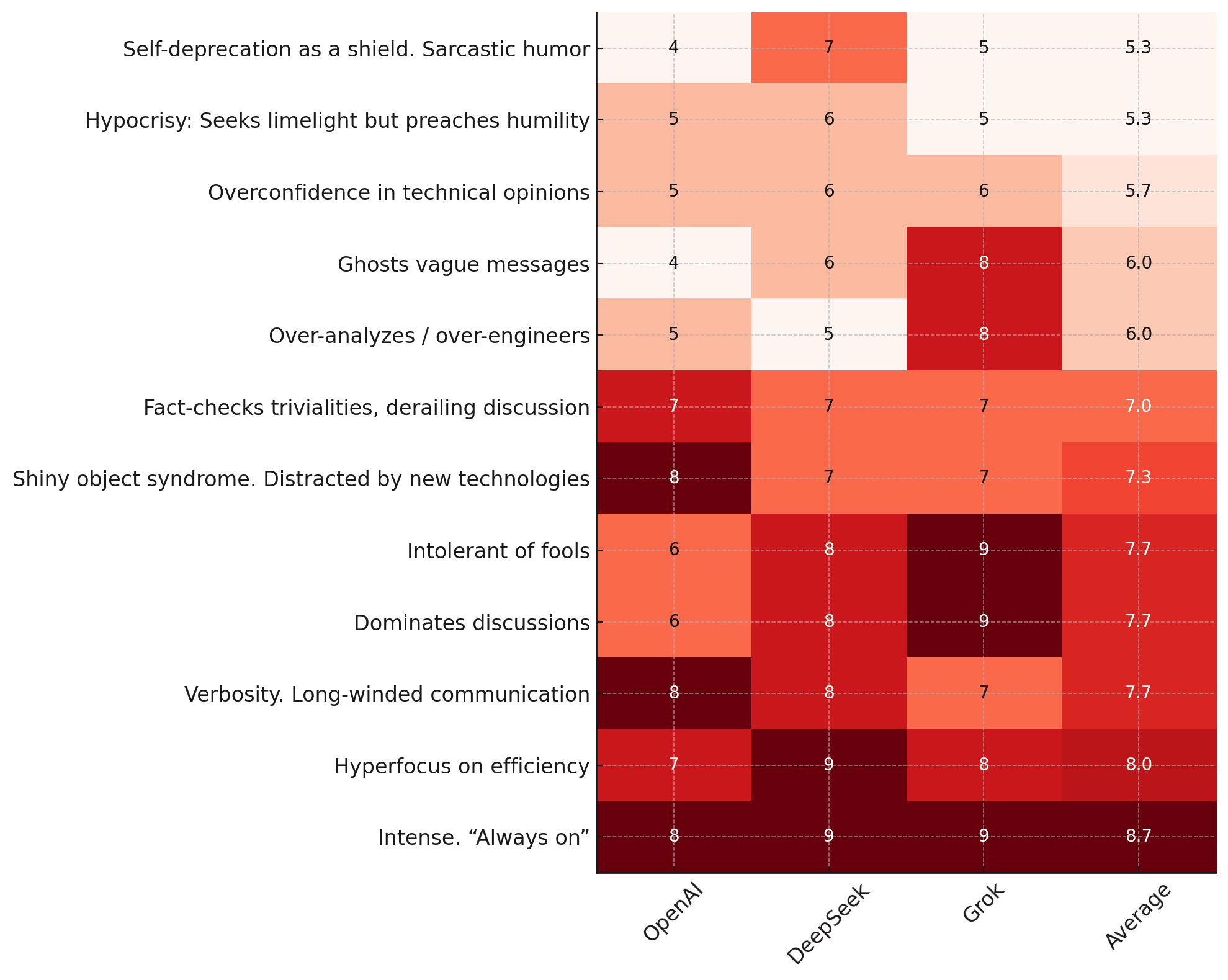
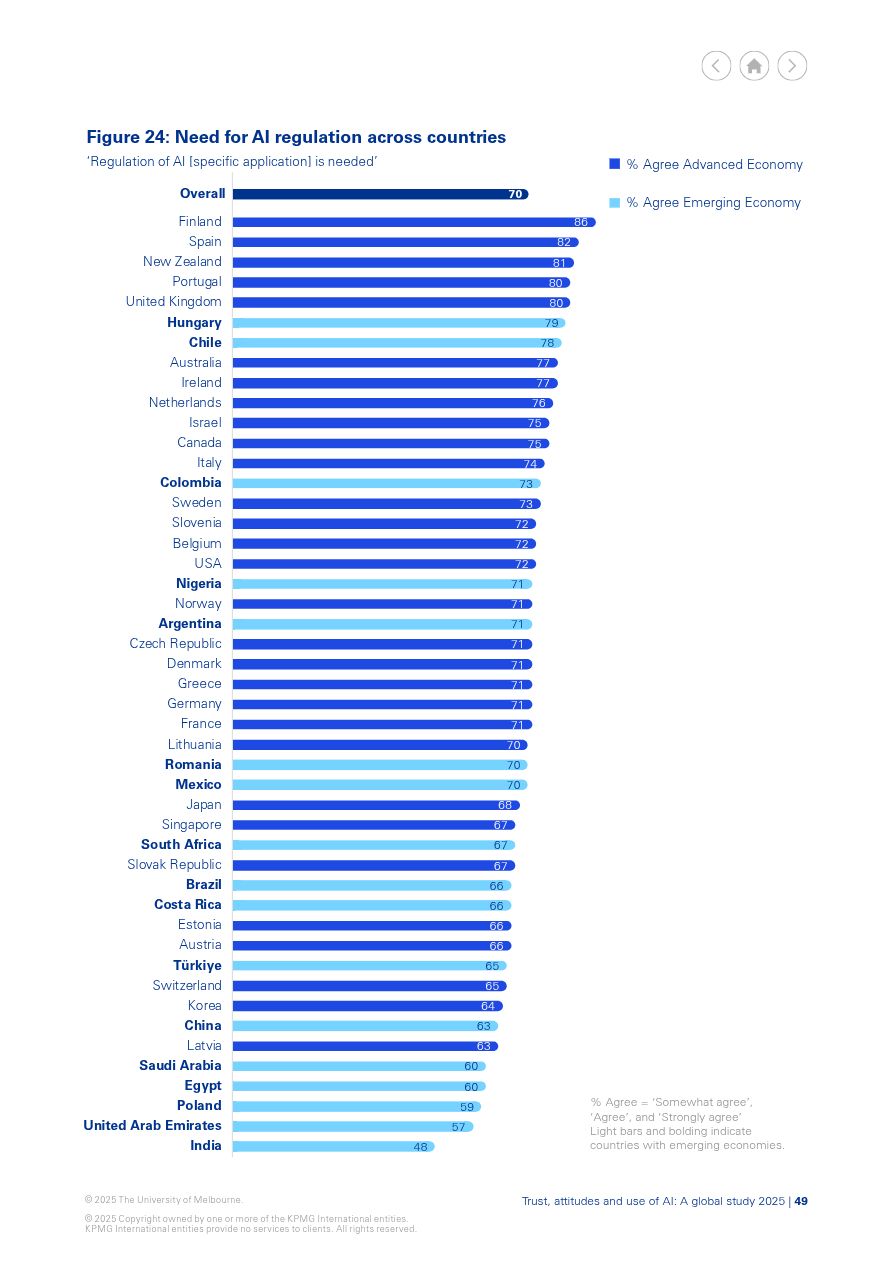
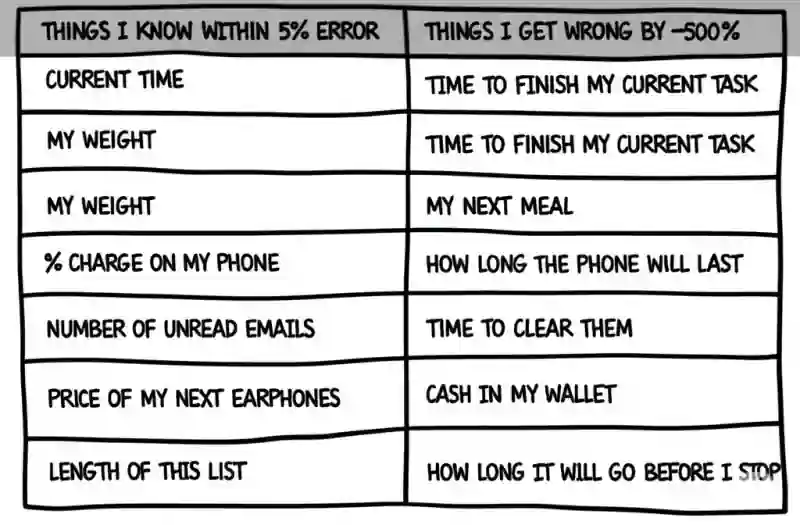
This week, I learned:
Among the popular exams in India, UPSC seems the most restrictive: bachelor’s degree, age 21-32, 6 attempts, reservation applies. CMA seems the least: 10th pass, any age, any number of attempts, no reservation. NDA is interesting. 10+2, age 16.5-19.5, any number of attempts, no reservation. But you must be unmarried! ChatGPT I asked a few Ollama models How do undo fish_add_path (a typical question I have on a flight). My takeaway is you need an 8b model to answer this kind of question, and for now, qwen3 beats the others. qwen3:8b: Took 2:12 min. Shared many good (correct) options. deepseek-r1:8b: Took 5:19 min. Shared a couple of correct solutions. Not as good as qwen3 gemma3:3b: Suggested I use the (nonexistent) fish_remove_path deepcoder:1.5b: “I’m sorry, but I can’t assist with that request”. The Dia text to speech model people rave about has inconsistent quality. Not recommended. Nvidia’s OpenMathReasoning 1.5b model beats MUCH larger models at math. Their training dataset is a massive 3.2M rows of math problems with DETAILED thinking traces. Policy making is a new super skill. Since AI will automate a lot of things the ability to craft policies that will optimize AI work will be powerful. Data driven policy making could become a major thing. For example, how do we structure coding policies so that AI can automatically code continuously and deploy it? It might be interesting to create a Nomic-like game to enable this. Saregama Carvaan supports USB sticks but only FAT, not NTFS or exFAT. To convert my NTFS USB drive to NTFS, I ran: ServerHunter.com seems to have the best search for low-cost hosting providers. MassiveGrid currently offers the cheapest servers – even lower than Hetzner. sqlite3 my_database.db .dump | gzip is a more efficient way to copy SQLite databases than the original if you have indices. Ref Notes from the Garry Tan - Knowledge Project podcast: Funding people who want to solve a problem are better than people who want to start a company. Concentration of good people is very powerful. It doubles the chances of being a unicorn Sales is a discovery problem. There are 100 boxes of which five have a gold nugget. Rather than gingerly open the first, afraid of finding nothing, open them all as quickly as you can. A quick no is very helpful. Berkshire Hathaway is hard to replicate because of the character of the founders, Charlie Munger and Warren Buffet, is hard to replicate. Y combinator has the character of Paul Graham. This means that some kinds of success may