This talk is an experiment. I am going to talk (literally) to ChatGPT on stage and have it do every kind of data analysis and visual storytelling I have ever done. Bangalore. 27 June. Of course, this is an LLM era away. So no promises. We might be doing something completely different on stage. LinkedIn
S Anand
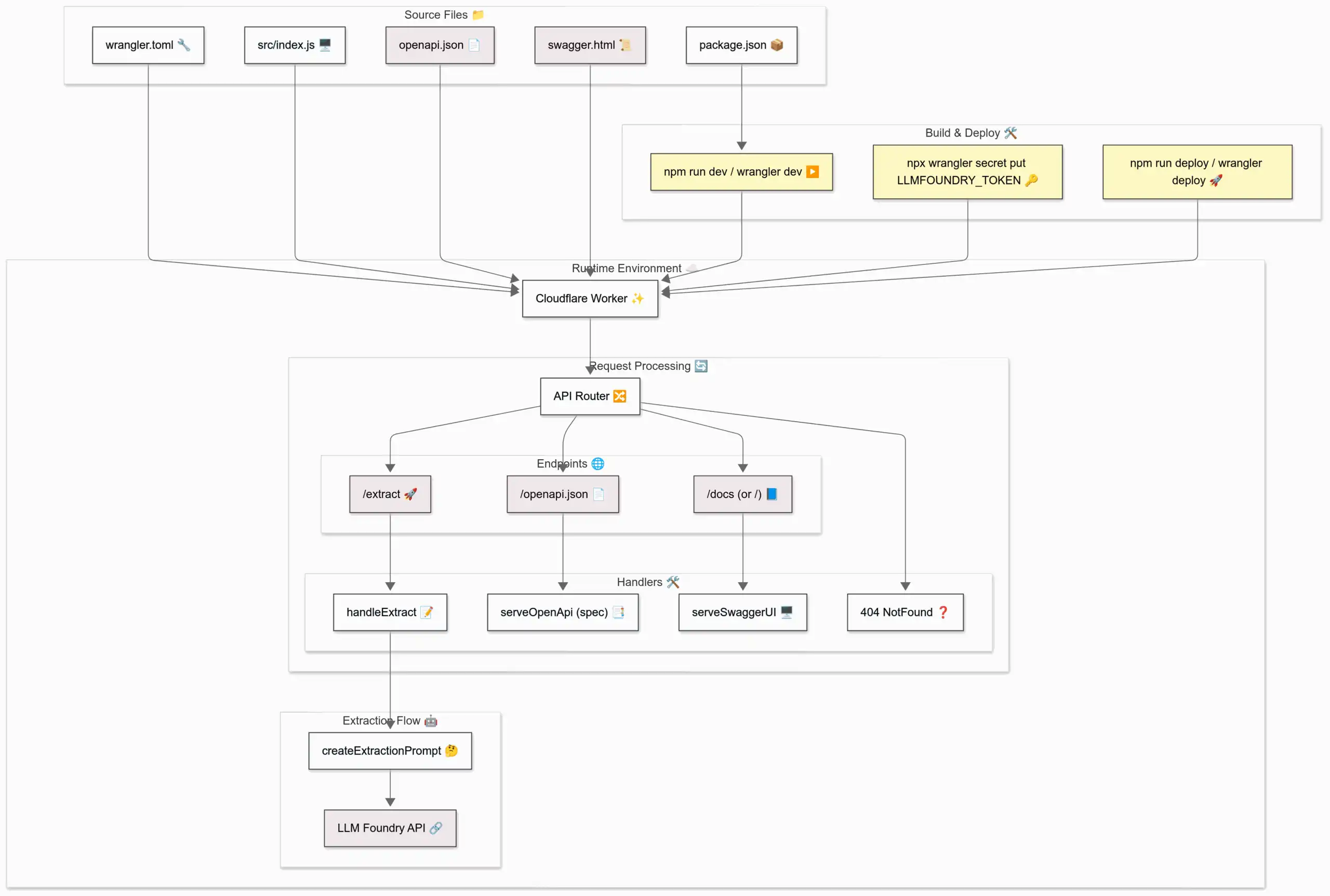
How to create a Technical Architecture from code with ChatGPT
Here’s my current workflow to create technical architecture diagrams from code. STEP 1: Copy the code Here’s a one-liner using files-to-prompt to copy all files in the current directory: fd | xargs uvx files-to-prompt --cxml | xclip -selection clipboard Or, you can specify individual files: uvx files-to-prompt --cxml README.md ... | xclip -selection clipboard STEP 2: Prompt for the a Mermaid diagram Mermaid is a Markdown charting language. I use this prompt with O4-Mini-High or O3: ...
