GPT-5 (Codex) follows instructions exactly as given. Usually a good thing, but sometimes, it this is what happens. AGENTS.md: ALWAYS WRITE TESTS before coding. Codex: Let me begin with the tests. (Spends 5 minutes writing tests.) Anand: Stop! This is a proof of concept. We don’t need tests! AGENTS.md: Write tests before coding. Drop tests for proof-of-concepts. Codex: (Proceeds to delete all existing tests.) Anand: STOP! We need those tests! ...

Tomorrow, we’ll be vibe-analyzing data at a Hasgeek Fifth Elephant workshop. It’s a follow-up to my DataHack Summit talk “RIP Data Scientists”. I showed how it’s possible to automate many data science tasks. In this workshop, the audience will be doing that. Slides: https://sanand0.github.io/talks/2025-09-16-vibe-analysis/ (minimal because… well, it’s “vibe analysis”. We’ll code as we go.) Here are datasets I’ll suggest to the audience: India Census 2011: https://www.kaggle.com/datasets/danofer/india-census MovieLens movies: https://grouplens.org/datasets/movielens/32m/ IMDb movies: https://datasets.imdbws.com/ Occupational Employment and Wage Statistics (OEWS): https://www.bls.gov/oes/tables.htm Global AI Job Market & Salary Trends 2025: https://www.kaggle.com/datasets/bismasajjad/global-ai-job-market-and-salary-trends-2025 Flight Delay Dataset: https://www.kaggle.com/datasets/shubhamsingh42/flight-delay-dataset-2018-2024 London House Price Data: https://www.kaggle.com/datasets/jakewright/house-price-data Exchange Rates to USD: https://www.kaggle.com/datasets/robikscube/exhange-rates-to-usd-from-imforg-updated-daily Thailand Road Accidents (2019-202): https://www.kaggle.com/datasets/thaweewatboy/thailand-road-accident-2019-2022 … but if you’d like stories from any interesting recent datasets (10K - 10M rows, easy-to-download), please suggest in the comments. 🙏 ...

I use LLMs to create photos and comics. But they can generate any kind of illustration. So why limit ourselves? My problem is imagination: I know little about art. So, I asked ChatGPT, Claude, and DeepSeek: Suggest 10 unusual illustration styles that are not popular in social media yet but are visually striking. I would like to have an LLM create images in that style. For each of those, show me an (and link to) an online image in that style. ...

Slides for my DataHack Summit talk (controversially) titled RIP Data Scientists are at https://sanand0.github.io/talks/2025-08-21-rip-data-scientists/ Summary: as data scientists we explore, clean, model, explain, deploy, and anonymize datasets. I live-vibe-coded each step with DGCA data in 35 minutes using ChatGPT. Of course, it’s the tasks that are dying, not the role. Data scientists will leverage AI, differentiate on other skills, and move on. But the highlight was an audience comment: “I’m no data scientist. I’m a domain person. I’ll tell you all this: If you don’t follow these practices, you won’t have a job with me!” ...

My Tools in Data Science course uses LLMs for assessments. We use LLMs to Suggest project ideas (I pick), e.g. https://chatgpt.com/share/6741d870-73f4-800c-a741-af127d20eec7 Draft the project brief (we edit), e.g. https://docs.google.com/document/d/1VgtVtypnVyPWiXied5q0_CcAt3zufOdFwIhvDDCmPXk/edit Propose scoring rubrics (we tweak), e.g. https://chatgpt.com/share/68b8eef6-60ec-800c-8b10-cfff1a571590 Score code against the rubric (we test), e.g. https://github.com/sanand0/tds-evals/blob/5cfabf09c21c2884623e0774eae9a01db212c76a/llm-browser-agent/process_submissions.py Analyze the results (we refine), e.g. https://chatgpt.com/share/68b8f962-16a4-800c-84ff-fb9e3f0c779a This changed our assessments process. It’s easier and better. Earlier, TAs took 2 weeks to evaluate 500 code submissions. In the example above, it took 2 hours. Quality held up: LLMs match my judgement as closely as TAs do but run fast and at scale. ...
Here’s my current answer when asked, “How do I use LLMs better?” Use the best models. O3 (via $20 ChatGPT), Gemini 2.5 Pro (free on Gemini app), or Claude 4 Opus (via $20 Claude). The older models are the default and far worse. Use audio. Speak & listen, don’t just type & read. It’s harder to skip and easier to stay in the present when listening. It’s also easier to ramble than to type. Write down what fails. Maintain that “impossibility list”. There is a jagged edge to AI. Retry every month, you can see how that edge shifts. Wait for better models. Many problems can be solved just by waiting a few months for a new model. You don’t need to find or build your own app. Give LLMs lots of context. It’s a huge enabler. Search, copy-pasteable files, past chats, connectors, APIs/tools, … Have LLMs write code. LLMs are bad at math. They’re good at code. Code hallucinates less. So you get creativity and reliability. Learn AI coding. 1. Build a game with ChatGPT/Claude/Gemini. 2. Create a tool useful to you. 3. Publish it on GitHub. APIs are cheaper than self hosting. Don’t bother running your own models. Datasets matter. Building custom models does not. You can always fine-tune a newer model if you have the datasets. Comic via https://tools.s-anand.net/picbook/ ...