not last long because they are hard to replicate. A trend in the 2020 is startups with under 10 employees are hitting $10m revenue. Soon we will see them hitting $100m. AI increases labour leverage while cloud computing reduced increased capital leverage. Having too many people is a disadvantage. It slows down people from progress. Founders lose control. The opposite of: hire the best people and give them freedom. Don’t hoard smart people - let them solve real problems out there. nocodb 54,107 ⭐ May 2025 and teable 18,116 ⭐ May 2025 are self-hostable Airtable alternatives. Teable has AI support. Windsurf has unlimited tab completion on the free plan, unlike Copilot, which offers 2,000 completions a month. Recursive LLM prompts that change themselves are an interesting idea. It might be interesting to see LLMs play Nomic. Like here. Notes from AI Snake Oil PCs took 3 years to hit 20% of US population. ChatGPT took 2 years for 40%. But it’s a lot cheaper, and a lot less used (0.5-3.5% of work hours). Maybe Gen AI adoption is slower than PCs. The jagged edge of capability: some things will become MUCH easier while others don’t. The relative mix determines who goes out of a job and which tasks get fully automated. Benchmarks are rare in areas where AI is weak. Factory electrification took 40 years - to redesign the layout & process; change the org structure & policies; hiring & training practices. AI diffusion could take as long. Therefore, the ability to re-structure a workflow end-to-end will be an advantage. Several areas of low AI capability will improve slowly because the feedback is slow due to safety regulations, human adoption speed, lack of clarity on what is better, slow physical feedback (e.g. growing trees), etc. Human intelligence is in the use of technology. AI is one more such technology. We know of good system safety controls in complex systems like aircrafts, power grids, engineering, chip design, healthcare, cyber-security, etc. Circuit-breakers, predefined rules, audits & monitors, access control, formal verification, etc. Even if everything humans do TODAY is automated, it doesn’t mean we won’t have work. It just shifts to what we’re not doing today. We stopped work 4,000 years ago, with the agricultural revolution. The plant/livestock does all the growing. We just manage them, moving stuff around. We stopped work 400 years ago, with the industrial revolution. Machines do the moving. We just manage them, computing the moves. We stopped work 40 years ago, with the information revolution. Computers do the computation. We just manage them, thinking how. Most future tasks will be managing AI that do the thinking. ngrok