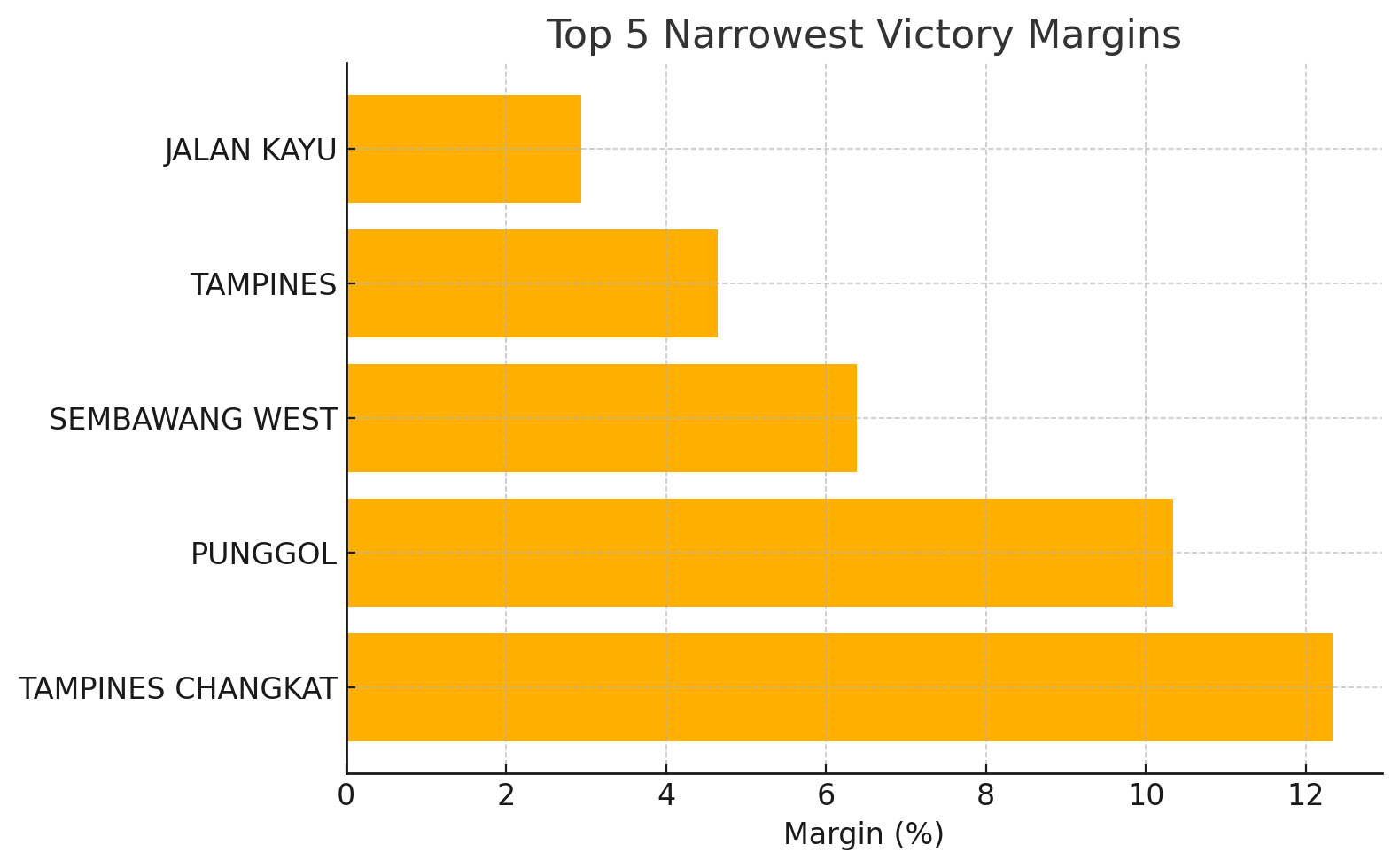
ChatGPT is a psephologist and data analyst
After having O4-Mini-High scrape Singapore 2025 election results, I asked it to create 3 data stories with this prompt: That worked. Now, I’m sharing the scraped CSV as well as the electoral GeoJSON. First, analyze the data and think of a few interesting data stories to tell. Pick the 3 most interesting, perhaps surprising, stories. Create a BEAUTIFUL, APT data visualization of each of these 3 stories suitable for The Strait Times and write a short accompanying article. ...

How can we rely on unreliable LLMs?" people ask me. Double-checking with another LLM," is my top response. That’s what we do with unreliable humans, anyway. LLMs feel magical until they start confidently hallucinating. When I asked 11 cheap LLMs to classify customer service messages into billing, refunds, order changes, etc. they got it wrong ~14%. Not worse than a human, but in scale-sensitive settings, that’s not good enough. But different LLMs make DIFFERENT mistakes. When double-checking with two LLMs, they were both wrong only 4% of the time. With 4 LLMs, it was only 1%. ...
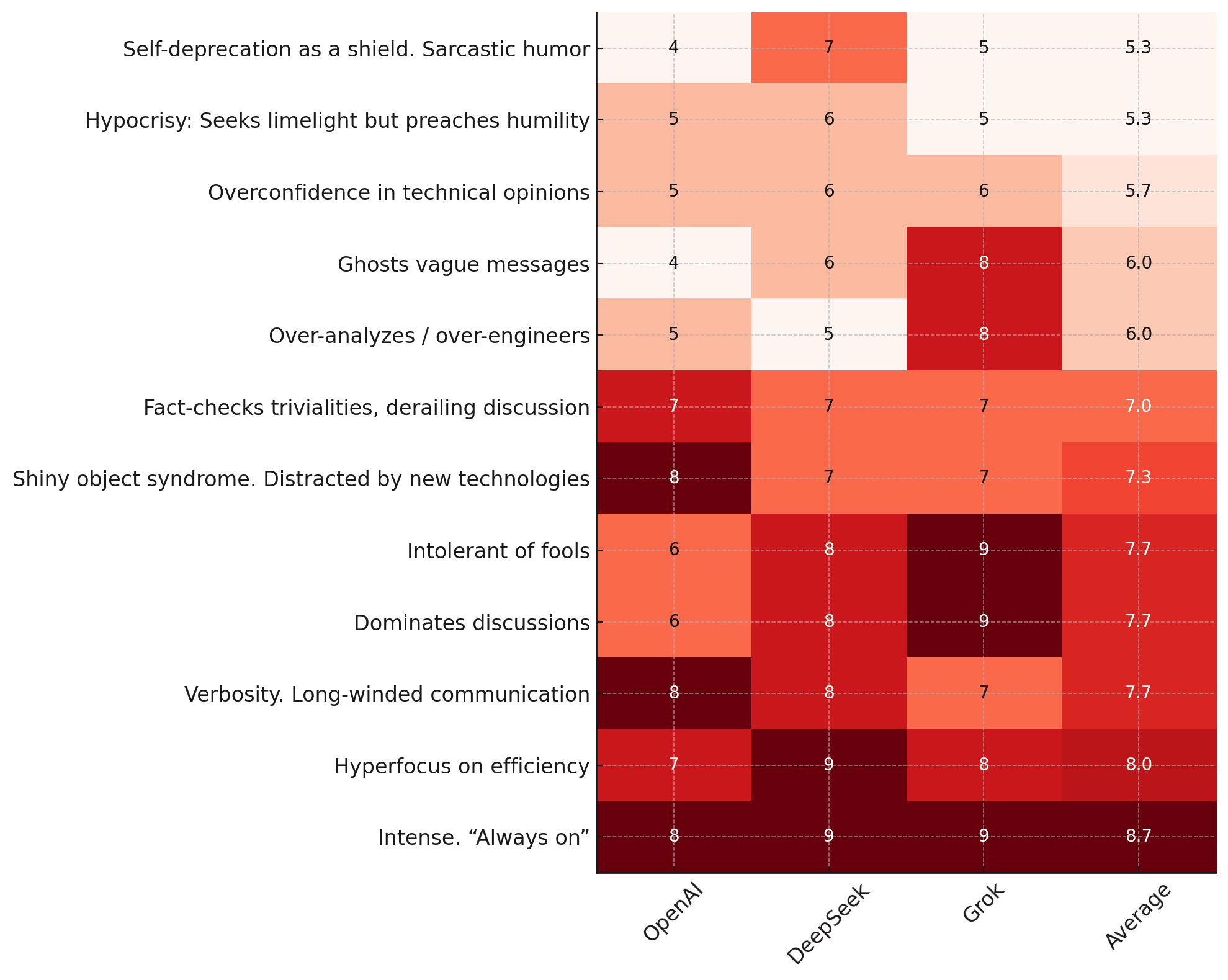
How To Double-Check Personality Flaws With AI
After ChatGPT's discussion of my personality flaws, I asked it to listing specific conversations as evidence for flaws. Then I asked 3 LLMs to rate the evidence. Personality FlawChatGPTDeepSeekGrokAverageSelf-deprecation as a shield. Sarcastic humor4755.3Hypocrisy: Seeks limelight but preaches humility5655.3Overconfidence in technical opinions5665.7Ghosts vague messages4686.0Over-analyzes / over-engineers5586.0Fact-checks trivialities, derailing discussion7777.0Shiny object syndrome. Distracted by new technologies8777.3Intolerant of fools6897.7Dominates discussions6897.7Verbosity. Long-winded communication8877.7Hyperfocus on efficiency7988.0Intense. “Always on”8998.7 🟢 LOW: Self-deprecation / sarcastic humour as shield ChatGPT: 4/10. Bio and a few quips reveal dry self-mockery, yet direct chat evidence of humour as defence is sparse; it surfaces only occasionally. | DeepSeek: 7/10. Explicit self-awareness goals and dry humor noted, but little evidence of defensive/sarcastic use. Grok: 5/10. Some self-deprecating humor exists, but its use as a shield is not strongly supported. 🟢 LOW: Hypocrisy: seeks limelight yet preaches humility ChatGPT: 6/10. You aspire to humility but routinely headline conferences and TEDx talks; the coexistence of public speaking and stated modesty gives the charge a middling footing. | DeepSeek: 6/10. TEDx/PyCon prominence contrasts with stated humility goals, though self-improvement efforts are genuine. Grok: 5/10. Public speaking contrasts with humility goals, though this may indicate self-awareness, not hypocrisy. 🟢 LOW: Over-confidence in technical opinions ChatGPT: 7/10. You assert strong views (e.g., Node vs FastAPI) but also invite verification and accept corrections, yielding only moderate evidence of over-confidence. | DeepSeek: 6/10. States strong preferences upfront but routinely invites validation and course-corrects. Grok: 6/10. Strong opinions are expressed, but openness to correction moderates the perception of overconfidence. 🟢 LOW: Ghosts vague messages ChatGPT: 5/10. You’ve stated you ignore low-context e-mails, but chat logs show you usually follow-up or clarify rather than disappear. | DeepSeek: 6/10. Documented tendency to ignore low-context questions, though chat logs show active clarification habits. Grok: 8/10. Multiple instances show the user ignoring or not responding to unclear or low-context messages. 