How isolated is Bollywood from world cinema?
These are the major group actors based on who they act with most.

- Language. Not country. For example, the Spanish / Mexican group is across countries. But Indian actors divide into North Indian and South Indian. It’s language, not country.
- Time period. Old American actors are a separate group from Hollywood. (Naturally. Brad Pitt was born after Humphrey Bogart died. They couldn’t have acted together.)
- Genre. Hollywood Porn actors don’t act with mainstream Hollywood. Same with Japanese Porn, Hollywood TV, and Hollywood Horror actors.
How are these groups themselves connected? Do Chinese actors act with Hollywood often? How isolated is Bollywood from world cinema?
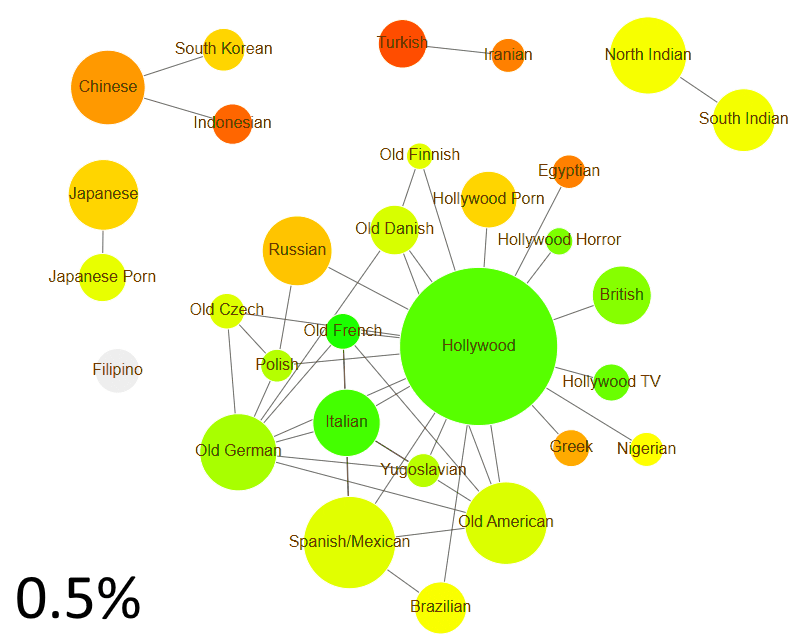
Hollywood is the core group
Take groups that act with other groups at least 5% of the time. Mainstream Hollywood acts with British and Hollywood TV/Horror actors. All other clusters are isolated.
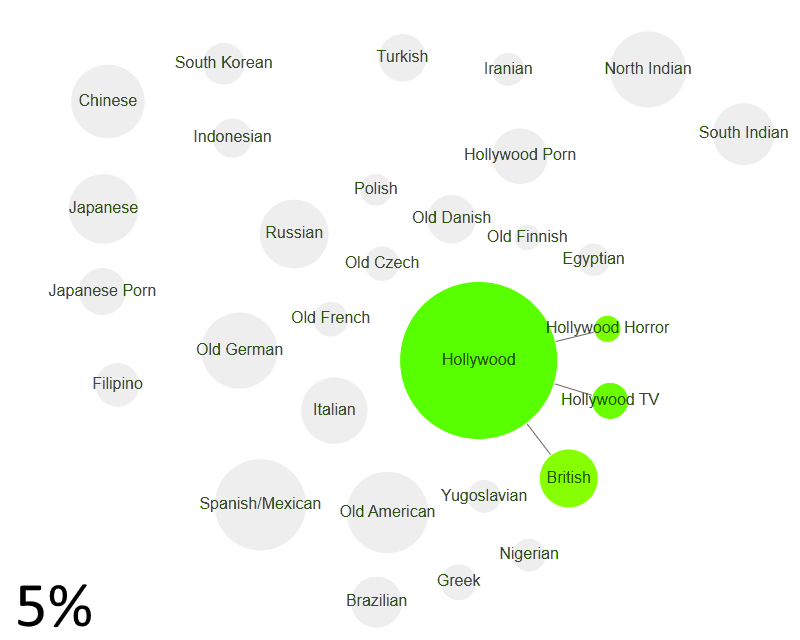
Indian & Japanese clusters emerge
Let’s go more liberal. Take groups that act with other groups at least 2% of the time. Hollywood forms a big connected cluster. It includes most of Europe — British, German, French, Czech, Yugoslavian & Italian actors.
North & South Indian actors form the first non-Hollywood cross-language cluster.
The Japanese and Japanese porn actors form a cluster too. (Interestingly, it’s easy for a Japanese porn actor to act with mainstream Japanese actors. Hollywood porn actors find it far harder to act with Hollywood.)