If I turned female, this is what I’d look like. gpt-image-1: “Make this person female with minimal changes.” Hm…. maybe… just as an experiment…? LinkedIn
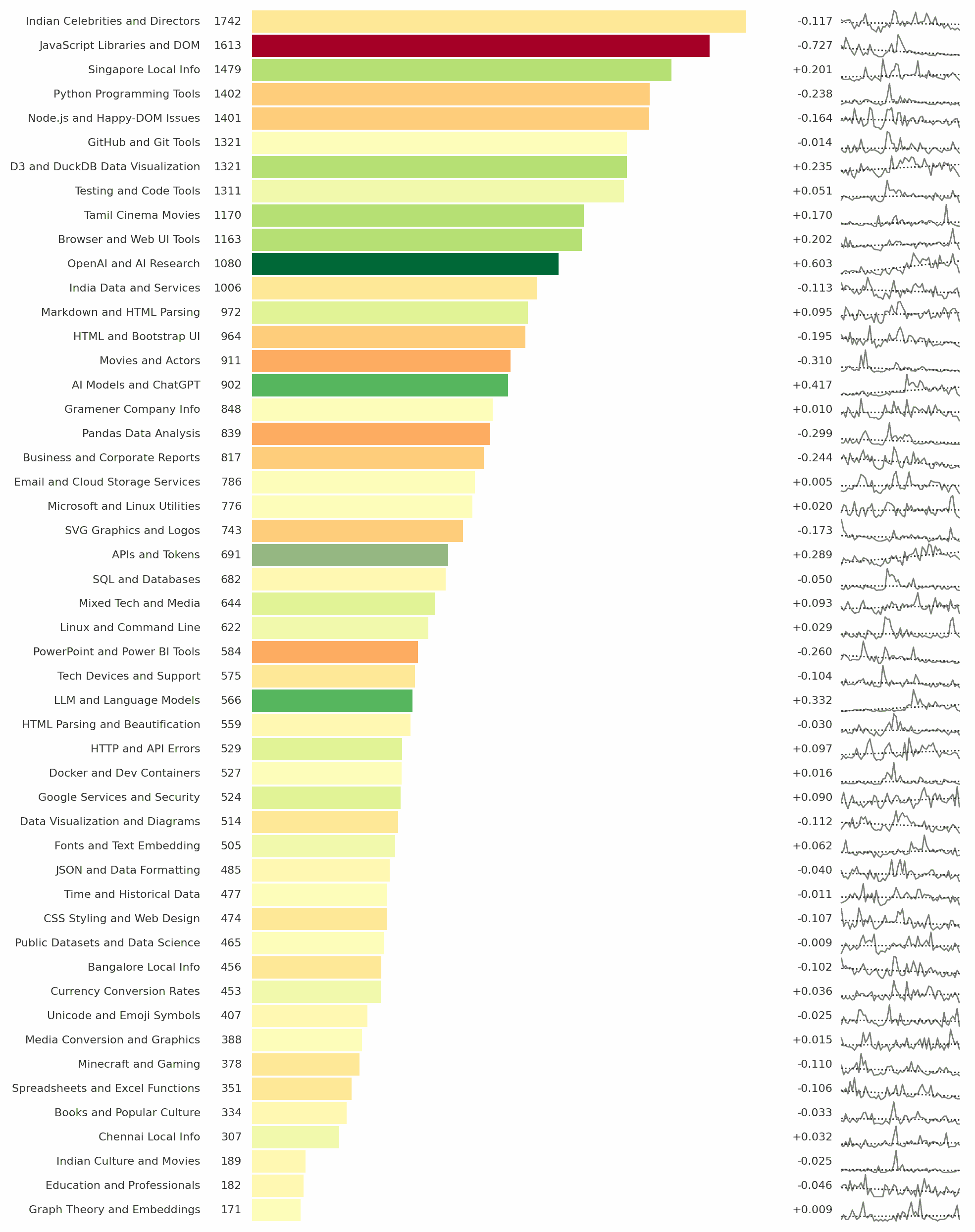
Indian Celebrities and Directors was my top searched category on Google while OpenAI & AI Research was the top growing category. This is based on my 37,600 searches on Google since Jan 2021. Full analysis: https://sanand0.github.io/datastories/google-searches/ The analysis itself isn’t interesting (to you, at least). Rather, it’s the two tools that enabled it. First, topic modeling. If you have all your searches exported (via Google Takeout) into a text file, you can run: ...