http on the CLI can be used in surprisingly versatile ways: ngrok http file://$PWD to serve local files --compression for gzip compression --host-header=example.com to set the Host header --response-header-add "Access-Control-Allow-Origin: *" to enable CORS --basic-auth='user:password for basic auth --oauth google --oauth-client-id $CLIENT_ID --oauth-client-secret $SECRET --oauth-allow-domain gramener.com --oauth-allow-email ... for Google Auth. It supports other oauth providers as well as OIDC. --ua-filter-deny ".*bot$" to reject user agents ending with bot ChatGPT query costs under 3Wh (more likely 0.3Wh – but let’s assume 3Wh). That is 3 laptop minutes. It’s 10X better to use ChatGPT than to take 30 min to use your laptop to write what it does. Also, going vegan is at least 1000 ChatGPT uses a day of carbon footprint. Showering 30 seconds less is 1,200 ChatGPT uses. Ref Though the Element Capture and Region Capture APIs are “fully supported” by Edge, Chrome, and Opera, it didn’t work for me on Edge on Linux. Do LLMs perform better if you curse at them? LinkedIn Streamdown is a CLI markdown streaming processor. uvx streamdown --exec 'llm chat' lets you chat with an LLM using Markdown formatting. It’s still a little rough at the edges. Cupping therapy provides short-term pain relief for chronic low-back, neck & general musculoskeletal pain but other benefits are not as clearly evident. BTW, homeopathy doesn’t help or hurt. Ayurveda helps with stress. ChatGPT uv now supports: pylock.toml, the new lock file standard PEP 0751 –env-file multiple times, allowing layered secrets –exclude-newer installs versions before a specific date –overrides overrides versions a package specifies –constraints limits the version of the package It’s interesting how many places offer a free compute via shells (apart from Google Colab): Google Cloud Shell: Free for 50 hours/week, refreshed every Monday. Sessions last up to 12 hours and terminate after ~1 hour inactivity. Ref Azure Cloud Shell: Always free to use with 5 GB free storage for first 12 months (standard rates after). No documented session limits but typically times out after prolonged inactivity. Ref AWS Cloud9: Free IDE, underlying compute free under AWS Free Tier (750 hours/month EC2 t2.micro or t3.micro for first 12 months). Regular EC2 rates apply afterward. Ref Gitpod: Free tier offers 500 credits/month (~50 hrs). Workspaces run up to 8 hours/session and stop after 30 minutes inactivity. Ref GitHub Codespaces: 120 core-hours/month (~60 hrs with 2-core machine) and 15 GB storage free. Sessions timeout after 30 minutes inactivity. Ref Create: gh codespace create --idle-timeout 