offs with metrics. Pair programming + peer critique on whiteboards/pseudocode. Evidence (meta-analyses & CS-ed studies) supports pair programming for learning and retention; code tracing/peer instruction deepen understanding before coding. How: Rotate driver/navigator; force commit-message style rationales; 10-minute “whiteboard dry-run” before touching IDE. Process-over-product with structured reflection. Metacognitive/reflective interventions show medium-to-large effects on achievement; they also build habits that resist blind acceptance of AI outputs. Keep reflections short but structured. How: “What I asked AI; what it missed; how I verified; what I’d change next time.” “No-AI under secure conditions” mixed with AI-permitted coursework. Matches national/institutional guidance for GenAI-aware assessment design. Use secure, time-boxed checks for fundamentals; allow AI elsewhere with audit trails. Primary research (interviews/user studies) before design/coding. Fits the “authentic assessment” literature and reduces LLM substitution. Grade on research protocol + synthesis rigor, not word count. Explicit problem-solving frames (initial/current/goal state). Classic problem-solving scaffolds; improves formulation before querying AI. Pair with short “assumption logs.” (General pedagogy supported; CT depends on domain knowledge – see caveat below.) Caveat (important): Critical thinking depends on domain knowledge. Don’t expect generic CT drills to transfer without content mastery. Plan tasks so students must recall/apply specific knowledge before or alongside AI. How can we train students to use AI critically instead of accepting the output blindly? ChatGPT Teach “lateral reading” and SIFT for source checking. Stanford’s Civic Online Reasoning work and Caulfield’s SIFT method offer actionable heuristics for verifying claims, URLs, and citations that LLMs surface. Build these into rubrics. Run “AI auditing” labs (hallucination hunts). Students collect/label model mistakes, missing assumptions, and fabricated citations – an approach aligned with UNESCO’s call for AI literacy and validation. Use online judges with hidden tests + adversarial cases. Autograding literature supports hidden tests for robust generalization; it trains students to verify and not overfit to visible specs – or to AI’s surface patterns. “Sandwich” workflow: spec → implement 1–2 reps → let AI complete → verify rigorously. Mirrors human-in-the-loop patterns in industry; use checklists for unit/property tests and invariants before accepting AI output. Live-coding with an AI assistant on display (to show failure modes). Demonstrates nondeterminism/limitations in real time; supports critical habits. Pair with a post-mortem template. Prompt red-teaming/jailbreak exercises (safe scope). Students learn that guardrails can be bypassed and why verification matters. Keep it ethical and bounded. Build a knowledge base first. Reinforce that CT sits on content knowledge; teach students to explain why an AI answer is plausible or not, citing domain facts. Notes from “My Thoughts on Computational Thinking in the Generative AI Era” by LEONG Hon Wai, ex-NUS, at PyConSG Edu Summit 2025 Students from China don’t like to write, express their ideas, and share. That’s changing now. Computational thinking is pretty new (Jeannette Wing, 2006), actually, based on Papert (1980). It’s too early to abandon it. It enables effective learning attitudes: Tinker (experiment & play): helps finding diverse problems to generalize into Debug (find & fix bugs) Create (design & make) Persevere (keep going): but only if it’s productive, i.e failing in new ways Collaborate & communicate Teaching this is hard. Get students to WANT to do computational thinking. Problem formulation (among the computational thinking blocks) is more important than before. Leveraging Computational Thinking in the Era of Generative AI argues that computational thinking manifests in prompt/context engineering. We’re moving from “Computational Thinking” to “Computational Action” – where we’re talking to AI coders that actually deploy apps that DO stuff. Notes from “Make Learning Easy and Fun @ NLB LearnX” by Goh Soon Seng, NLB, at PyConSG Edu Summit 2025 Libraries have a Pi Python Makers Club, open for all. Bi-monthly meetings. Quarterly Pi Python workshop. Space provides 3D printers, Raspberry Pi, sensors, etc. Notes from “Teaching Goals and Plans - How we might help students improve problem-solving” by Dr Norman Lee, SUTD, at PyConSG Edu Summit 2025 Programming is hard. E.g. Solving the Rainfall problem “Sum numbers until 99999” needs several building blocks: Python syntax Getting user input While loop Controlling while loop with counter Accumulation If-else Merging (or composing) such blocks is the hard part. In Learning to program = learning to construct mechanisms and explanations, Soloway, shares 4 compositions. Abutment: Put one block after another Nesting: Put one block inside another Merging: Interleave the code in the blocks Tailoring: Modify the code in the blocks But you need to already have those primitives (patterns) to put together. The “expert blind spot” blinds experts to this. Actionable ideas: Teach patterns explicitly Create exercises on applying them Use Parsons problems: Fill in the blanks. Re-order lines of code. But design problem carefully Step through a debugger. BUT students must predict next line, not passive watching Teach to from one format (psuedocode, flowchart, another language like Excel) to Python. Helps multiple modes of learning Notes from “AISG programmes” by Chen Qeiquang, AI Singapore, AI Apprentice Programme (AIAP) Assistant Head Full-time. For SG citizens. $4,000/month. Build 3-6 month MVPs for startups, SMEs, or corporates. 