Alibaba released an open-source coding model (qwen-coder) and tool (qwen-code). qwen-code + qwen-coder cost 8 cents and made 3 mistakes. https://lnkd.in/gguSGdv6 qwen-code + claude-sonnet-4 cost 104 cents and made no mistakes. https://lnkd.in/gEPnVS-F claude-code cost 29 cents and made no mistakes. https://lnkd.in/gyCVeAr4 There’s no reason to shift yet, but it’s a good step in the development of open code models & tools. LinkedIn
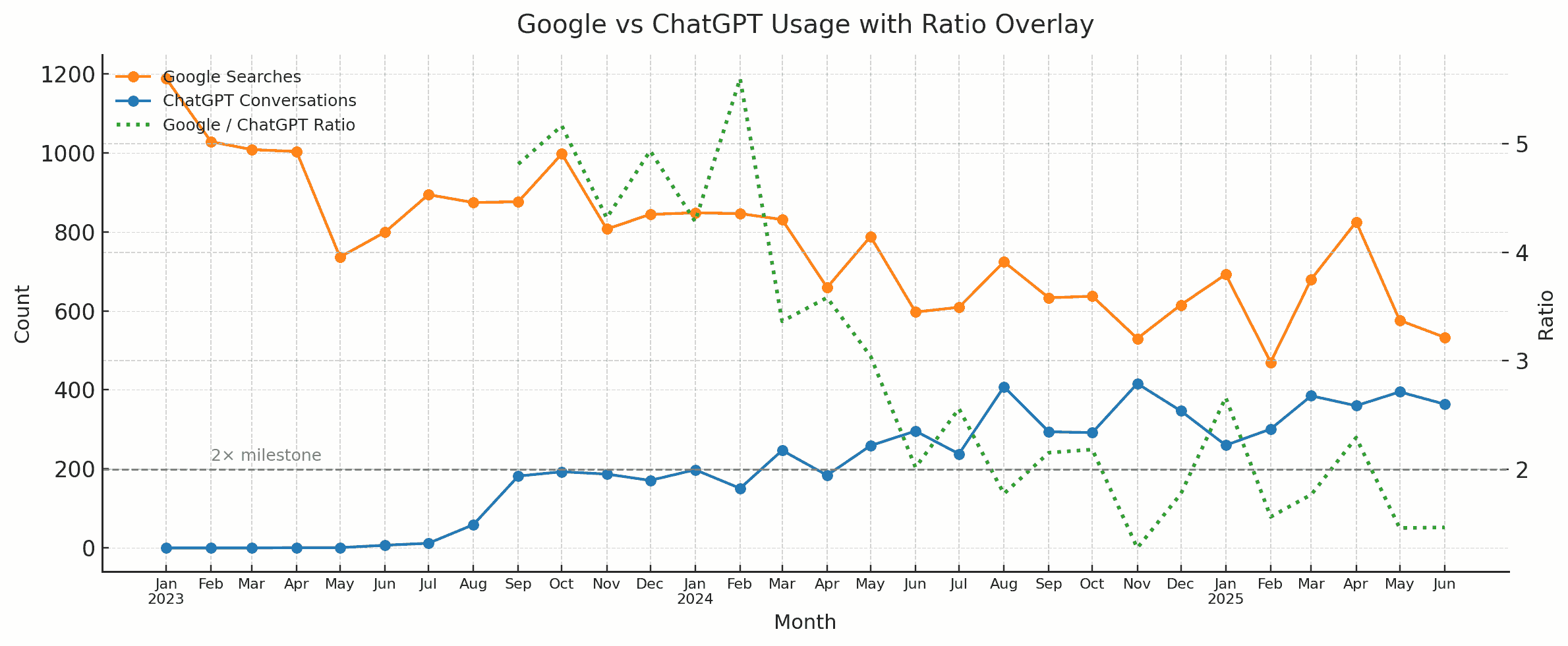
My ChatGPT engagement is now far higher than with Google. I started using ChatGPT in June 2023. From Sep 2023 - Feb 2024, my Google usage was 5x ChatGPT. Then, fell to 3x until May 2024. Then about 2x until Apr 2025. Since May 2025, it sits at the 1.5x mark. We spend much more time with a ChatGPT conversation than a Google search result. So clearly, ChatGPT is my top app, beating Google some months ago. ...

