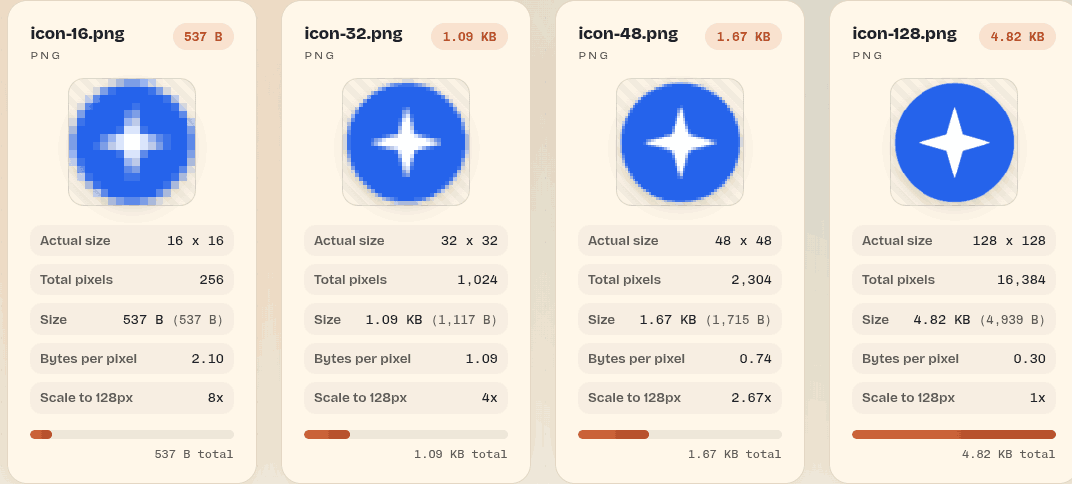
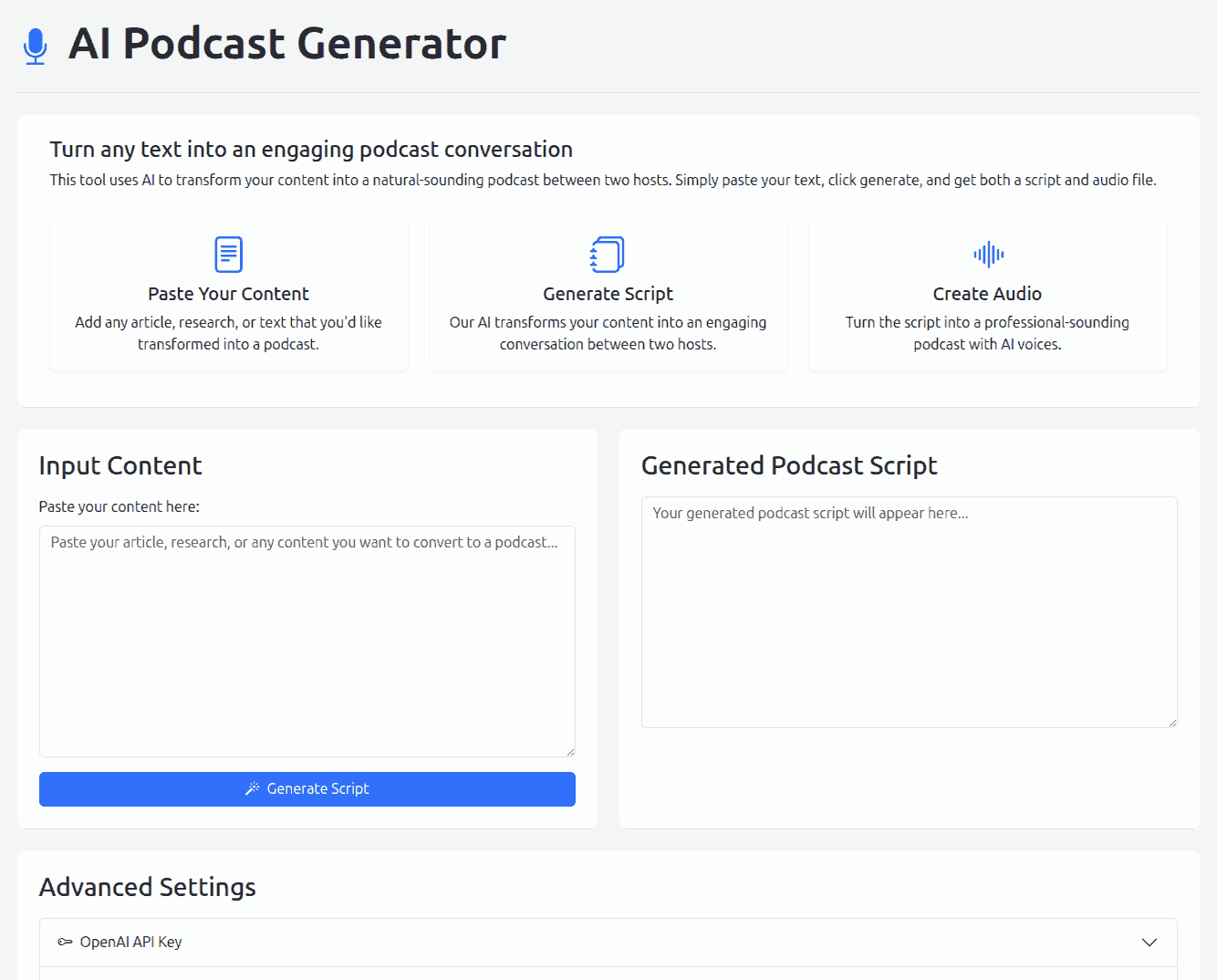
Using SVG favicons with Unicode
Browsers support SVG favicons as data: URLs. For example, this SVG: <svg xmlns="http://www.w3.org/2000/svg" viewBox="0 0 32 32"> <circle cx="16" cy="16" r="15" fill="#2563eb"/> <path fill="#fff" d="m16 7 2 7 7 2-7 2-2 7-2-7-7-2 7-2Z"/> </svg> … can be: Compressed via svgomg Converted to a data: URL via svgviewer Inserted into HTML like this: <link rel="icon" type="image/svg+xml" href="data:image/svg+xml,%3Csvg%20xmlns%3D%22http%3A%2F%2Fwww.w3.org%2F2000%2Fsvg%22%20viewBox%3D%220%200%2032%2032%22%3E%3Ccircle%20cx%3D%2216%22%20cy%3D%2216%22%20r%3D%2215%22%20fill%3D%22%232563eb%22%2F%3E%3Cpath%20fill%3D%22%23fff%22%20d%3D%22m16%207%202%207%207%202-7%202-2%207-2-7-7-2%207-2Z%22%2F%3E%3C%2Fsvg%3E"/> The fun part is that you can use text inside the SVG, styled as you wish: ...