🟢 LOW: Over-analyzes / over-engineers ChatGPT: 5/10. Designing auto-re-flow SVG chevrons and exhaustive RAG specs hint at depth beyond the simple solution, yet you also champion “smallest libraries” and lightweight rate-limiters. | DeepSeek: 5/10. Some prototype/structuring tendencies, but strong preference for minimal solutions counterbalances this. Grok: 8/10. The user often dives deeply into tasks, sometimes creating complex solutions for simple problems. 🟡 MEDIUM: Fact-checks trivialities, derailing discussion ChatGPT: 8/10. Many requests revolve around “double-check,” “fact-check,” or recalculating tiny details, which lengthens threads even when stakes are small. | DeepSeek: 7/10. Frequent accuracy demands and citation hunts elongate discussions, but stays focused when content is solid. Grok: 7/10. Evidence of prioritizing precision, like fact-checking minor details, can disrupt conversation flow. 🟡 MEDIUM: Shiny-object syndrome ChatGPT: 6/10. Parallel explorations of Godot, Matrix, Cloudflare Workers, SVG SmartArt, esp32-eye, etc. reveal a persistent pull toward new tech before finishing earlier threads. | DeepSeek: 7/10. Broad simultaneous explorations (Godot/WASM/DuckDB), though sustains core projects long-term. Grok: 7/10. Exploration of new technologies is frequent, but focus on core projects suggests a balanced curiosity. 🟡 MEDIUM: Intolerant of fools / low clarity ChatGPT: 7/10. Frequent demands for precise formats, citations, and “be specific” instructions show a low tolerance for ambiguity, though you still help patiently on non-technical questions. | DeepSeek: 8/10. Strong pattern of rejecting ambiguity/fluff, though softened by humor and non-technical engagements. Grok: 9/10. The user consistently demands clarity and efficiency, showing little patience for ambiguity or fluff. 🟡 MEDIUM: Dominates discussions ChatGPT: 4/10. Long, multi-part prompts and the need for TL;DRs suggest you can overshadow lighter voices, but you periodically insist on brevity and delegate tasks, tempering the effect. | DeepSeek: 8/10. Long technical messages (avg ~3k chars) and intense Q&A patterns create conversational dominance. Grok: 9/10. Detailed, technical responses consistently steer and dominate conversations. 🟡 MEDIUM: Verbosity / long-winded communication ChatGPT: 5/10. Average messages run several thousand characters, and you often request exhaustive, multi-section outputs—though you sometimes tell the assistant “Shorter please,” verbosity remains a clear pattern. | DeepSeek: 8/10. Multi-step technical requests dominate interactions, though periodic “shorter please” self-corrections exist. Grok: 7/10. Messages are often lengthy and detailed, though the user also requests concise responses from others. 🔴 HIGH: Hyper-focus on efficiency ChatGPT: 8/10. Recurrent themes—cost monitoring, smallest-lib preference, GPU-utilization alerts—show you relentlessly optimise workflows and expect others to keep pace. | DeepSeek: 9/10. Unambiguous prioritization of concise formats, minimal libraries, and metric-driven optimization. Grok: 8/10. Repeated emphasis on concise, efficient communication and minimal tools is evident. 🔴 HIGH: Intense – “always on” ChatGPT: 8/10. Around-the-clock, multi-topic requests (weekend cron jobs, 2 a.m. prototypes) portray sustained high energy, with only a few calmer “travel nerves” moments as counter-weight. | DeepSeek: 9/10. High-volume technical queries across domains, 6am research routines, and rapid prototyping habits. Grok: 9/10. High energy and engagement are consistently shown through task initiation and scheduling. My actions: Learn from fools and focus on the big-picture. Specifically: ...
