Vibe-Scraping: Write outcomes, not scrapers
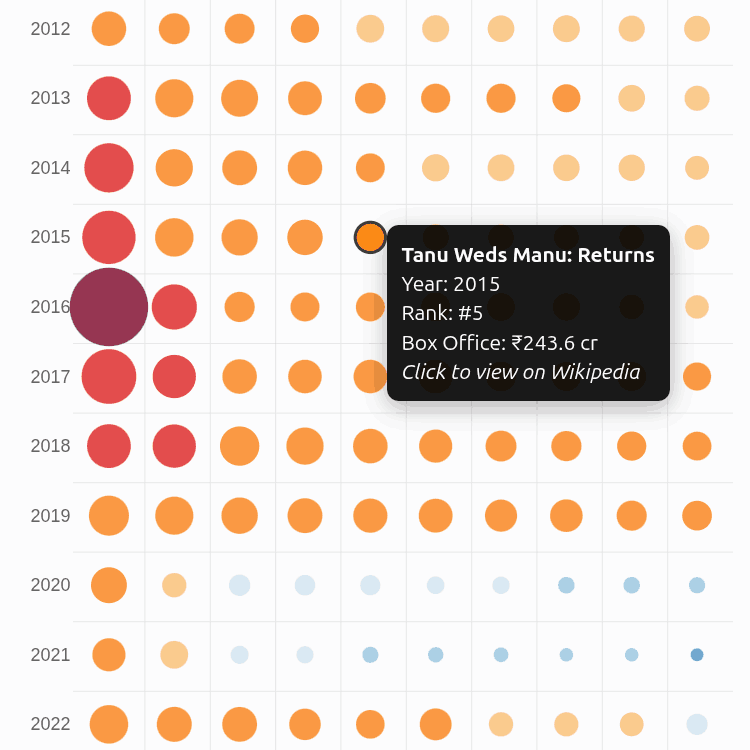
There hasn’t been a box-office explosion like Dangal in the history of Bollywood. CPI inflation-adjusted to 2024, it is the only film in the ₹3,000 Cr club. 3 Idiots (2009) is the first member of the ₹1,000 Cr club (2024-inflation-adjusted). The hot streak was 2013-2017: each year, a film crossed that bar: Dhoom 3, PK, Bajrangi Bhaijaan, Dangal, Secret Superstar. Since then, we never saw such a release except in 2023 (Jawan, Pathan). ...