This week, I learned:
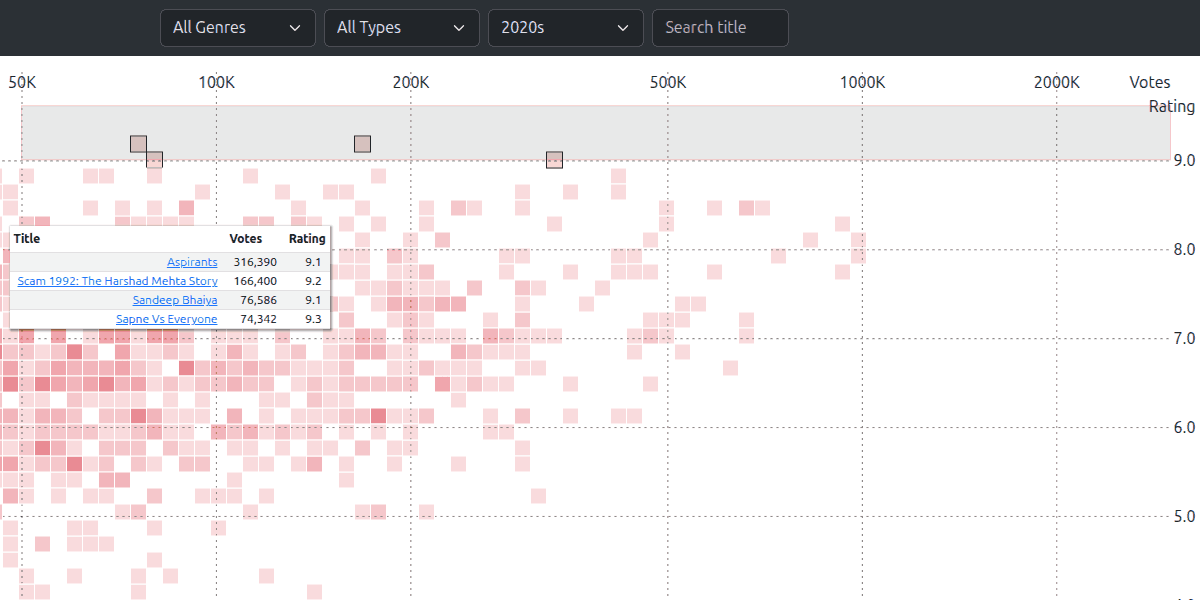
Android screen recorder is the easiest way to record phone and WhatsApp calls. But that won’t work for Google Meet, Teams, Zoom, etc. Gemini exiftool remains the best media metadata extractor (music, images, …) though it’s old, slow, and Perl-based. exiftool -csv -r ~/Music/ > music.csv exports all metadata as CSV. Installing the source via https://sourceforge.net/projects/exiftool/files/latest/download seems best. It’s a good alternative to mp3tag / puddletag UI-based exports. ChatGPT Gemini ⭐ Some questions are for us to learn. Some are Socratic, and meant for the answerer to learn. When working with AI agents and interns, I find myself asking them several questions that I don’t want to know the answer for, but is important for them along their journey. Roughly the equivalent of “Think step by step” converted into the Socratic method. For example: Instead of “Build a demo for this client”, ask “Who is the audience? What’s their objective?” and THEN ask for a demo. Instead of “Generate a dummy dataset for X”, ask “What interesting insights would we want when analyzing X?” and THEN ask for a dataset. Instead of “Write this code”, ask “What’s the best architecture for this?” and THEN ask for code. Executable Markdown files with Unix pipes sounds like a clever idea. Prefix Markdown files with #!/usr/bin/env codex (or claude -p). Then, just write programs by describing them. Quotes from Isles of the Emberdark: Really, he should have known better than to punch a senator. Important people had underlings you punched on their behalf, and he should have found one of those. ChatGPT Canvas has a cool feature for editing documents or code. Just select a portion, ask for changes, and it edits it. Importantly, it’s very fast. Greeking Out is a kid-friendly National Geographic podcast about ancient Greece and its influence on modern life. fly.io containers at sprites.dev seem impressive. You can SSH into them. They have public & private HTTPS URLs. It auto-sleeps after 30s. You can checkpoint any time and restore the ENTIRE system. It’s FAST! This is great for agents. Just install Claude Code / Codex and other tools. Checkpoint it. Then ssh into it and use as required. The cost is typically ~12c/hour - which is expensive to run forever but great for bursts. Simon Willison I’m seeing the Collider Bias in action (on a small sample). The developers who can communicate well don’t code as well, and vice versa. Not because there’s a negative correlation - but because I’m eliminating people who can neither code nor communicate. But interestingly, over a 1-3 month horizon, the ones who code start communicating much better but the ones who communicate well don’t start coding much better. My theory is that the developers I work are communication-bottlenecked (e.g. lack of confidence) than unskilled (e.g. poor communicators). Prefer Zod for TypeScript validation and Ajv for schema validation. Typing has a lot of value, but don’t overdo it. It’s best used at fragile boundaries. ChatGPT ⭐ Notes from LLM poetry and the “greatness” question: Gwern follows this process to create good poetry. It’s a good structure for ANY kind of expert workflow with LLMs today: Analyze the style, content, and intent of the original. Brainstorm 10+ different directions the poem could go. Emphasize diversity. Critique each direction. Rate 1-5 stars. Write the best one. Critique and edit line by line. Generate a new clean draft. Repeat at least twice. Print final version. “As a poet and scholar of poetry I feel comfortable arguing that Gwern’s work engineering prompts is, in effect, writing poetry.” Mercor uses expert poets to creates rubric. Models generate poem that experts grades, which refines the rubric, which trains the model. But models tend to the mean and need nudges (from humans?) to surface outliers and ascribe meaning (uniquely human?), which is where greatness lies. Ethan Mollick: “I keep warning that so many of our systems are still built around the assumption that quality writing and analysis are costly and therefore meaningful signals. Our systems are very much not ready for the revelation that this is no longer true, as this planning objection AI shows.” Basically, AI lowers the cost of Government and Corporate interactions. It’d be a cool hack to agent-ify these to death, i.e. do all kinds of Government / Corporate interactions that were painful earlier, but now are much easier. I just realized: “Will AI take my job?” is a variant of “Will immigrants take my job?” or “Will affirmative action take my job?” Any increase in labor capacity is a threat. But then, the only way to get promoted is if someone takes your job. So, maybe we should ask: “How do I become their boss?” Better yet, tell your boss “I created a 4-agent team and got 2X done. Give me a new title.” Some simple yet powerful AI adoption principles from Will Larson - that I’ve seen work rather well: Make tools accessible Document tips & tricks Highlight how people (especially senior leaders) are using