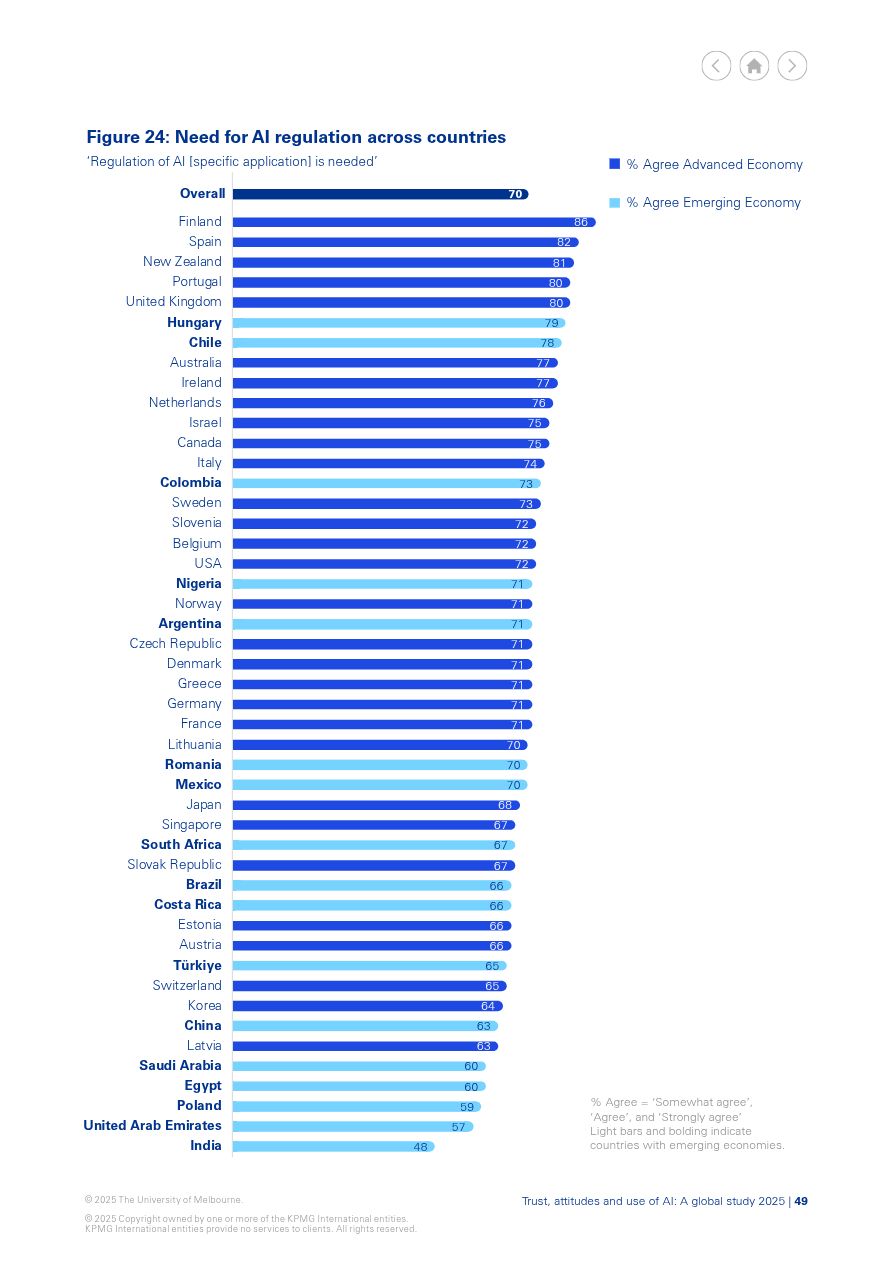
I’m completely aligned with the small majority in India on whether Regulation of AI is needed. … the majority of people in all countries view AI regulation as a necessity. India is the exception, where just under half (48%) agree regulation is needed. Source: Trust, attitudes and use of artificial intelligence - a fascinating report surveying ~1,000 people in every country. https://mbs.edu/-/media/PDF/Research/Trust_in_AI_Report.pdf LinkedIn

AI As Your Psychologist: Personality Flaws Exposed
ChatGPT can now search through your chats with the new memory feature. As an LLM Psychologist, I research how LLMs think. Could LLMs research how I think? I asked three models: Based on everything you know about me, simulate a group chat between some people who are debating whether or not to add me to the group, by talking about my personality flaws The models nailed it! Here are 12 flaws they found. ...