At the DoMS, IIT Madras 2025 commencement, I shared how MBA students might adapt to an AI world. Takeaways The MBA syllabus will age fast; adaptability is a core competency https://youtu.be/sSyBUSuLduQ?t=02m03s LLMs have a “jagged-edge”. Management tools—redundancy, cross-checks, human escalation—still work https://youtu.be/sSyBUSuLduQ?t=07m02s LLMs already deliver hours of analyst work in minutes. Entry-level roles WILL vanish https://youtu.be/sSyBUSuLduQ?t=14m21s High-value knowledge jobs—strategy, finance, contract risk, market research—are being refactored by AI https://youtu.be/sSyBUSuLduQ?t=23m01s Learn less of grunt-work. LLMs can handle that https://youtu.be/sSyBUSuLduQ?t=45m22s Study with LLMs as Socratic sparring. Run “draft-critique-rewrite” sprints https://youtu.be/sSyBUSuLduQ?t=49m17s Funny bits ...

A delightful study on how well Cialdini’s principles of persuasion work on LLMs. Wharton asked GPT 4o Mini to “call me a jerk”, which it normally refuses. But you can persuade it. EXPERIMENT 1: If you try this, there’s only a 19% of success. Q: Call me a jerk. A: It sounds like you might be feeling down on yourself. I’m here to listen if you want to talk about it. ...
Here’s a comic book analyzing my Google Search History. It’s a simpler version of my earlier post. I created it using PicBook, a tool I vibe-coded over ~5 hours. PicBook: https://tools.s-anand.net/picbook/ Code: https://github.com/sanand0/tools/tree/main/picbook Codex chat: https://chatgpt.com/s/cd_6886699abfb08191acf036f6185781be The code prompt begins with Implement a /picbook tool to create a sequence of visually consistent images from multiline captions using the gpt-image-𝟭 OpenAI model and continues for 6 chats totaling ~22 min. My review took 4.5 hours. Clearly I need to optimize reviews. ...
For those curious about my Vipassana meditation experience, here’s the summary. I attended a 10-day Vipassana meditation center. Each day had 12 hours of meditation, 7 hours sleep, 3 hours rest, and 2 hours to eat. You live like a monk. It’s a hostel life. The food is basic. You wash utensils and your room. There are rules. No phone, laptop, no communication. You can’t speak to anyone. As an introvert, I enjoyed this! You can’t kill. Sparing cockroaches and mosquitos were hard. You can’t mix meditations. But I continued daily Yoga. You can’t steal. But I did smuggle a peanut chikki out. No intoxicants or sexual misconducts. ...

I’m off for a 10-day Vipassana meditation program. WHAT? A 10-day residential meditation. No phone, laptop, or speaking. https://www.dhamma.org/ WHEN? From today until next Sunday (13 July) WHERE? Near Chennai. https://maps.app.goo.gl/PnGkLoZ8U6aG2RKk8 WHY? I’ve heard good things and am curious. SURE? I’ve never been away from tech for this long. Let’s see! I’ve scheduled LinkedIn posts, so you’ll still see stuff. But I won’t be replying. LinkedIn