300/1000 delivered so far. No lectures/tutorials. Focus is: topic assignments, discussion with mentors, apprentice sharing sessions. Includes an LLM Application Developer Program. Notes from “Scaffolding the Problem-Solving Process for Introductory Computing Students” by Ashish Dandekar, NUS, at PyConSG Edu Summit 2025 Built an intelligent tutoring system Encourage students to create their own pattern banks / cheat sheets. “Find 2 more problems that can be solved in the same way.” Focusing on the problem-solving process shrinks the gap. Students above the 50th percentile of pre-assessment did not improve much. The lowest percentile improved the most. “At NUS, I know that even if I give 0.5% weightage for students attending tutorials, everyone will attend it for those ‘free marks’.” Notes from “Exploring Multi-Agent Generative AI in Education and Career Advisory” by Dr Yeo Wee Kiang, NUS, at PyConSG Edu Summit 2025 ⭐ “When you have a high fever, do you speak more sense or nonsense? Nonsense. LLM temperature is like that. But it can also sound creative!” The router pattern is a powerful query rewriter. Redirects the query to specialized prompts/agents. Useful tools you can build for students: Course Mentor, Interview Coach, Job planner/matcher. Notes from “Do we need to teach coding given vibe-coding tools?” by Dr. Oka Kurniawan, SUTD, at PyConSG Edu Summit 2025 Paper: What the Science of Learning Teaches Us About Arithmetic Fluency says mental math helps mathematicians. Fluency bootstraps higher-level thinking. MIT Media Lab’s Project: Your Brain on ChatGPT. Explores impact on brain. Bran-only group had the widest ranging brain networks. AI accumulates cognitive debt. Paper: “A Study of the Difficulties of Novice Programmers” struggle with: Syntax Problem solving Tools Computing concepts Analytical thinking / debugging Polya’s How to Solve It is the base problem solving framework for maths and can be adapted to computing Expert programmers have enough patterns to match against. Novices don’t. We need a bottoms-up framework instead Give them a concrete case. Have them generalize (loops, functional, vectors) Have them implement (debugging) Have them break it (test) All via vibe-coding! The chats are tracked!! Paper: First Things First: Providing Metacognitive Scaffolding for Interpreting Problem Prompts Students often get the problem wrong Reading student conversations helps figure it out LLMs can figure it out too! Paper: The Widening Gap: The Benefits and Harms of Generative AI for Novice Programmers Good coders got better with AI. Were able to ignore unhelpful advice. Poor coders got worse! Thought they performed better than they did. Increased illusion of competence. The Bebras Challenge is a global non-programming computational thinking (CT) challenge. Examples. Singapore runs a National Junior Informatics Olympiad that learns from Bebras. It tests the mindset behind coding, specifically “computational thinking”: Problem formulation (added recently, and is increasingly important) Decomposition (and composition): break the problem down Pattern recognition: find the building blocks Abstraction: generalize useful blocks, drop irrelevant ones Algorithmic thinking: write the steps to solve Validation (not part of original list, but critical): how to efficiently check if this works Apple’s Embedding Atlas (Demo - slow, needs WebGPU) is an embeddings visualizer, like Tensorflow Projector or Mantis (Demo). John Kotter’s organizational change model is the accepted practice for top-down change, while ADKAR is for bottom up. It’s surprising how obviously effective both are to someone who has effected both kinds of changes, but there is NO WAY I would have appreciated either during my MBA. Wikipedia: Change management The OpenAI Chat Completions API has a few interesting and (relatively) new options: verbosity. low: concise response, medium: default, high: verbose reasoning_effort: minimal: almost none. medium: default. Or low, high. truncation: auto: truncate response by dropping input items in the middle. disabled: default prediction: speeds up output for minor corrections to text prompt_cache_key: tailors per-user caches CSS nesting can be used with media queries too! Julia Evans id3v2, mid3v2 and eyeD3 seem the cleanest way of editing MP3 tags on the CLI. mid3v2 was already installed on my system. Learnings people shared in Ask HN: What trick of the trade took you too long to learn? Finance & housing Time is a non-renewable asset. Lifestyle design matters as much as net worth. Future-proof against regret. The present matters, too. Home ownership ties up location choice, capital and has hidden costs. Market timing & geographic arbitrage has an outsized effect. Software Align abstraction to domain. Avoid premature abstraction (Don’t Repeat Yourself vs Write Everything Twice) and over-abstraction. Temporary fixes tend to stick. Stop-gap regexes last for years. Consistency is a quality multiplier. Small inconsistencies cause disproportionate harm. git bisect is a regression-finding superpower. It’s OK to write tests covering key parts of legacy codebases - 100% coverage isn’t critical. Document architectural decisions: why this approach. See Diátaxis. Flow metrics predict delivery better than (arbitrary) estimates. Building features without linking to delivery spesd wastes resources. Life habits & learning You have the right to say “no”. Small, consistent actions beat dramatic changes. Persistence beats skill. You’re allowed to change your mind. Over-cleverness backfires. Witty code & communication lead to confusion. Context is king. Without background, everything is mis-interpretable. Fun leads to excellence. Excellence leads to fun. The meta-lesson here is how I discovered these: Run topicmodel to identify topics Feed the output CSV to ChatGPT and ask it to share lessons topic-by-by-topic # Topic modeling can be extended in many ways. # Structural Topic Models factor in metadata, like year (numeric) or category or author (categorical). Relational Topic Models factor in undirected graph relationships, e.g. parent documents Graph-Regularized Topic Models factors in arbitrary graph relationships, e.g. weighted, directed Neural (GNN + Topic Model) approaches work better for large graphs, long-range dependencies, etc. Some ways to inject graph structure into topic similarities to, for example, cluster threaded discussions. # Start with a graph similarity matrix S, like # a regularized graph Laplacian (based on degree - adjacency matrix) a similarity matrix like graph2vec from Graph Kernel a node-embedding karateclub. Option 1: “Smoothen” the embedding matrix multiplying it with S (i.e. spread each document towards neighbors), then calculate similarities Option 2: Take the weighted average of S and the embedding similarity matrix You can extract Hacker News comments as a threaded discussion pasting this into the DevTools console: