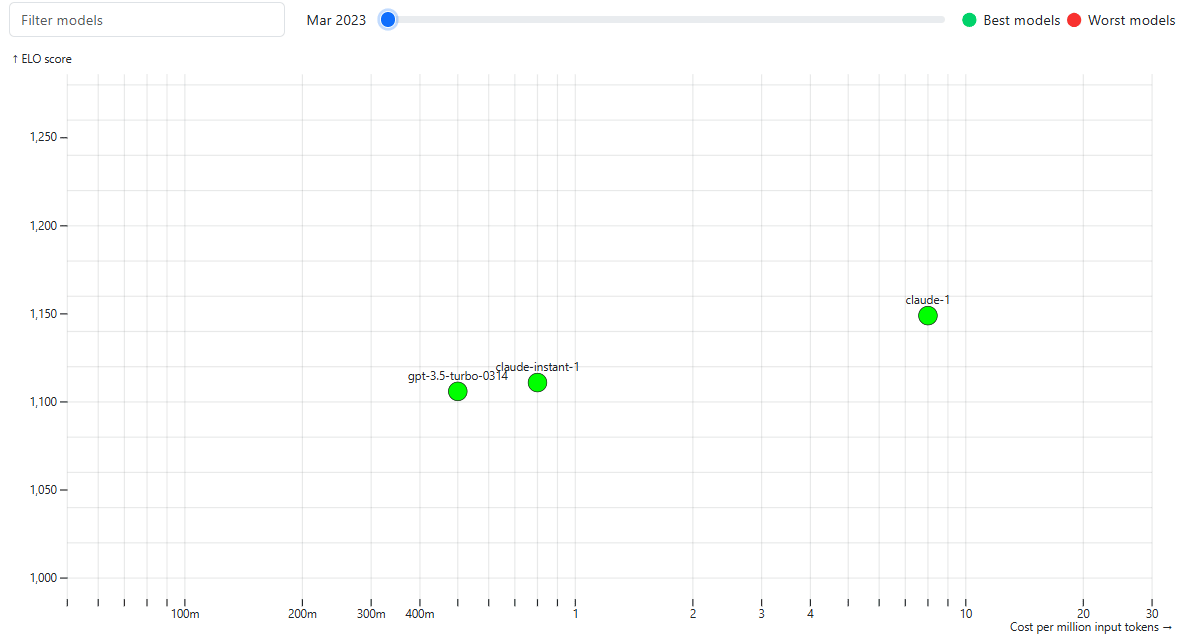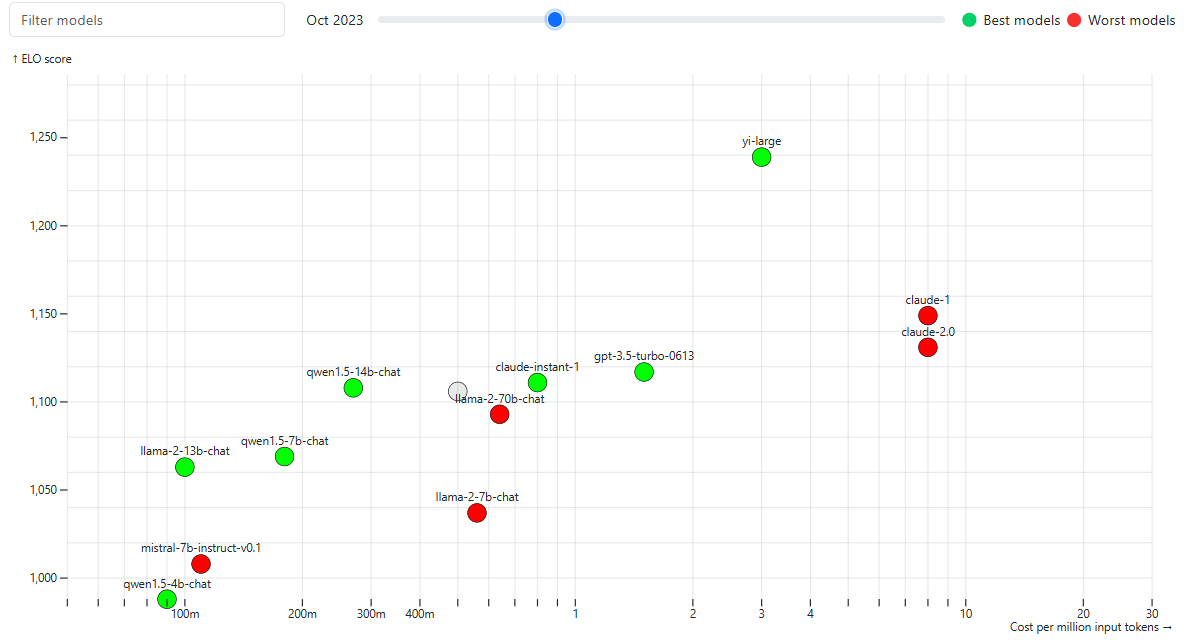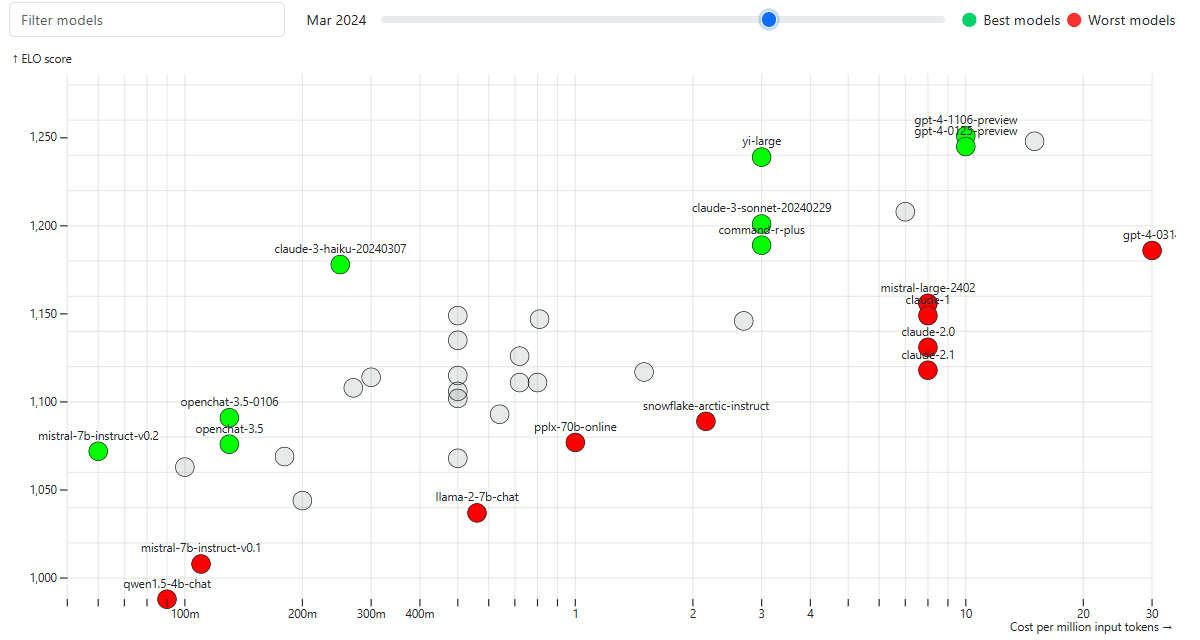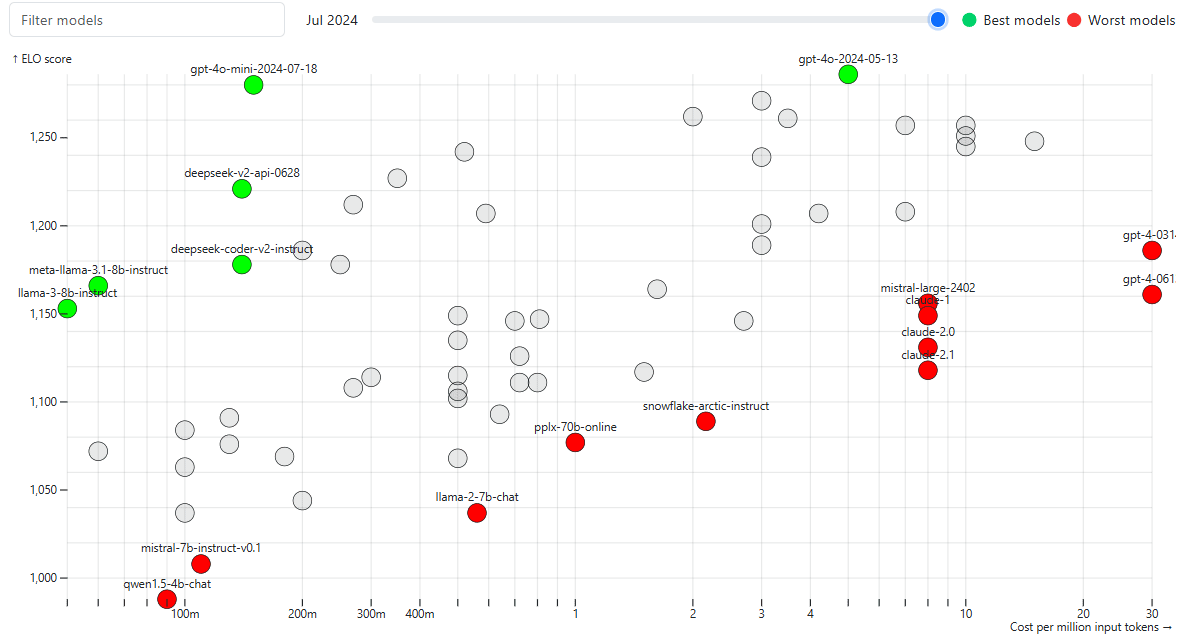
