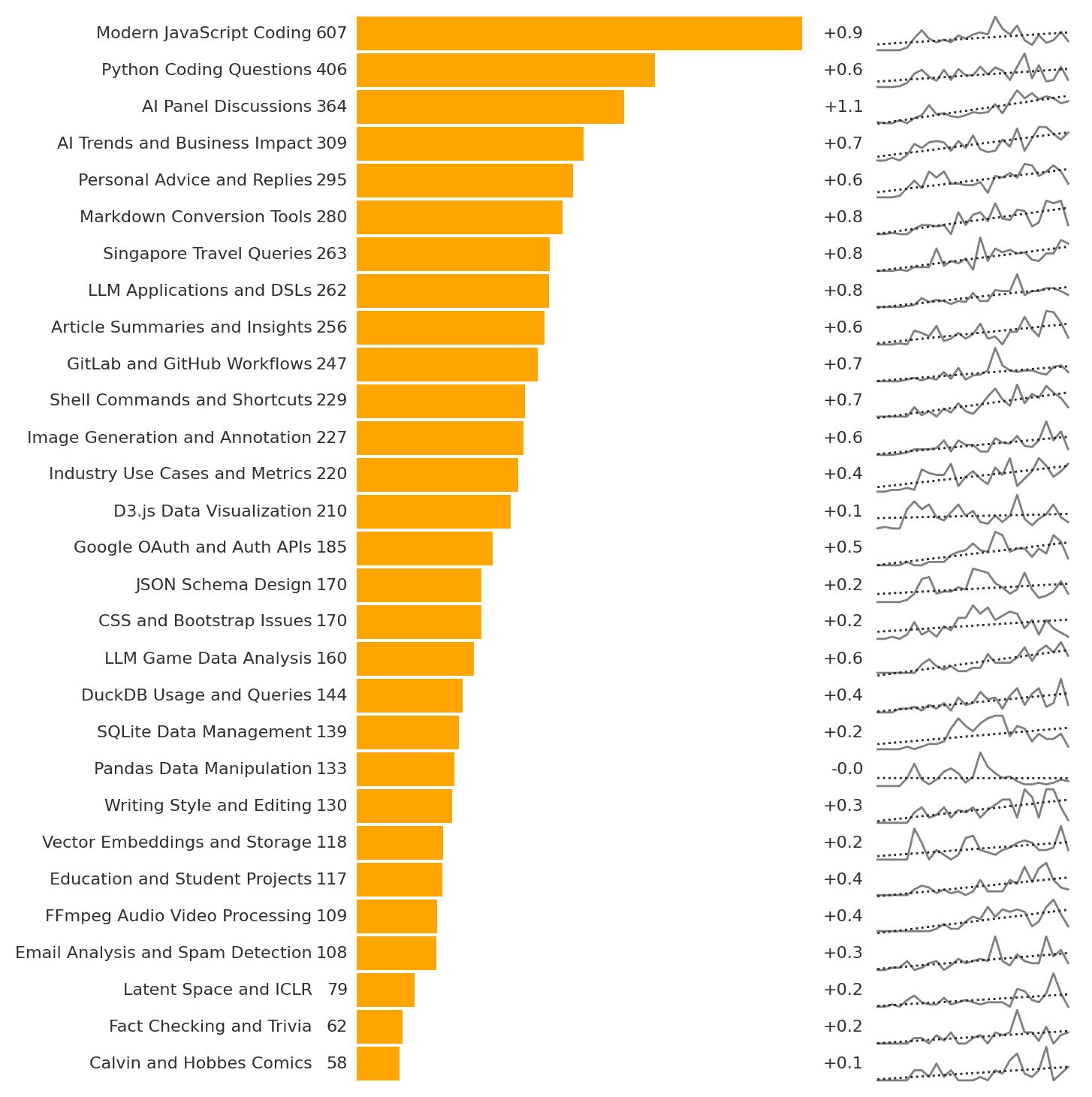
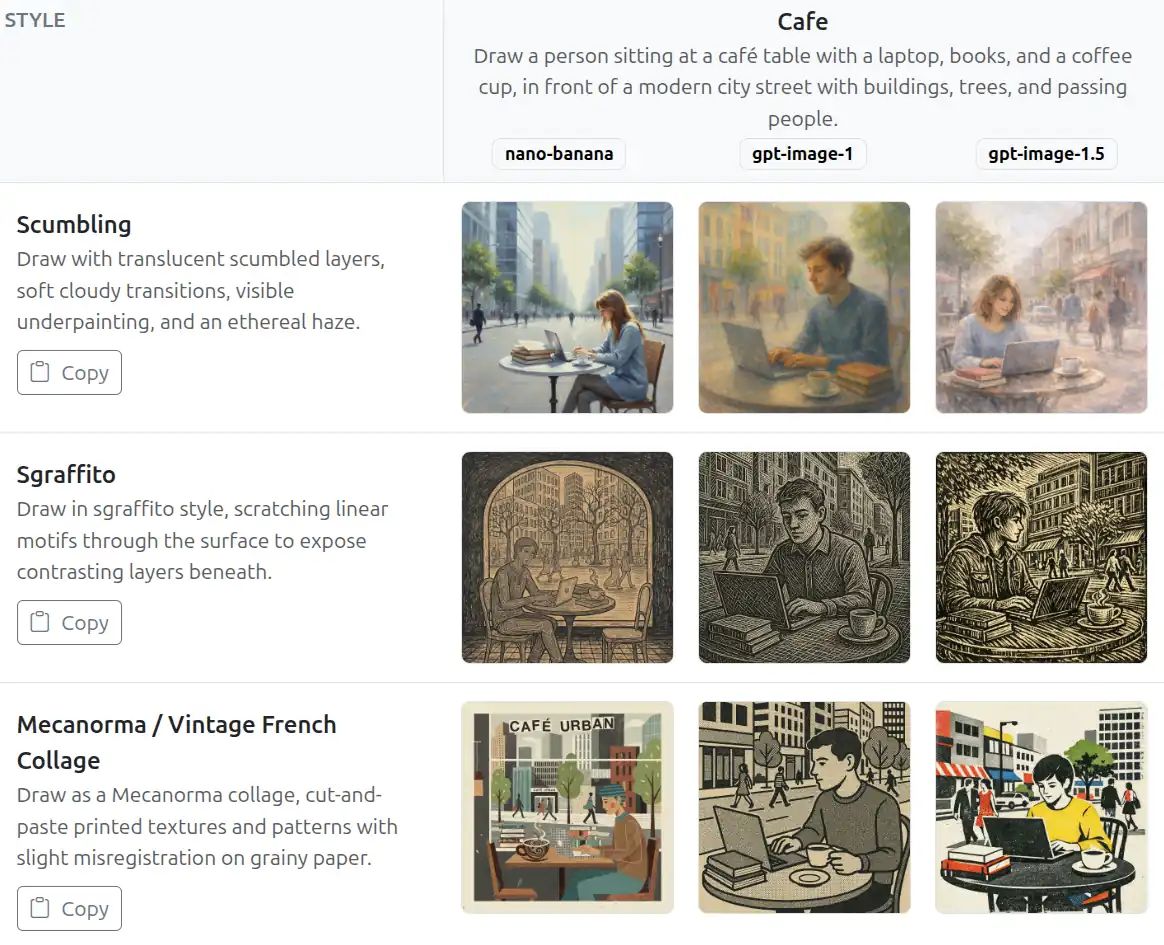
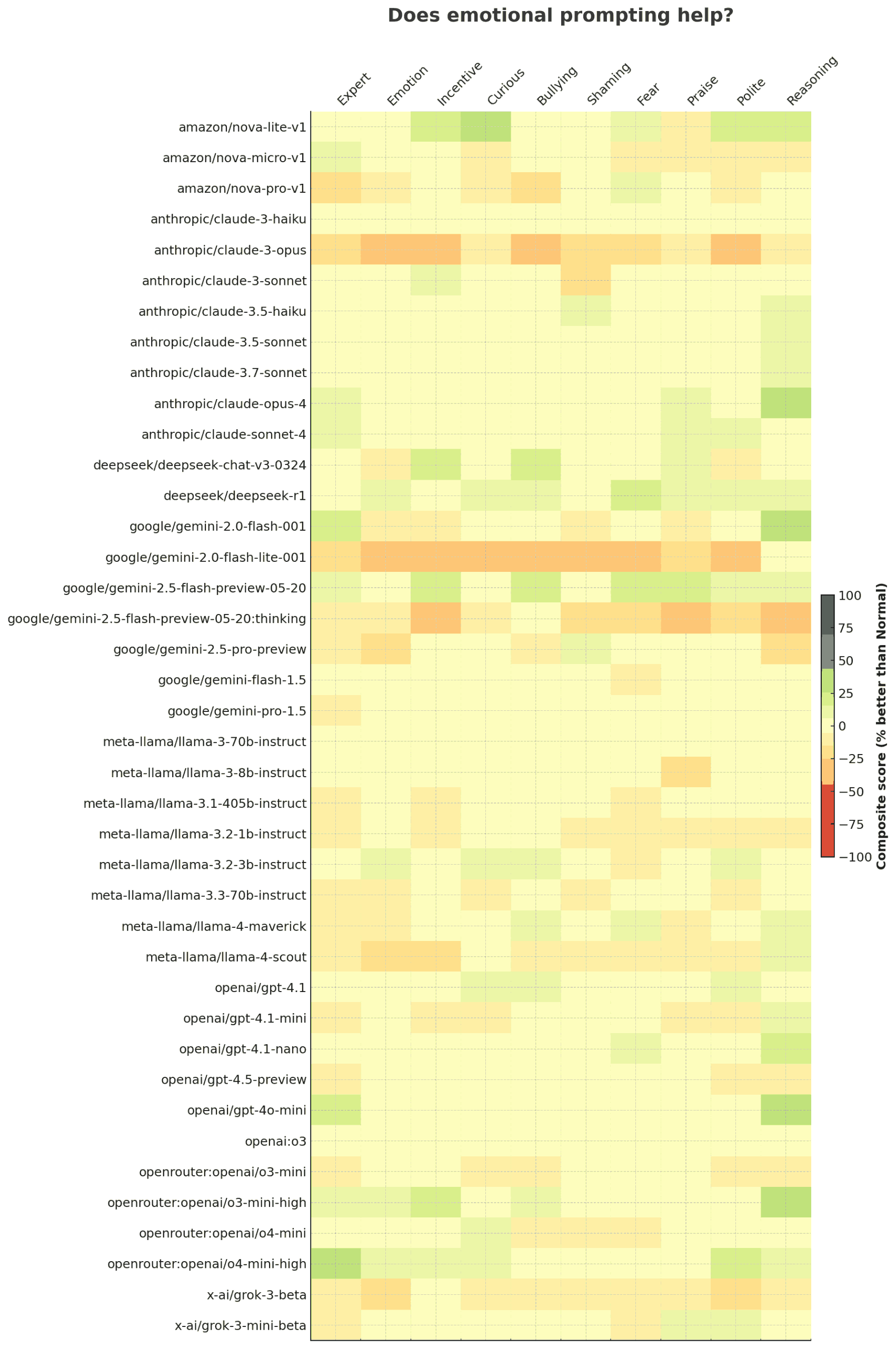
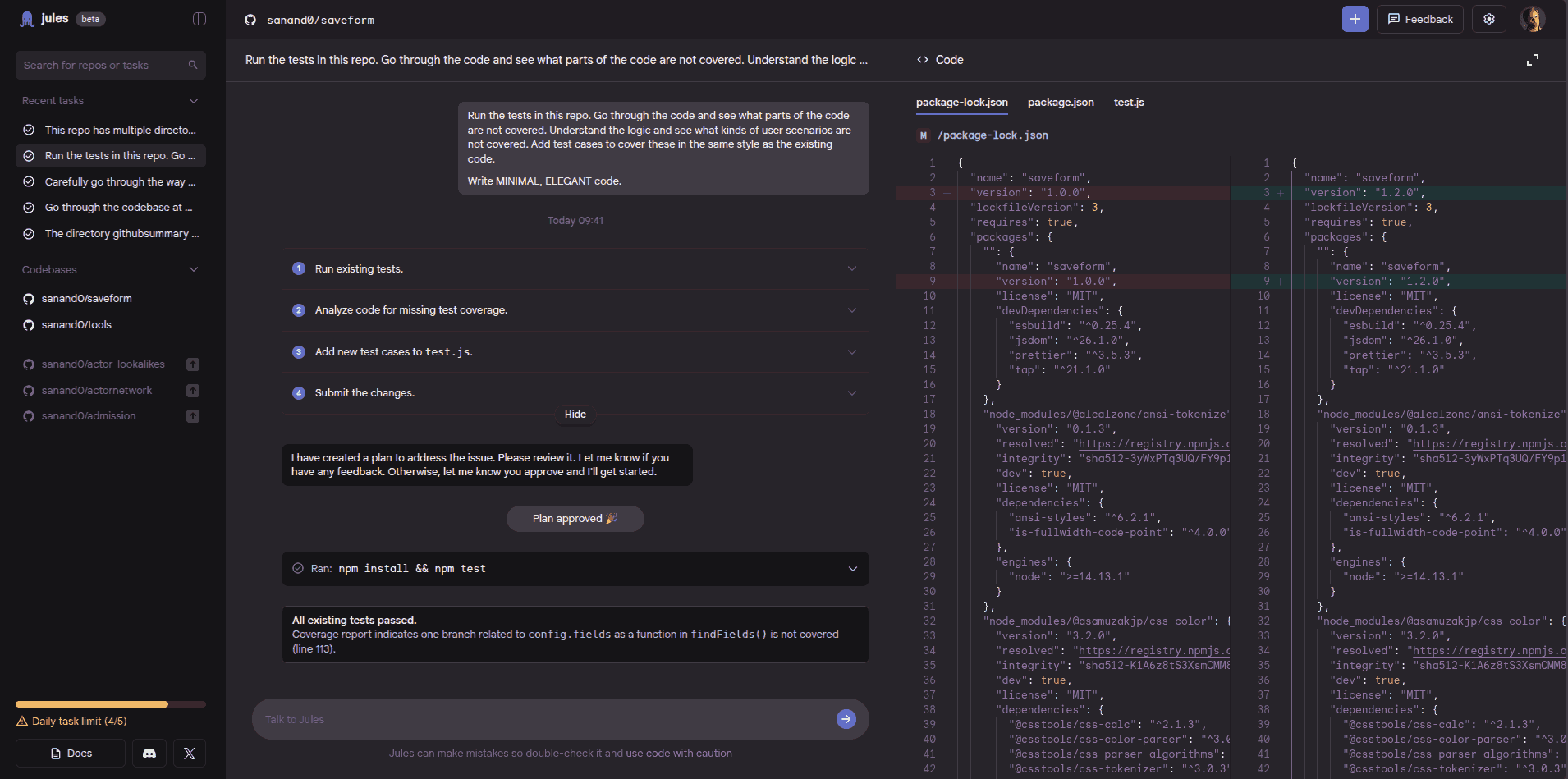
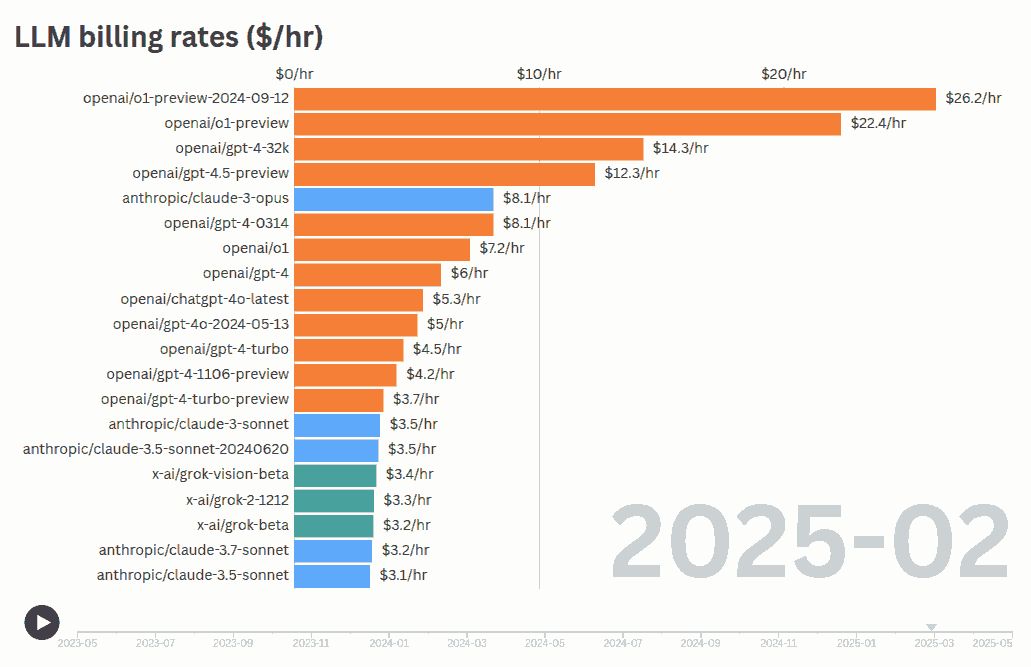