it An analysis of 1,250 Claude user interviews indicates that: Adoption of Creatives > Workforce > Scientists. Interestingly, the identity threat and guilt of Creatives > Workforce > Scientists! Creatives they feel they’re cheating, lazy, or not adding value! Scientists use it less, but it’s more a tool and THEY verify. Sceptical verification is the strongest thread. Mintlify is proposing .well-known/skills/ as the directory to store LLM skills sites want to publish. This could be an extension of the llms.txt mechanism. Open Responses is the open version of OpenAI’s Responses API. OpenRouter and HuggingFace support is a big deal, and though Google, Anthropic, Meta etc. don’t yet support it, they might. Restish converts OpenAPI specs into CLI tools - with shell completion. Combined with an OAuth CLI like oauth2c this is a great way to conert APIs to CLI commands. Via Vercel’s agent-browser seems a good CLI choice for browser automation, alongside playwright-cli. It may be work switching from direct Playwright coding (on CDP). ChatGPT Capturing actions using HAR and passing it to LLMs seems like another clever way of using AI coding agents for browser automation. Via Open a browser. Open Devtools > Network and filter to HTML, XHR, WS, Other. Do what you want to automate, i.e. load LinkedIn, search, scroll, fetch next pages, etc. Devtools > Network > right click > “Save All As HAR”. Run the file through a HAR-sanitizer Prompt: “Create a Python client to automate the actions I captured in file.har". When any AI coding agent can build apps, value will probably migrate away from software to data, network (distribution and users), trust, taste, and physical goods. Owning these controls value. Also, infrastructure to run vibe-coded apps (e.g. auth, hosting, DB, LLM APIs, etc. bundled) will likely lead to Medium / WordPress like platforms. After 30 years of learning (and teaching) statistics, I finally found a good explanation of R². R²=80% means that ~80% of the change is because of the other variable. Gemini ⭐ People think numbers create trust; often they create attack surfaces. Goodhart’s Law: “When a measure becomes a target, it ceases to be a good measure.” By providing a number, you invite people to “game” the system or find the flaws in how that number was manufactured. The Precision Trap: While precise numbers can increase perceived credibility initially, they also lead to “anchoring.” If the number is even slightly off, the entire foundation of trust collapses more violently than it would for a general estimate. Statistical Literacy Gap: Most people don’t argue with “vibes,” but many will argue with “averages” if their personal experience represents an outlier. The number creates a surface for anecdotal rebuttal. Eraser.io offers an AI architecture diagram generator that creates reasonable architectures. It uses its own diagram-as-code DSL, competing with D2, PlantUML, Mermaid, Exposing your workflow as a software interface productizes services businesses. For example, my auditors and immigration lawyers have portals where I can fill out forms, upload documents, see my status, etc. This standardizes their delivery, and creates a “product” moat. ⭐ Your “villains” or enemies are often alternatives/backups that have a role in the ecosystem, offering diversity/resilience when you’re wrong. Create roles and incentives for them rather than eliminating them. For example: Don’t make LLMs do all the work. Create a role for the clunky SQL whose resilience saves the day when LLMs hallucinate. Make the person who hates your prototype the Red Team Lead - to catch the flaws you miss. Make the people who reject your product the scouts / innovators - to find alternatives you miss. Neon.com is like Supabase but without auth, functions, etc. It’s just Postgres as a service. An alternative for prototypes (that I haven’t tried yet.) ChatGPT SuperTokens is an open-source self-hosted auth service that I’m hearing about more often, but haven’t tested. Seems to be ahead of alternatives like Auth.js / Better Auth. ChatGPT Bollywood Falls Out Of Love is a great visual data story on The Kontinentalist by Surbhi about the decline of romance and growth of nationalism on bollywood genres. Recharts is a React charting library with some slick capabilities like brushing, customizable tooltips, and bar chart races. Via Rukmini - Data for India Qwen3 TTS is impressive. It voice-clones, streams, and the tone/style can be controlled via prompts. The model is small. I ran it locally without flash-attn (which I couldn’t get to work) and took ~14 seconds to generate an audio file for 10 words on my GPU machine. Environment setup: uv venv --python 3.12 UV_TORCH_BACKEND=auto uv pip install -U qwen-tts DeepSeek created an external memory system for LLMs that lets them look up (instead of computing to remember) knowledge. That means CPU RAM can be used instead of GPU, models can become smaller, and training can become faster. This looks like an example of how algorithms/ideas can continue the scaling laws. Gemini via Jeremy Howard