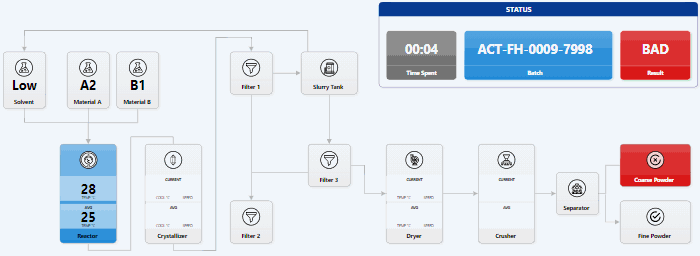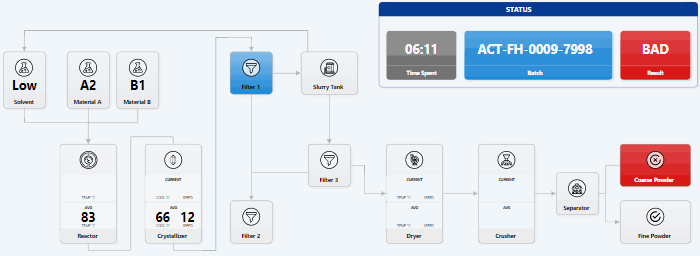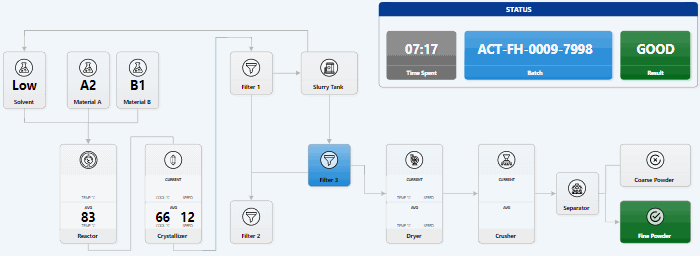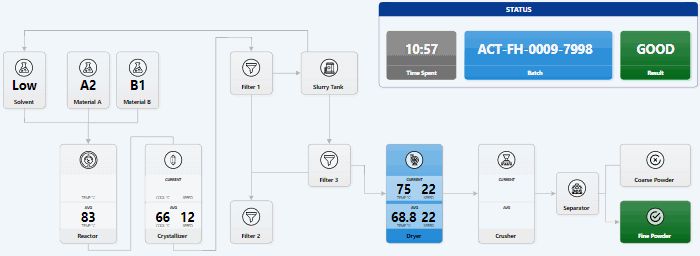
How to Visualize Data Stories with AI: Lessons
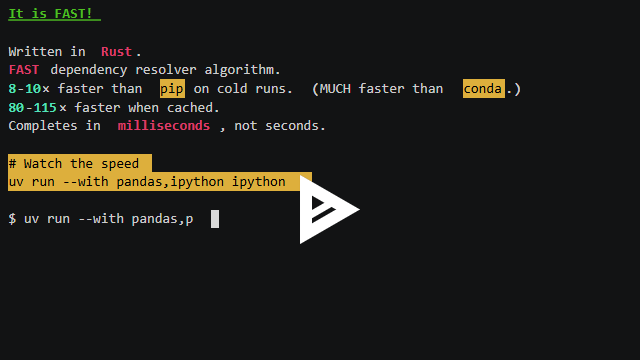
I tried 2 experiments. Can I code a visual data story only using LLMs? Does this make me faster? How much? Has GitHub Copilot caught up with Cursor? How far behind is it? Can I recommend it? So I built a visual story for Lech Mazur’s elimination game benchmark (it’s like LLMs playing Survivor) using only the free GitHub Copilot as the AI code editor. SUMMARY: using LLMs and AI code editors make me a bit faster. It took me 7 hours instead of 10-12. But more importantly: ...