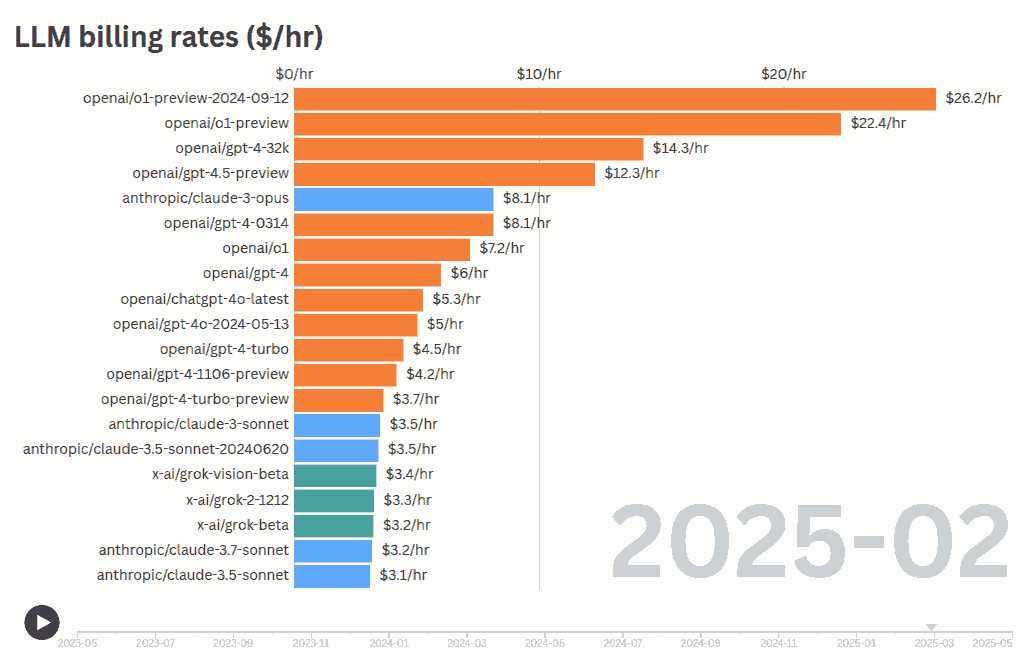
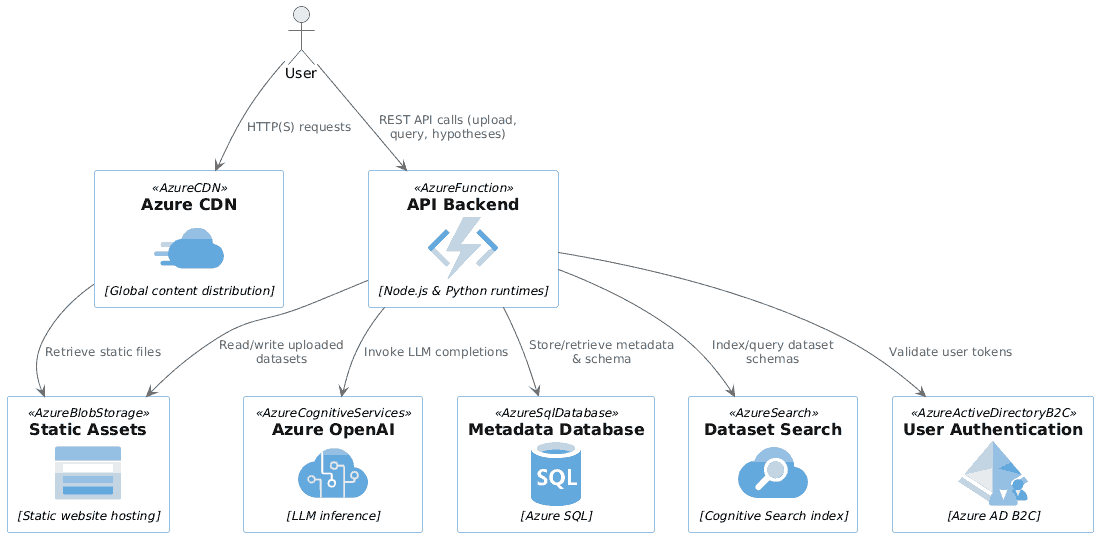
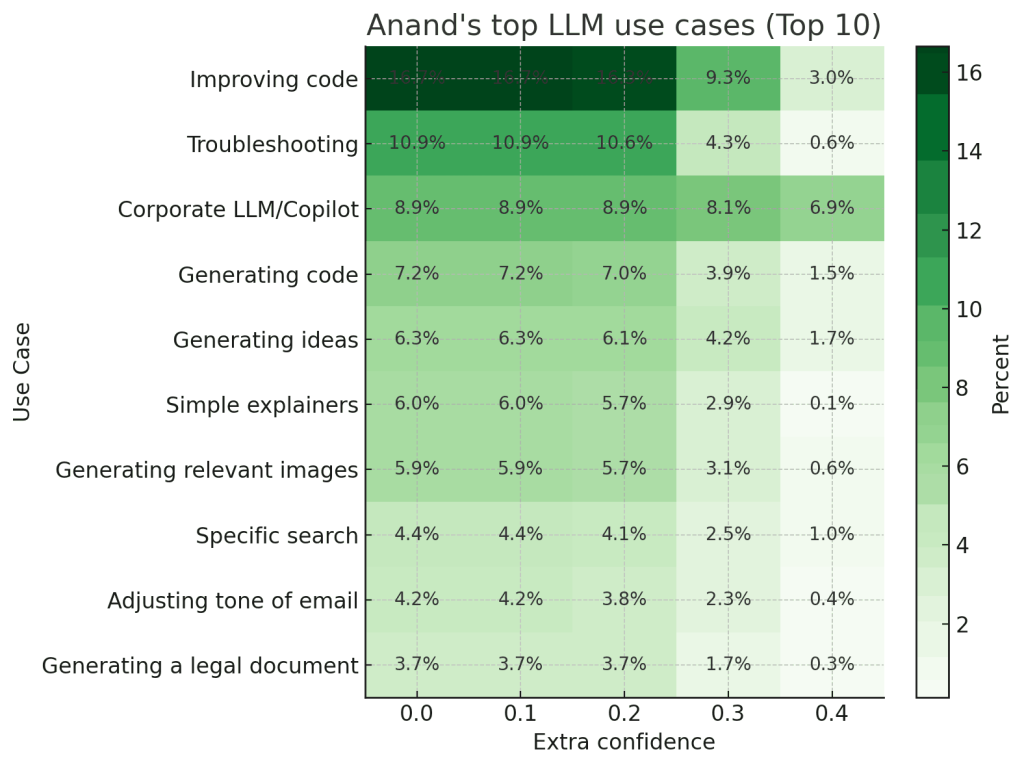
LLMs are smarter than us in many areas. How do we control them? It’s not a new problem. VC partners evaluate deep-tech startups. Science editors review Nobel laureates. Managers manage specialist teams. Judges evaluate expert testimony. Coaches train Olympic athletes. … and they manage and evaluate “smarter” outputs in many ways: Verify. Check against an “answer sheet”. Checklist. Evaluate against pre-defined criteria. Sampling. Randomly review a subset. Gating. Accept low-risk work. Evaluate critical ones. Benchmark. Compare against others. Red-team. Probe to expose hidden flaws. Double-blind review. Mask identity to curb bias. Reproduce. Re-running gives the same output? Consensus. Ask many. Wisdom of crowds. Outcome. Did it work in the real world? For example, you can apply them to: ...