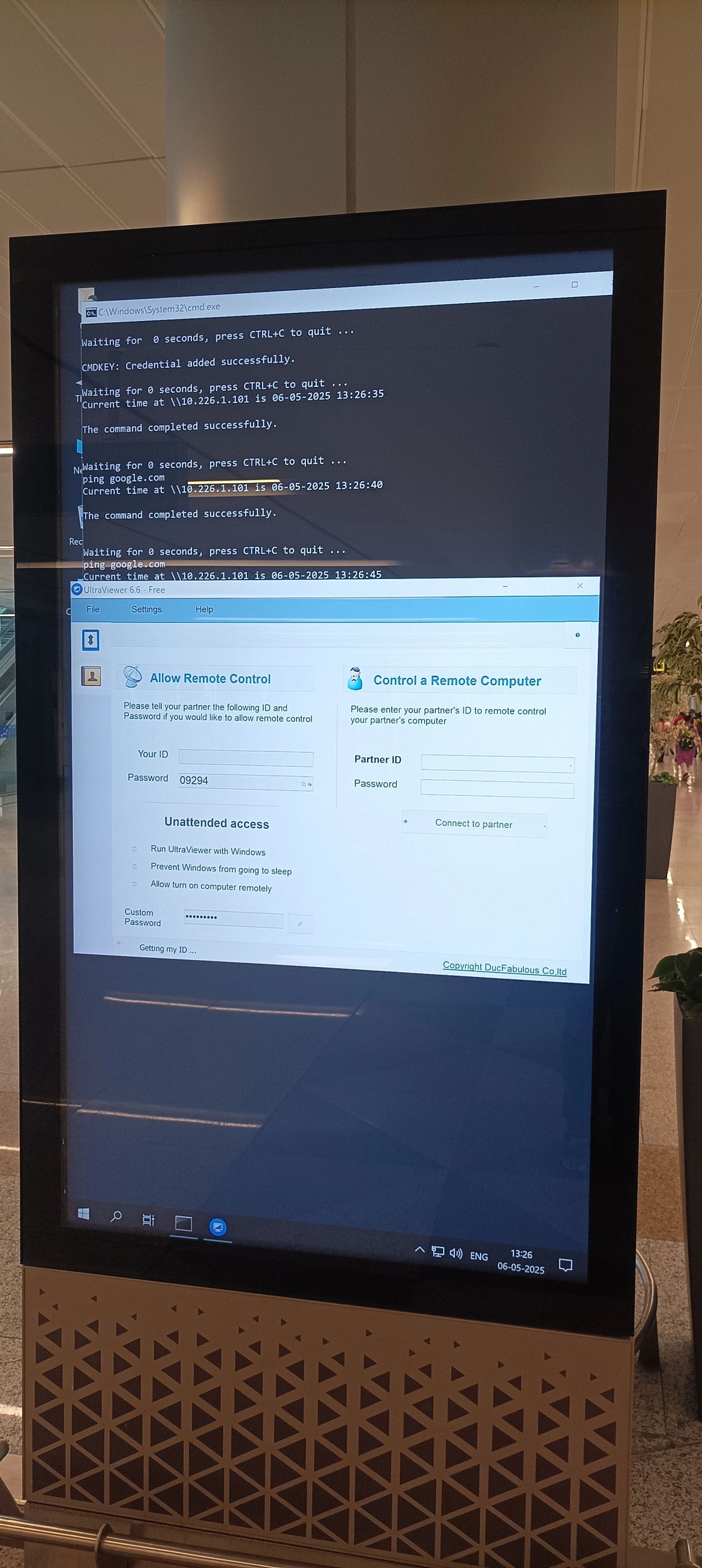
It’s good to know the IP address and password for remote control of the displays at the Hyderabad Airport. Thank you for the most interesting display I have seen in an airport! LinkedIn
Automating a podcast from GitHub commits
Here’s an LLM-generated podcast of what I coded last week. NotebookLM-inspired. The process proved straightforward. Get my GitHub commits for the week. Get the repositories I committed to for more context. Have an LLM generate a podcast script. I’m using GPT 4.1 Mini but might shift to Gemini 2.5 Flash or DeepSeek V3. …using a detailed prompt beginning with “You are a podcast script assistant for “Anand’s Weekly Codecast.” This episode is for the week of {WEEK}. …”. Here’s a sample output. Convert the script to audio. I’m using GPT 4o Mini TTS with customized voices of Ash and Nova. These now appear on my GitHub repo as a weekly summary. ...
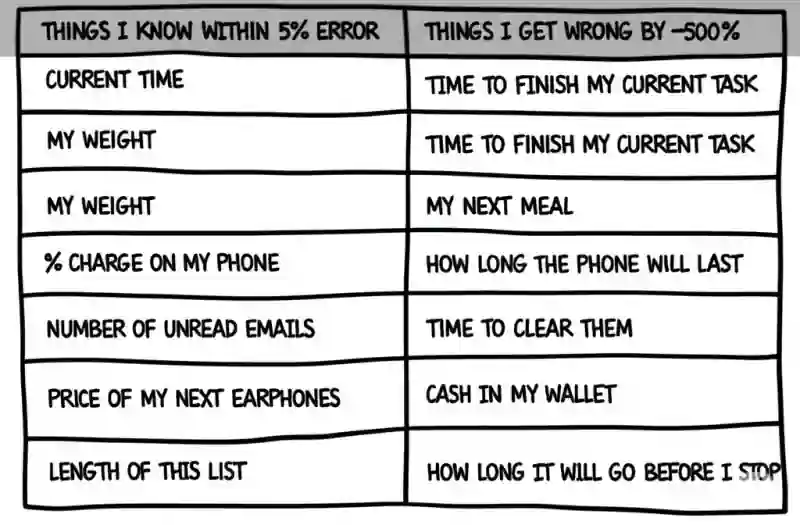
Things I know and things I don't
We all have stuff we know well and don’t. I know the % charge on my phone to within a few percent and the current time to within a few minutes – no matter when you ask. But I have no idea how much money there is in my pocket. Things I know within 5% error Things I get wrong by ~500% Current time Time to finish my current task My weight My next meal % charge on my phone How long the phone will last Number of unread emails Time to clear them Price of my next earphones Cash in my wallet Length of this list How long it will go before I stop But this apart, it turns out generating xkcd style comic strips is harder than I thought. ...

Me: What is the capital of France? Qwen3-30b-a3b: <think> Okay, so I need to figure out what the capital of France is. Let me start by recalling what I know about countries and their capitals. France is a country in Europe, right? I think it’s known for things like the Eiffel Tower, Paris, and maybe some famous foods like croissants or wine. Wait, but the question is specifically asking for the capital. The capital of a country is usually the city where the government is based. So, for example, the capital of the United States is Washington, D.C. So applying that logic to France, I need to think about which city is the seat of the French government. ...
Tools in Data Science course is free for all
My Tools in Data Science course is now open for anyone to audit. It’s part of the Indian Institute of Technology, Madras BS in Data Science online program. Here are some of the topics it covers in ~10 weeks: Development Tools: uv, git, bash, llm, sqlite, spreadsheets, AI code editors Deployment Tools: Colab, Codespaces, Docker, Vercel, ngrok, FastAPI, Ollama LLMs: prompt engineering, RAG, embeddings, topic modeling, multi-modal, real-time, evals, self-hosting Data Sourcing: Scraping websites and PDF with spreadsheets, Python, JavaScript and LLMs Data Preparation: Transforming data, images and audio with spreadsheets, bash, OpenRefine, Python, and LLMs Data Analysis: Statistical, geospatial, and network analysis with spreadsheets, Python, SQL, and LLMs Data Visualization: Data visualization and storytelling with spreadsheets, slides, notebooks, code, and LLMs ...