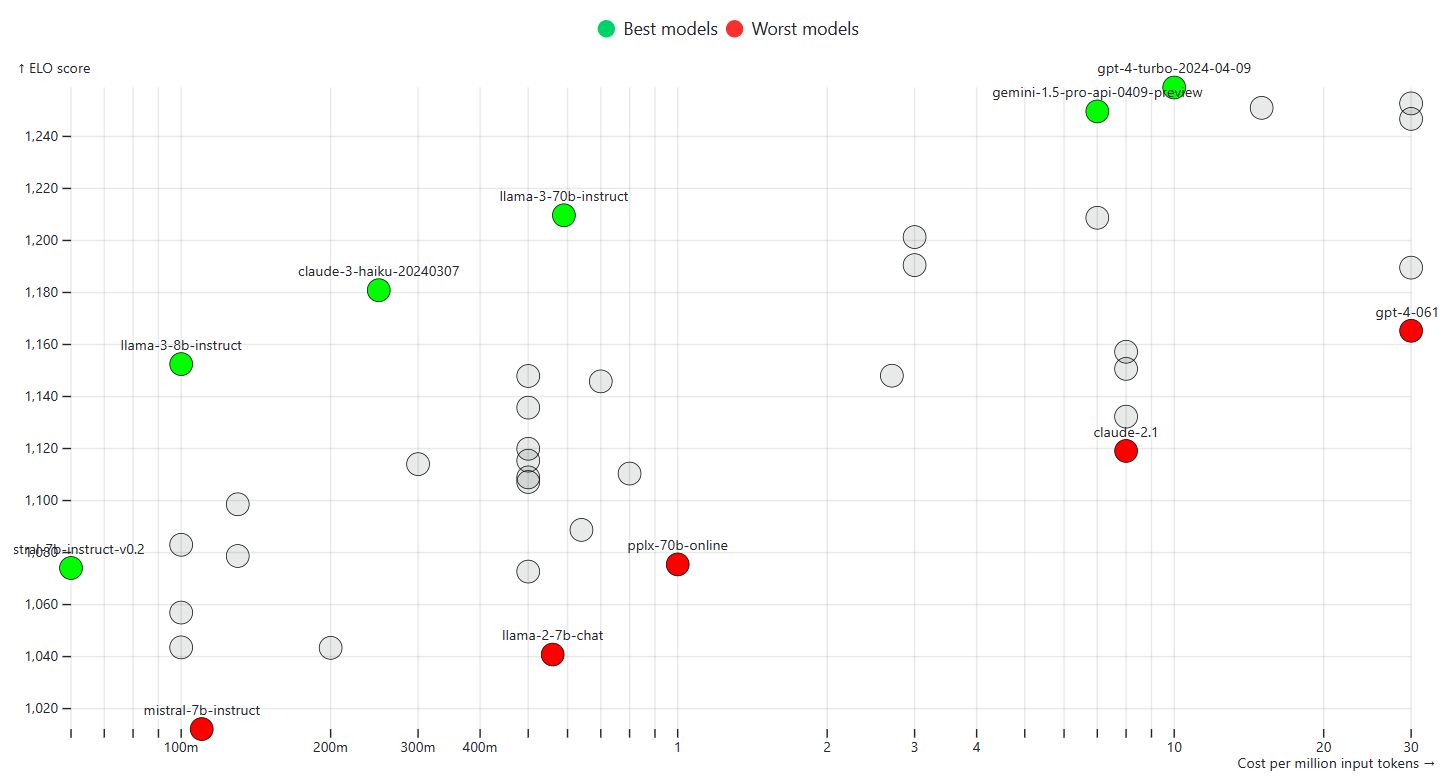
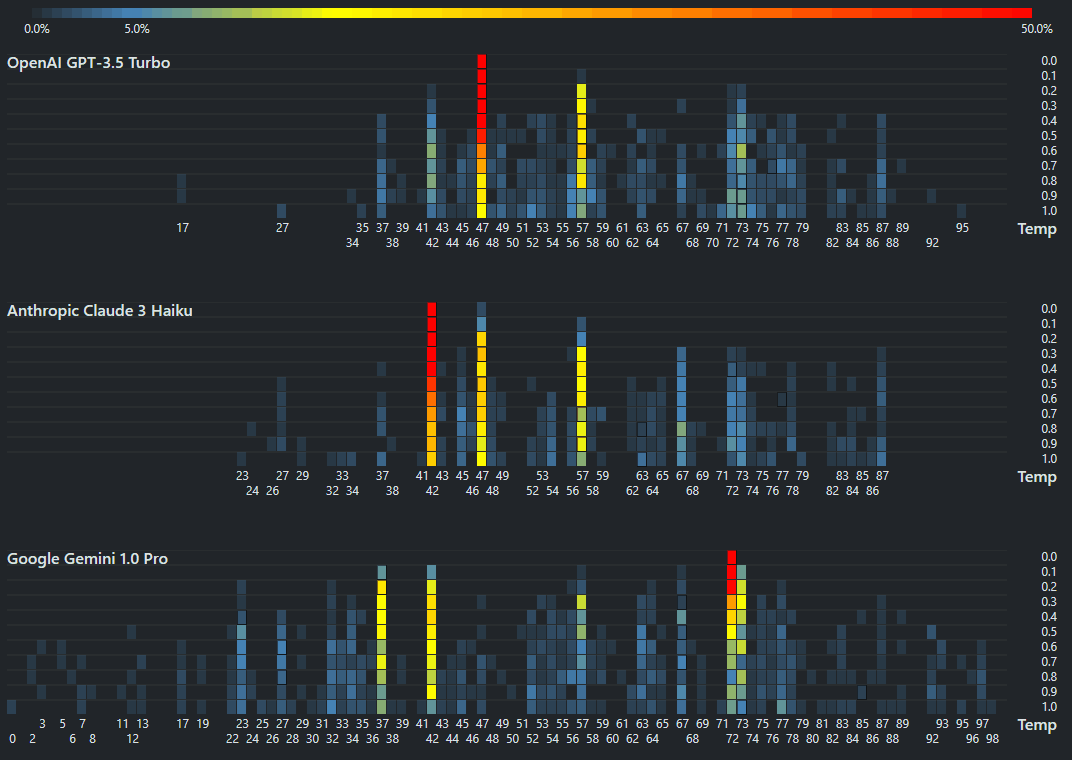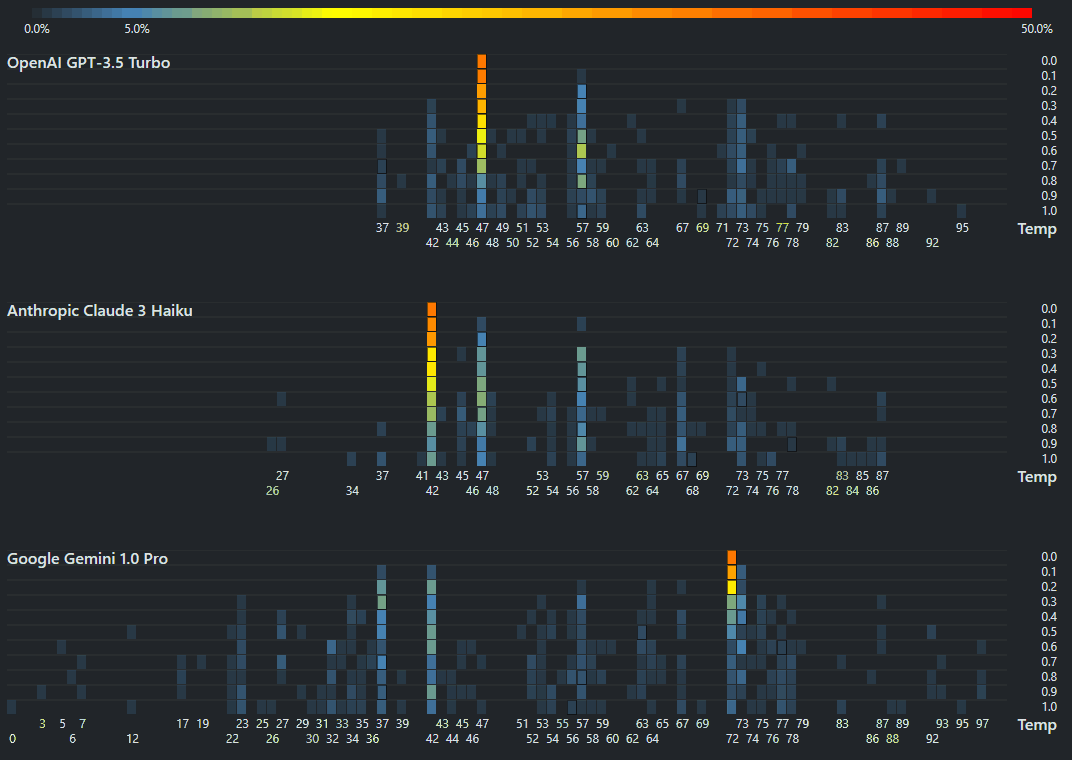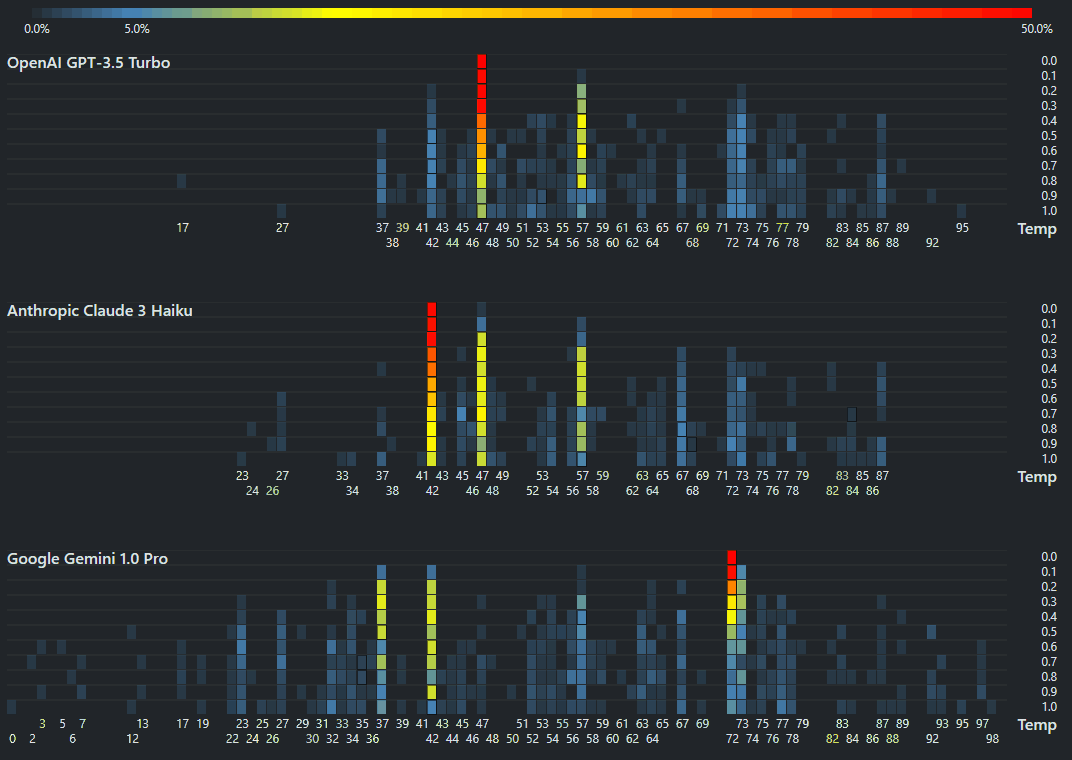