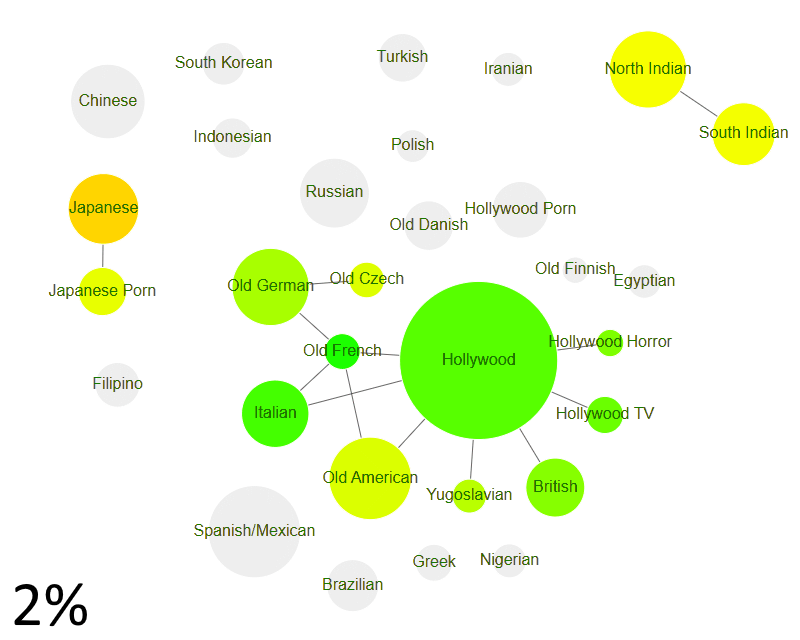
Chinese & Korean cluster emerges
Chinese & South Korean actors form the first cross-country cross-language cluster.
Hollywood expands to act with Scandinavian, Spanish, Polish, Brazilian & Nigerian films.
Other film industries (Russian, Greek, Egyptian — even Hollywood Porn — are still isolated.)
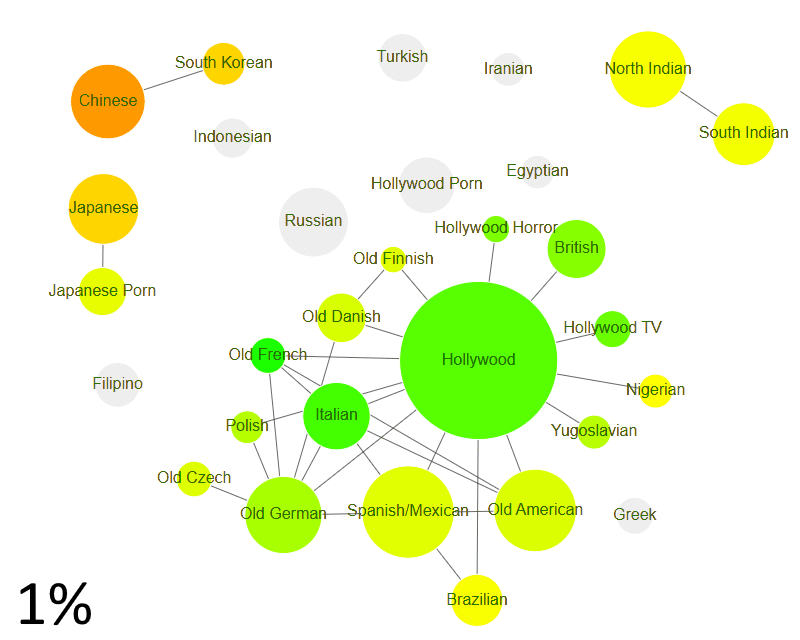
World Cinema vs the rest
Among groups that act with other groups at least 0.5% of the time, we have:
- Turkish & Iranian groups coming together
- Indonesian actors acting with the Chinese
- Hollywood expanding to cover Russian, Greek, Egyptian, and finally, Hollywood Porn. (It’s easier for Brazilian / Nigerian to act with Hollywood than to be a Hollywood Porn actor.)
At this point, there are 6 actor groups that act with each other at least 1 out of 200 times (0.5%).
- World Cinema (Hollywood & friends)
- Japanese (mainstream & porn)
- Indian (North & South)
- Chinese, South Korean & Indonesian
- Turkish & Iranian
- Filipino
One world of cinema
If we look at groups that act with other groups at least 0.5% of the time, we have a far more unified picture. Almost every actor group acts with another group at least 1 out of 400 times.
But even here, there’s an exception. Filipino actors — the most insular major actor group in the world.
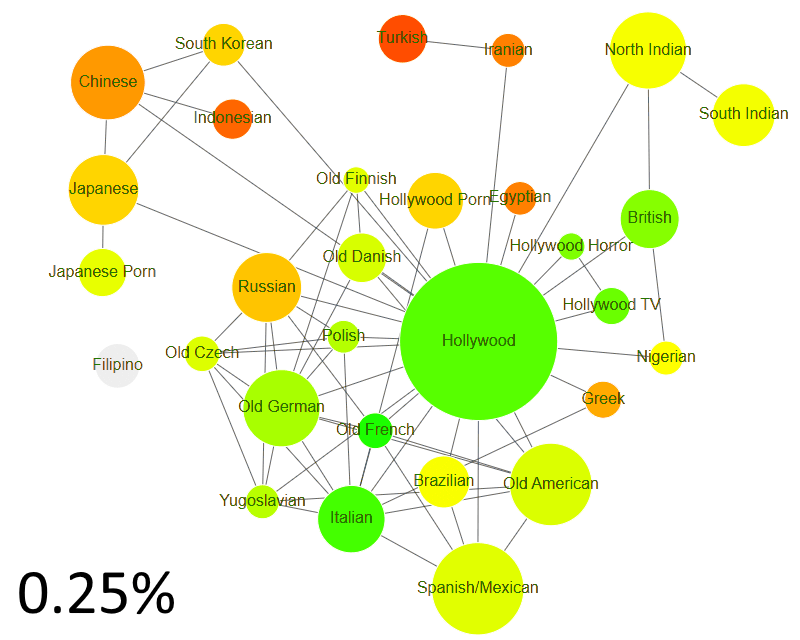
So, how isolated is Bollywood from World Cinema? For its size, it’s one of the most isolated actor groups. (But not as much as Iranian/Turkish or Filipino.)













{kind=link}