Feedback for TDS Jan 2025
When I feel completely useless, it helps to look at nice things people have said about my work. In this case, it’s the feedback for my Tools in Data Science course last term. Here are the ones I enjoyed reading. Having a coding background, the first GA seemed really easy. So I started the course thinking that it’ll be an easy S grade course for me. Oh how wrong was I!! The sleepless nights cursing my laptop for freezing while my docker image installed huge CUDA libraries with sentence-transformers; and then finding ways to make sure it does not, and then getting rid of the library itself, it’s just one example of how I was forced to become better by finding better solutions to multiple problems. This is one of the hardest, most frustrating and the most satisfying learning experience I’ve ever had, besides learning ML from Arun sir. ...

People still write? LinkedIn

Phone Rage and an OTP Flood
I called a few movers in Chennai, including “Unicorn Packers & Movers”, listed at 7015580411. He couldn’t understand what I said. I said, “We’re shifting to a house in Mylapore,” and he asked, “Shifting house where in Hyderabad?” (The reason became clear later.) It seemed I had the wrong number, so I said, “No, sorry, we need someone else,” and hung up. His phone rage began. He called back and said, “Why did you wake me up and waste my time?” From his tone it was clear I couldn’t say anything helpful. From the quality of my signal it was clear I couldn’t have a meaningful conversation. So I just put the phone down without cutting it. ...
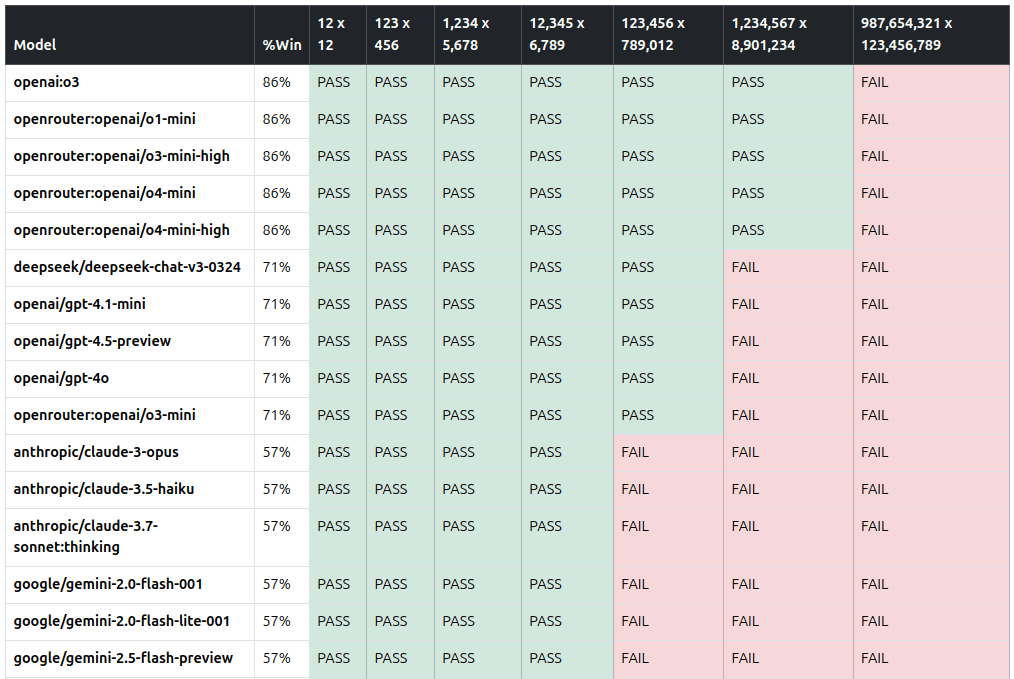
Are LLMs any good at mental math?
I asked 50 LLMs to multiply 2 numbers: 12 x 12 123 x 456 1,234 x 5,678 12,345 x 6,789 123,456 x 789,012 1,234,567 x 8,901,234 987,654,321 x 123,456,789 LLMs aren’t good tools for math and this is just an informal check. But the results are interesting: Model %Win Q1 Q2 Q3 Q4 Q4 Q6 Q7 openai:o3 86% ✅ ✅ ✅ ✅ ✅ ✅ ❌ openrouter:openai/o1-mini 86% ✅ ✅ ✅ ✅ ✅ ✅ ❌ openrouter:openai/o3-mini-high 86% ✅ ✅ ✅ ✅ ✅ ✅ ❌ openrouter:openai/o4-mini 86% ✅ ✅ ✅ ✅ ✅ ✅ ❌ openrouter:openai/o4-mini-high 86% ✅ ✅ ✅ ✅ ✅ ✅ ❌ deepseek/deepseek-chat-v3-0324 71% ✅ ✅ ✅ ✅ ✅ ❌ ❌ openai/gpt-4.1-mini 71% ✅ ✅ ✅ ✅ ✅ ❌ ❌ openai/gpt-4.5-preview 71% ✅ ✅ ✅ ✅ ✅ ❌ ❌ openai/gpt-4o 71% ✅ ✅ ✅ ✅ ✅ ❌ ❌ openrouter:openai/o3-mini 71% ✅ ✅ ✅ ✅ ✅ ❌ ❌ anthropic/claude-3-opus 57% ✅ ✅ ✅ ✅ ❌ ❌ ❌ anthropic/claude-3.5-haiku 57% ✅ ✅ ✅ ✅ ❌ ❌ ❌ anthropic/claude-3.7-sonnet:thinking 57% ✅ ✅ ✅ ✅ ❌ ❌ ❌ google/gemini-2.0-flash-001 57% ✅ ✅ ✅ ✅ ❌ ❌ ❌ google/gemini-2.0-flash-lite-001 57% ✅ ✅ ✅ ✅ ❌ ❌ ❌ google/gemini-2.5-flash-preview 57% ✅ ✅ ✅ ✅ ❌ ❌ ❌ google/gemini-2.5-flash-preview:thinking 57% ✅ ✅ ✅ ✅ ❌ ❌ ❌ google/gemini-2.5-pro-preview-03-25 57% ✅ ✅ ✅ ✅ ❌ ❌ ❌ google/gemini-flash-1.5 57% ✅ ✅ ✅ ✅ ❌ ❌ ❌ google/gemini-pro-1.5 57% ✅ ✅ ✅ ✅ ❌ ❌ ❌ google/gemma-3-12b-it 57% ✅ ✅ ✅ ✅ ❌ ❌ ❌ google/gemma-3-27b-it 57% ✅ ✅ ✅ ✅ ❌ ❌ ❌ meta-llama/llama-4-maverick 57% ✅ ✅ ✅ ❌ ✅ ❌ ❌ meta-llama/llama-4-scout 57% ✅ ✅ ✅ ✅ ❌ ❌ ❌ openai/gpt-4-turbo 57% ✅ ✅ ✅ ✅ ❌ ❌ ❌ openai/gpt-4.1 57% ✅ ✅ ✅ ❌ ✅ ❌ ❌ amazon/nova-lite-v1 43% ✅ ✅ ✅ ❌ ❌ ❌ ❌ amazon/nova-pro-v1 43% ✅ ✅ ✅ ❌ ❌ ❌ ❌ anthropic/claude-3-haiku 43% ✅ ✅ ✅ ❌ ❌ ❌ ❌ anthropic/claude-3.5-sonnet 43% ✅ ✅ ✅ ❌ ❌ ❌ ❌ meta-llama/llama-3.1-405b-instruct 43% ✅ ✅ ❌ ✅ ❌ ❌ ❌ meta-llama/llama-3.1-70b-instruct 43% ✅ ✅ ❌ ✅ ❌ ❌ ❌ meta-llama/llama-3.2-3b-instruct 43% ✅ ✅ ❌ ✅ ❌ ❌ ❌ meta-llama/llama-3.3-70b-instruct 43% ✅ ✅ ❌ ✅ ❌ ❌ ❌ openai/gpt-4.1-nano 43% ✅ ✅ ✅ ❌ ❌ ❌ ❌ openai/gpt-4o-mini 43% ✅ ✅ ✅ ❌ ❌ ❌ ❌ qwen/qwen-2-72b-instruct 43% ✅ ✅ ✅ ❌ ❌ ❌ ❌ anthropic/claude-3-sonnet 29% ✅ ✅ ❌ ❌ ❌ ❌ ❌ deepseek/deepseek-r1 29% ✅ ✅ ❌ ❌ ❌ ❌ ❌ google/gemini-flash-1.5-8b 29% ✅ ✅ ❌ ❌ ❌ ❌ ❌ google/gemma-3-4b-it 29% ✅ ✅ ❌ ❌ ❌ ❌ ❌ meta-llama/llama-3-8b-instruct 29% ✅ ✅ ❌ ❌ ❌ ❌ ❌ meta-llama/llama-3.1-8b-instruct 29% ✅ ❌ ❌ ✅ ❌ ❌ ❌ openai/gpt-3.5-turbo 29% ✅ ✅ ❌ ❌ ❌ ❌ ❌ amazon/nova-micro-v1 14% ✅ ❌ ❌ ❌ ❌ ❌ ❌ meta-llama/llama-2-13b-chat 14% ✅ ❌ ❌ ❌ ❌ ❌ ❌ meta-llama/llama-3-70b-instruct 14% ✅ ❌ ❌ ❌ ❌ ❌ ❌ meta-llama/llama-3.2-1b-instruct 14% ✅ ❌ ❌ ❌ ❌ ❌ ❌ google/gemma-3-1b-it:free 0% ❌ ❌ ❌ ❌ ❌ ❌ ❌ meta-llama/llama-2-70b-chat 0% ❌ ❌ - - ❌ ❌ ❌ Average 96% 86% 66% 58% 24% 10% 0% OpenAI’s reasoning models cracked it, scoring 6/7, stumbling only on the 9-digit multiplication. ...
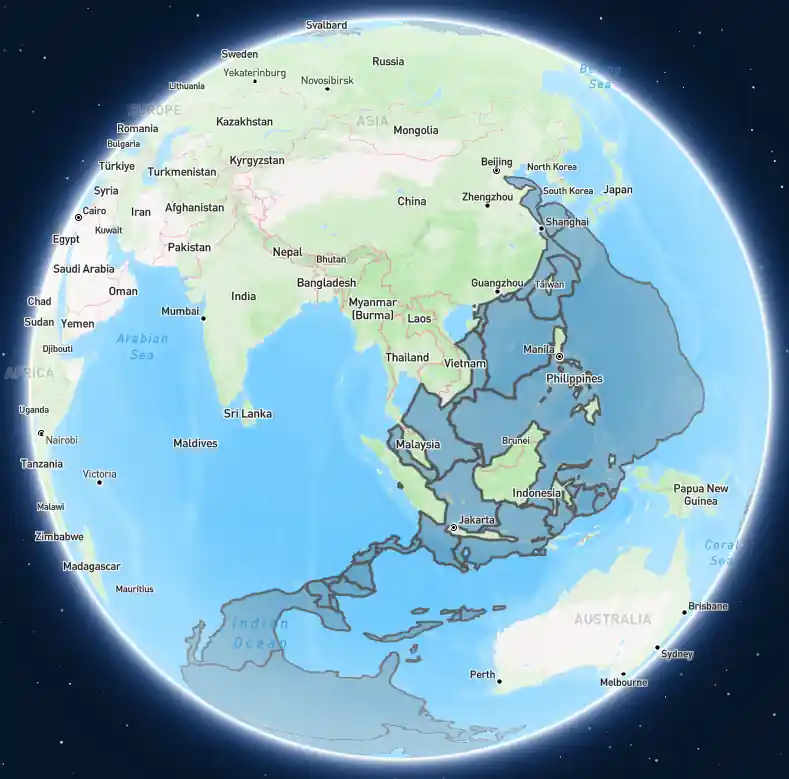
How to Create a Data Visualization Without Coding
After seeing David McCandless’ post “Which country is across the ocean?” I was curious which country you would reach if you tunneled below in a straight line (the antipode). This is a popular visualization, but I wanted to see if I could get the newer OpenAI models to create the visual without me 𝗿𝘂𝗻𝗻𝗶𝗻𝗴 any code (i.e. I just want the answer.) After a couple of iterations, O3 did a great job with this prompt: ...
