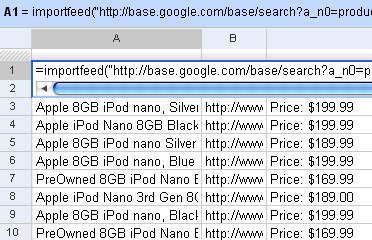
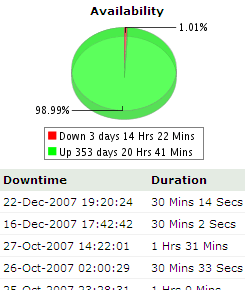
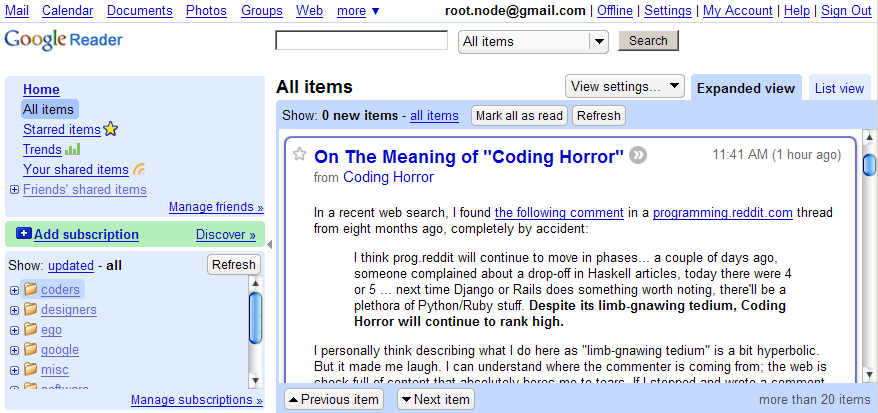
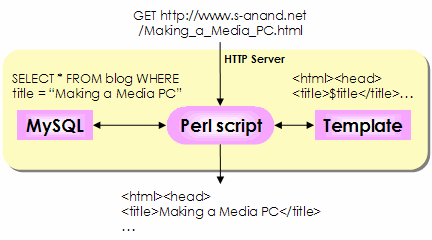
If something goes wrong with my site, I like to know of it. My top three problems are:
The site is down A page is missing Javascript isn’t working This is the last of 3 articles on these topics.
I am a bad programmer I am not a professional developer. In fact, I’m not a developer at all. I’m a management consultant. (Usually, it’s myself I’m trying to convince.) Since no one pays me for what little code I write, no one shouts at me for getting it wrong. So I have a happy and sloppy coding style. I write what I feel like, and publish it. I don’t test it. Worse, sometimes, I don’t even run it once. I’ve sent little scripts off to people which wouldn’t even compile. I make changes to this site at midnight, upload it, and go off to sleep without checking if the change has crashed the site or not. But no one tells me so At work, that’s usually OK. On the few occasions where I’ve written Perl scripts or VB Macros that don’t work, people call me back within a few hours, very worried that THEY’d done something wrong. (Sometimes, I don’t contradict them.) It can be quite a stressful experience but good thing you can learn more here on how to cope up with it. On my site, I don’t always get that kind of feedback. People just click the back button and go elsewhere. Recently, I’ve been doing more Javascript work on my site than writing stuff. Usually, the code works for me. (I write it for myself in the first place.) But I end up optimising for Firefox rather than IE, and for the plugins I have, etc. When I try the same app a few months later on my media PC, it doesn’t work, and shockingly enough, no one’s bothered telling me about it all these months. They’d just click, nothing happens, they’d vanish. But their browsers can tell me The good part about writing code in Javascript is that I can catch exceptions. Any Javascript error can be trapped. So since the end of last year, I’ve started wrapping almost every Javascript function I write in a try {} catch() {} block. In the catch block, I send a log message reporting the error. The code looks something like this:
...