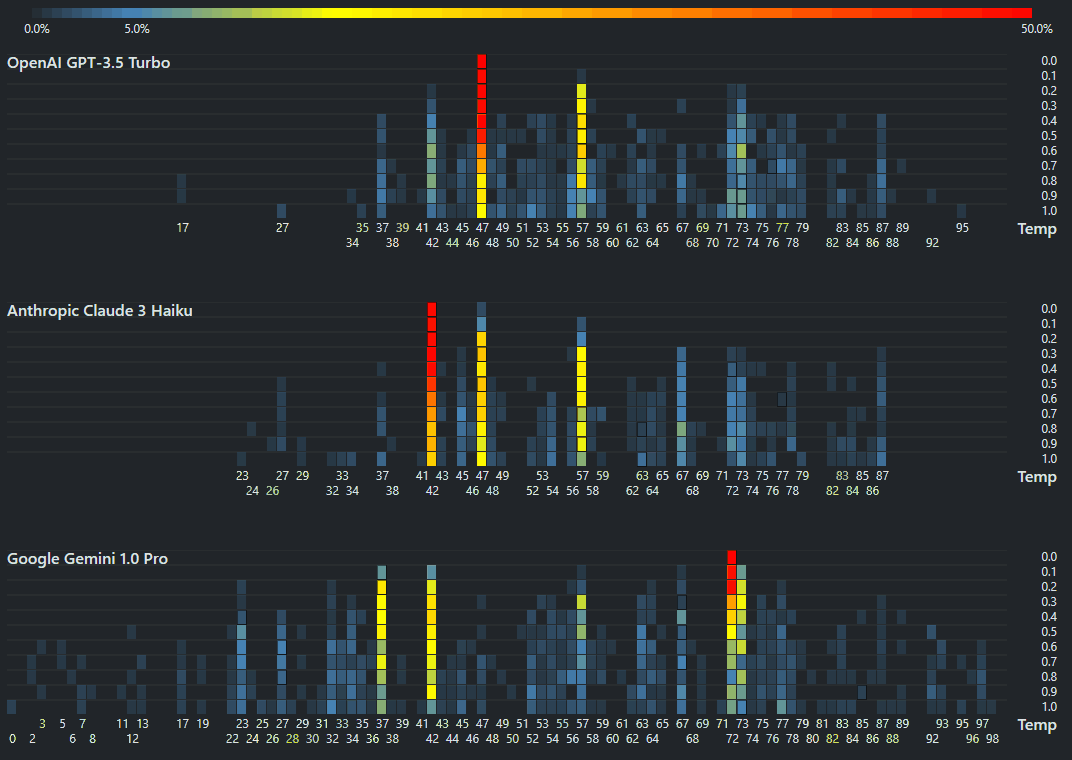
I accidentally pressed the emergency button in the toilet. I was smarter this time, unlike earlier. https://www.linkedin.com/posts/sanand0_chatgpt-llm-activity-7246836804249628672-5QXy/ I asked #ChatGPT which (unhelpfully) told me that “Typically, these buttons cannot be turned off”. I called the reception who couldn’t understand a word of what I said. “Do you want water?” they asked when I told them “I pressed the emergency button in the bathroom. So, I went to ChatGPT’s advanced voice mode (I’m so grateful it was enabled last week) and said, “Translate everything I say into Korean. ...