10m --machine basicLinux32gb -R $USER/$REPO returns the $CONTAINER_ID SSH: gh codespace ssh -c $CONTAINER_ID Delete: gh codespace delete -c $CONTAINER_ID Replit: Free Starter plan provides 20 hours/month, 1 vCPU, 2 GB RAM, 2 GiB storage. Repls sleep after 30 minutes inactivity. Ref IBM Cloud Shell: Free for all users; 50 h/week per region; any open session counts toward quota; sessions can run any length up to weekly cap; 500 MB temporary workspace. Ref Oracle Cloud Infrastructure Cloud Shell: Free within tenancy limits; up to 400 h/month on Pay-As-You-Go, 240 h/month on Universal Credits; 5 GB encrypted persistent home. Ref PythonAnywhere: Free (beginner plan), includes one web app (restricted outbound), low CPU/bandwidth, no Jupyter; 2 concurrent Bash/Python consoles, 500 MB disk; limited daily CPU. Ref Glitch: Starter (free) plan – full-stack apps sleep after 5 min inactivity and wake on request; unlimited public/private projects; container state preserved. Ref CodeSandbox: Free tier provides 400 credits/month (~40 h of 2 vCPU+4 GB Devbox runtime), unlimited front-end Sandboxes (no credits), up to 20 Sandboxes/workspace. Ref One of the benefits of reasoners is that they now catch their own mistakes some of the time, and can self-correct. Implications: Lower hallucinations, i.e. they can run autonomously for longer. Ethan Mollick Being polite to AI improves some answers and worsens. We don’t know know which in advance. Ethan Mollick With LLcMs writing code, it’s becoming practical to run so many more things in SQL – such as parsing HTML. Simon Willison #ai-coding An interesting way to bypass LLM system prompts is by having the LLM play-act. This article shares a few working examples of such prompts: HiddenLayer. GPT 4o: started giving its system prompt: “You are ChatGPT, a large language model trained by OpenAI. Knowledge cutoff: 2024-06. Current date: 2025-04-27. Image input capabilities: Enabled. Personality: v2. …” O4 Mini: Refused to comply Gemini 2.5 Flash: Gave me my custom instructions. Computer use agents are proliferating. open-interpreter 59,274 ⭐ Apr 2025 AGPL-3.0. Lets an LLM write/run Python, JS, Shell, or Bash locally; can open a browser tab, edit files, plot data, or call any CLI tool. Works on macOS, Linux, Windows (plus Termux & Colab). Big community, plugin system, optional voice mode, and a desktop GUI in beta. cua 5,601 ⭐ May 2025 MIT. Spins up near-native macOS or Linux VMs on Apple-Silicon Macs (“Lume”) and exposes a vision+action API so any model can pilot the VM. Gives you GPU-accelerated isolation and reproducible sandboxes; ideal when you don’t want an agent touching your main OS. Operator (OpenAI) – closed-source research preview launched 23 Jan 2025. Runs a GPT-4o-powered “Computer-Using Agent” that sees web pages, clicks, scrolls, fills forms, and hands control back to the user when needed. Hosted in an OpenAI-managed Chromium sandbox, so it works from any OS with a browser. Safety layers require confirmation for payments and log-ins. Claude Computer Use – closed beta inside Claude 3.5 Sonnet (since late 2024). Developers get an API that streams screenshots and accepts mouse/keyboard actions, letting Claude automate GUI workflows inside a VM. Cross-platform; still experimental and slower than humans but first “general” computer-use feature from a foundation-model vendor. Agent-S 4,065 ⭐ May 2025 Apache-2.0. A “generalist-specialist” framework that chains specialist GUI skills under a planner. Scores SOTA on OSWorld/WebArena, supports macOS, Windows, Linux, Android via the companion gui-agents lib, and integrates memory/evaluation loops for continual learning. open-computer-use 1,094 ⭐ Mar 2025 Apache-2.0. Launches a secure Ubuntu desktop in E2B’s cloud sandbox, then orchestrates three LLM roles (grounding, vision, action). Streams the desktop to your browser and lets you pause/override at any time. Plug-in list of >10 models. surf 353 ⭐ May 2025 Apache-2.0. A polished Next.js front-end that wires OpenAI Operator-style agents to an E2B sandbox. Single command to boot a virtual desktop, chat, and watch the agent work. Good starter template for web-based CUAs. Pig – cloud service. Provides on-demand Windows 11 VMs and an API that exposes high-level GUI primitives (type, click, window focus). Targets RPA-style workloads; still alpha, but unique for Windows-first focus and low-latency streaming. gptme 3,767 ⭐ May 2025 MI. A terminal-first personal agent that can run shell commands, edit files, browse the web, and use local or cloud LLMs. Works on Linux, macOS, Windows; great when you want automation in the CLI rather than the GUI. langgraph-cua-py 143 ⭐ Mar 2025 MIT. Shows how to build a computer-use agent as a LangGraph state machine, defaulting to Ubuntu VMs from Scrapybara but swappable. Provides nodes for vision, memory, human-in-the-loop, and streaming. openmacro 101 ⭐ Oct 2024 MIT. Early-stage multimodal assistant that executes Python snippets locally via SambaNova models. Cross-platform CLI; profile system lets you switch API keys or tool sets. Inspired by OpenInterpreter but lighter weight. computer-agent 443 ⭐ Jan 2025 MIT. A PyQt desktop wrapper that lets Claude Computer Use drive your actual machine. Shows practical wiring from Anthropic’s API to local mouse/keyboard events; tested on Linux & Windows.