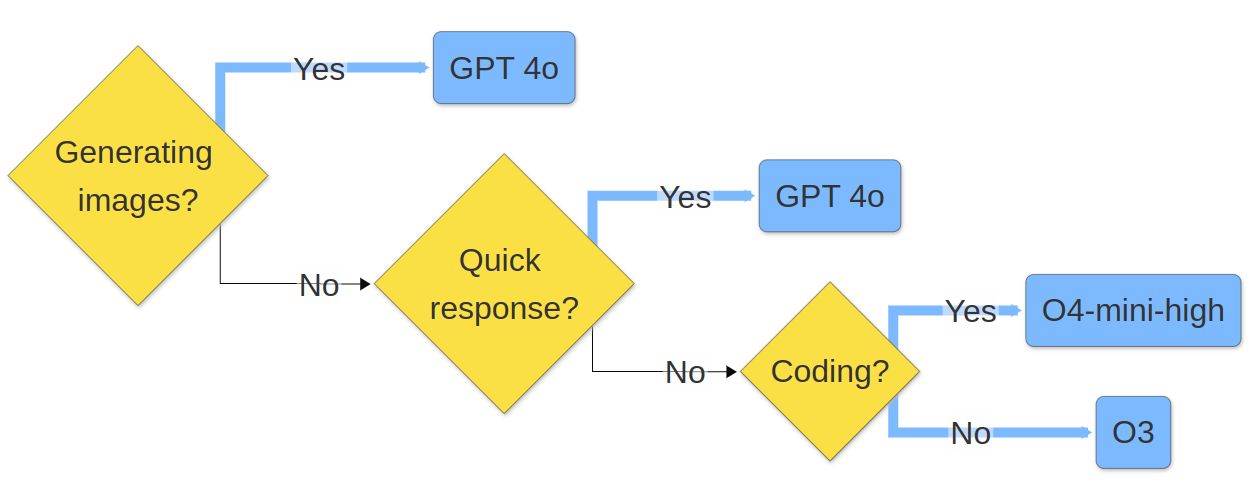
This is my decision tree for which model to use on #ChatGPT right now. O𝟯: Use by **default. O**𝟰-mini-high: Use when **coding. GPT** 𝟰o: Use for a quick response or to create image. LinkedIn
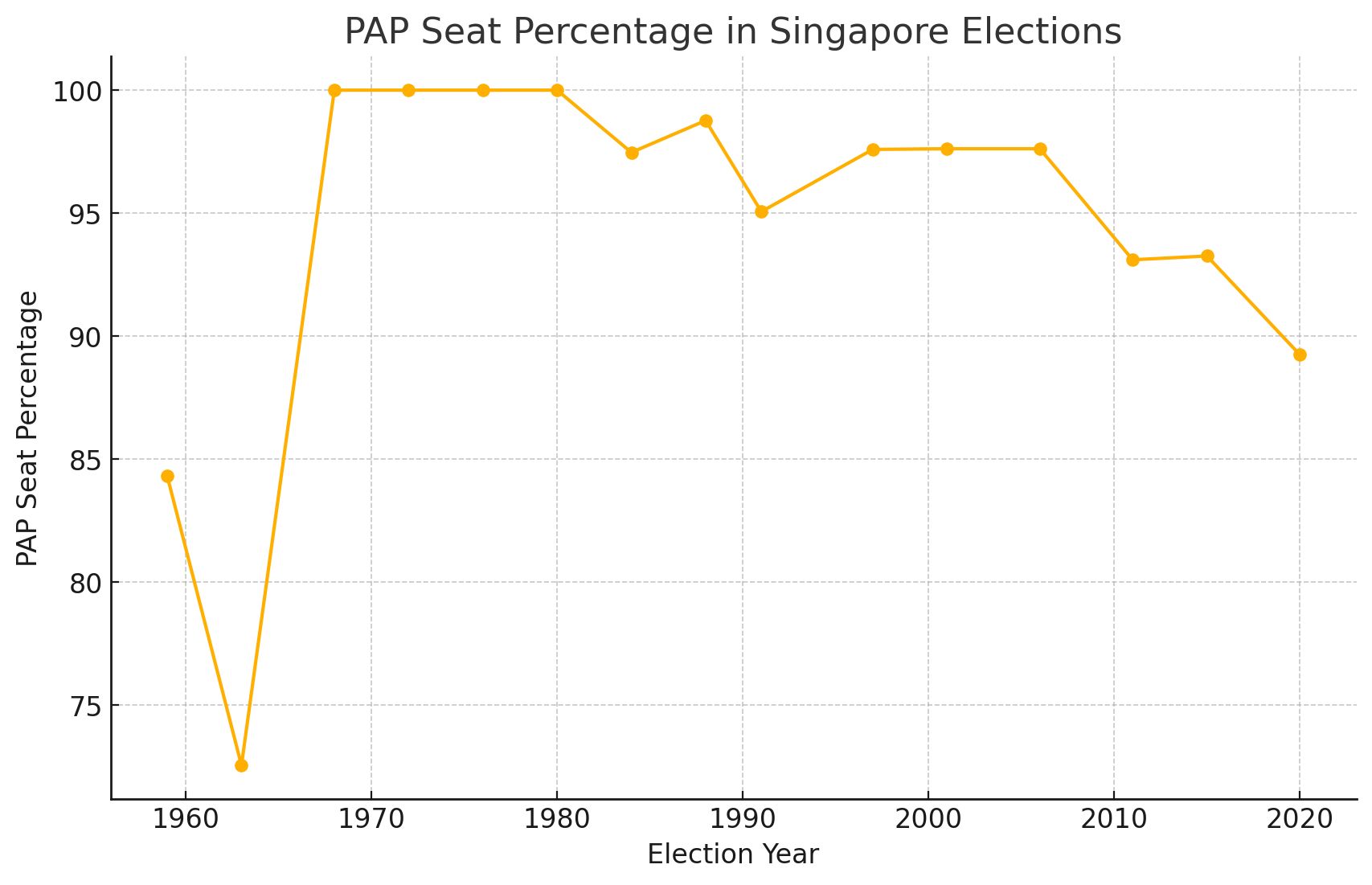
What percentage of seats does the #Singapore People’s Action Party win? Normally, this is a 2-hour programmatic data-scraping + data visualization exercise, ideal for a data journalism class. Now, it’s a 2-minute question to O3-Mini-High. Search online for the historical results of all the Singapore elections and show me a table and chart of the number and percentage of the seats won by People’s Action Party. Chat link: https://chatgpt.com/share/6808314c-542c-800c-843e-4d53ff57768d It “manually” read the Wikipedia page for each election, then wrote a Python script to draw the chart. ...

O3 Is Now My Personalized Learning Coach
I use Deep Research to explore topics. For example: Text To Speech Engines. Tortoise TTS leads the open source TTS. Open-Source HTTP Servers. Caddy wins. Public API-Based Data Storage Options. Supabase wins. etc. But these reports are very long. With O3 and O4 Mini supporting thinking with search, we can do quick research, instead of deep research. One minute, not ten. One page, not ten. ...