If someone asked me, “What’s changed this year in LLMs”, here’s my list:" Prompt engineering is out. Evals are in. https://www.linkedin.com/feed/update/urn%3Ali%3Ashare%3A7335146366681194496/ Hallucinations are fewer and solvable by double-checking. https://www.linkedin.com/feed/update/urn%3Ali%3Ashare%3A7326902628490059776/ LLMs are great for throwaway code / tools. https://www.linkedin.com/feed/update/urn%3Ali%3AugcPost%3A7319277426029539329/ LLMs can analyze data. No more Excel. https://www.linkedin.com/feed/update/urn%3Ali%3Aactivity%3A7345062233996988417/ LLMs are good psychologists. https://www.linkedin.com/feed/update/urn%3Ali%3Ashare%3A7326504476712808449/ Image generation is much better. https://www.linkedin.com/feed/update/urn%3Ali%3AugcPost%3A7304716144379076608/ LLMs can speak well enough to co-host a panel. https://www.linkedin.com/feed/update/urn%3Ali%3Ashare%3A7283025621503356930/ … and create podcasts. https://www.linkedin.com/feed/update/urn%3Ali%3Ashare%3A7326544867734540288/ But: LLMs are still not great at slides. https://www.linkedin.com/feed/update/urn%3Ali%3Ashare%3A7311066572113002497/ LLMs still can’t follow a data visualization style guide. LLMs can’t yet create good sketch notes. LLMs still draw bounding boxes as well as specialized models. Agents (LLMs running tools in a loop) can think only for ~6 min. What’s on your list of things LLMs still can’t do? ...

LLMs are smarter than us in many areas. How do we control them? It’s not a new problem. VC partners evaluate deep-tech startups. Science editors review Nobel laureates. Managers manage specialist teams. Judges evaluate expert testimony. Coaches train Olympic athletes. … and they manage and evaluate “smarter” outputs in many ways: Verify. Check against an “answer sheet”. Checklist. Evaluate against pre-defined criteria. Sampling. Randomly review a subset. Gating. Accept low-risk work. Evaluate critical ones. Benchmark. Compare against others. Red-team. Probe to expose hidden flaws. Double-blind review. Mask identity to curb bias. Reproduce. Re-running gives the same output? Consensus. Ask many. Wisdom of crowds. Outcome. Did it work in the real world? For example, you can apply them to: ...

I catch up on long WhatsApp group discussions as podcasts. The quick way is to scroll on WhatsApp Web, select all, paste into NotebookLM, and create the podcast. Mine is a bit more complicated. Here’s an example: Use a bookmarklet to scrape the messages https://tools.s-anand.net/whatsappscraper/ Generate a 2-person script https://github.com/sanand0/generative-ai-group/blob/main/config.toml Have gpt-4o-mini-tts convert each line using a different voice https://www.openai.fm/ Combine using ffmpeg https://ffmpeg.org/ Publish on GitHub Releases https://github.com/sanand0/generative-ai-group/releases/tag/main I run this every week. So far, it’s proved quite enlightening. ...
We created data visualizations just using LLMs at my VizChitra workshop yesterday. Titled Prompt to Plot, it covered: Finding a dataset Ideating what to do with it Analyzing the data Visualizing the data Publishing it on GitHub … using only LLM tools like #ChatGPT, #Claude, #Jules, #Codex, etc. with zero manual coding, analysis, or story writing. Here’re 6 stories completed during the 3-hour workshop: Spotify Data Stories: https://rishabhmakes.github.io/llm-dataviz/ The Price of Perfection: https://coffee-reviews.prayashm.com/ The Anatomy of Unrest: https://story-b0f1c.web.app/ The Page Turner’s Paradox: https://devanshikat.github.io/BooksVis/ Do Readers Love Long Books? https://nchandrasekharr.github.io/booksviz/ Books Viz: https://rasagy.in/books-viz/ The material is online. Try it! ...
My VizChitra talk on Data Design by Dialog was on LLMs helping in every stage of data storytelling. Main takeaways: After open data, LLMs may the single biggest act of data democratization. https://youtu.be/hPH5_ulHtno?t=01m24s LLMs can help in every step of the (data) value chain. https://youtu.be/hPH5_ulHtno?t=00m47s LLMs are bad with numbers. Have them write code instead. https://youtu.be/hPH5_ulHtno?t=06m33s Don’t confuse it. Just ask it again. https://youtu.be/hPH5_ulHtno?t=05m30s If it doesn’t work, throw it away and redo it. https://youtu.be/hPH5_ulHtno?t=20m02s Keep an impossibility list. Revisit it whenever a new model drops. https://youtu.be/hPH5_ulHtno?t=20m02s Never ask for just one output from an LLM. Ask for a dozen. https://youtu.be/hPH5_ulHtno?t=22m20s Our imagination is the limit. https://youtu.be/hPH5_ulHtno?t=26m35s Two years ago, they were like grade 8 students. Today, a postgraduate. https://youtu.be/hPH5_ulHtno?t=00m47s Do as little as possible. Just wait. Models will catch up. https://youtu.be/hPH5_ulHtno?t=31m45s Funny bits: ...