Here’s my current answer when asked, “How do I use LLMs better?”
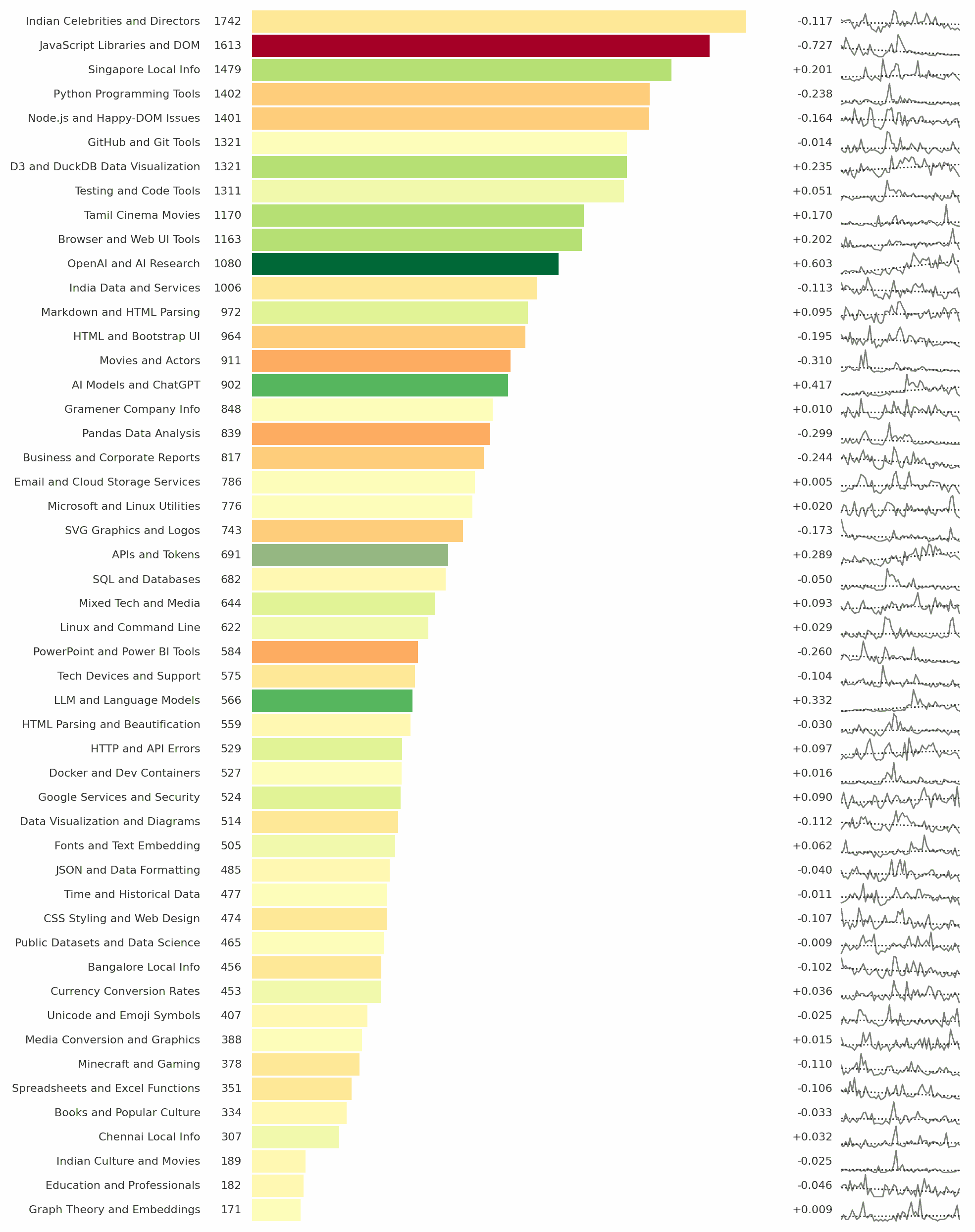
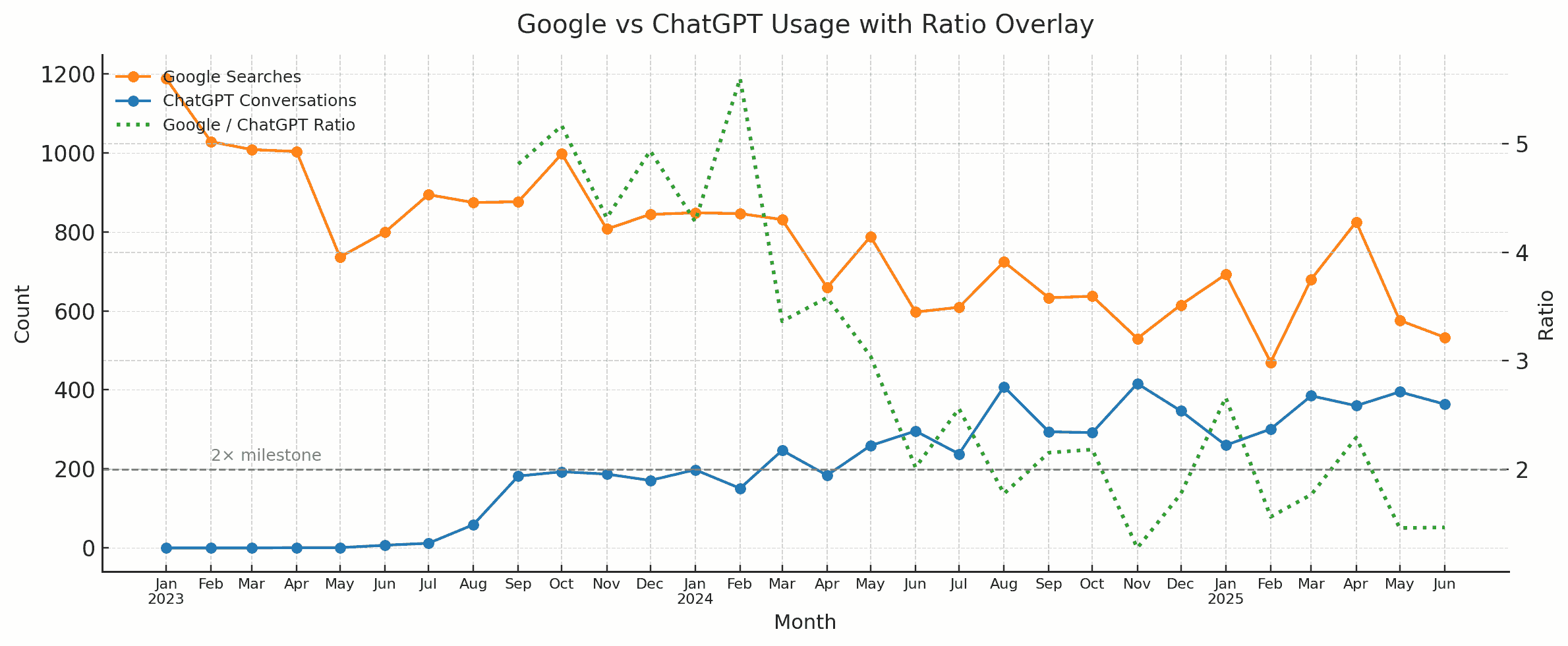
Use the best models. O3 (via $20 ChatGPT), Gemini 2.5 Pro (free on Gemini app), or Claude 4 Opus (via $20 Claude). The older models are the default and far worse. Use audio. Speak & listen, don’t just type & read. It’s harder to skip and easier to stay in the present when listening. It’s also easier to ramble than to type. Write down what fails. Maintain that “impossibility list”. There is a jagged edge to AI. Retry every month, you can see how that edge shifts. Wait for better models. Many problems can be solved just by waiting a few months for a new model. You don’t need to find or build your own app. Give LLMs lots of context. It’s a huge enabler. Search, copy-pasteable files, past chats, connectors, APIs/tools, … Have LLMs write code. LLMs are bad at math. They’re good at code. Code hallucinates less. So you get creativity and reliability. Learn AI coding. 1. Build a game with ChatGPT/Claude/Gemini. 2. Create a tool useful to you. 3. Publish it on GitHub. APIs are cheaper than self hosting. Don’t bother running your own models. Datasets matter. Building custom models does not. You can always fine-tune a newer model if you have the datasets. Comic via https://tools.s-anand.net/picbook/
...