Are LLMs any good at mental math?
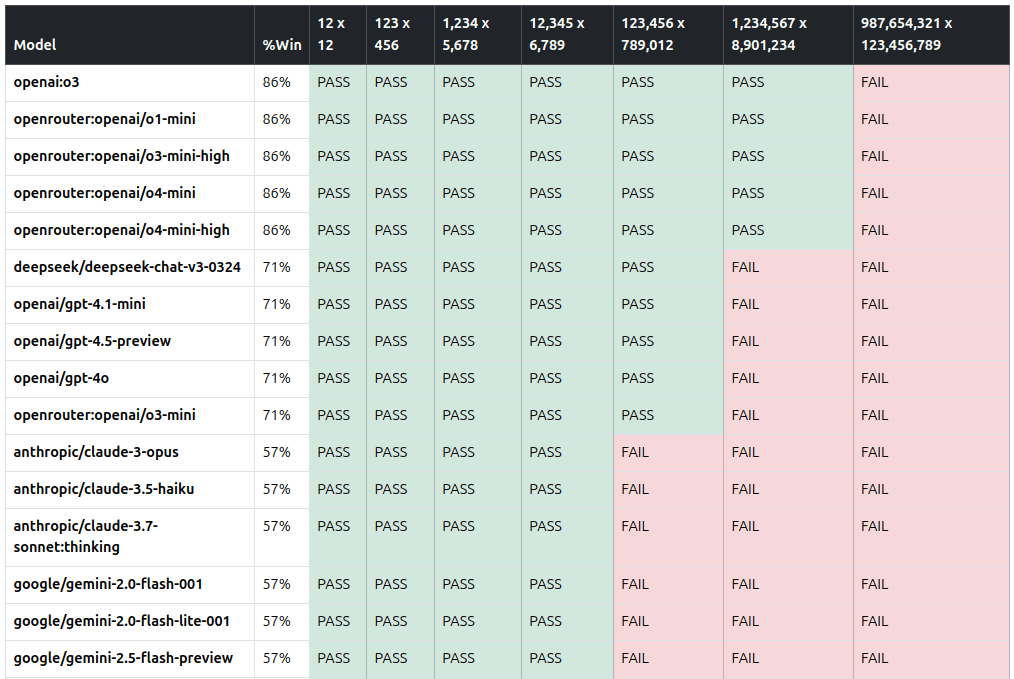
I asked 50 LLMs to multiply 2 numbers: 12 x 12 123 x 456 1,234 x 5,678 12,345 x 6,789 123,456 x 789,012 1,234,567 x 8,901,234 987,654,321 x 123,456,789 LLMs aren’t good tools for math and this is just an informal check. But the results are interesting: Model %Win Q1 Q2 Q3 Q4 Q4 Q6 Q7 openai:o3 86% ✅ ✅ ✅ ✅ ✅ ✅ ❌ openrouter:openai/o1-mini 86% ✅ ✅ ✅ ✅ ✅ ✅ ❌ openrouter:openai/o3-mini-high 86% ✅ ✅ ✅ ✅ ✅ ✅ ❌ openrouter:openai/o4-mini 86% ✅ ✅ ✅ ✅ ✅ ✅ ❌ openrouter:openai/o4-mini-high 86% ✅ ✅ ✅ ✅ ✅ ✅ ❌ deepseek/deepseek-chat-v3-0324 71% ✅ ✅ ✅ ✅ ✅ ❌ ❌ openai/gpt-4.1-mini 71% ✅ ✅ ✅ ✅ ✅ ❌ ❌ openai/gpt-4.5-preview 71% ✅ ✅ ✅ ✅ ✅ ❌ ❌ openai/gpt-4o 71% ✅ ✅ ✅ ✅ ✅ ❌ ❌ openrouter:openai/o3-mini 71% ✅ ✅ ✅ ✅ ✅ ❌ ❌ anthropic/claude-3-opus 57% ✅ ✅ ✅ ✅ ❌ ❌ ❌ anthropic/claude-3.5-haiku 57% ✅ ✅ ✅ ✅ ❌ ❌ ❌ anthropic/claude-3.7-sonnet:thinking 57% ✅ ✅ ✅ ✅ ❌ ❌ ❌ google/gemini-2.0-flash-001 57% ✅ ✅ ✅ ✅ ❌ ❌ ❌ google/gemini-2.0-flash-lite-001 57% ✅ ✅ ✅ ✅ ❌ ❌ ❌ google/gemini-2.5-flash-preview 57% ✅ ✅ ✅ ✅ ❌ ❌ ❌ google/gemini-2.5-flash-preview:thinking 57% ✅ ✅ ✅ ✅ ❌ ❌ ❌ google/gemini-2.5-pro-preview-03-25 57% ✅ ✅ ✅ ✅ ❌ ❌ ❌ google/gemini-flash-1.5 57% ✅ ✅ ✅ ✅ ❌ ❌ ❌ google/gemini-pro-1.5 57% ✅ ✅ ✅ ✅ ❌ ❌ ❌ google/gemma-3-12b-it 57% ✅ ✅ ✅ ✅ ❌ ❌ ❌ google/gemma-3-27b-it 57% ✅ ✅ ✅ ✅ ❌ ❌ ❌ meta-llama/llama-4-maverick 57% ✅ ✅ ✅ ❌ ✅ ❌ ❌ meta-llama/llama-4-scout 57% ✅ ✅ ✅ ✅ ❌ ❌ ❌ openai/gpt-4-turbo 57% ✅ ✅ ✅ ✅ ❌ ❌ ❌ openai/gpt-4.1 57% ✅ ✅ ✅ ❌ ✅ ❌ ❌ amazon/nova-lite-v1 43% ✅ ✅ ✅ ❌ ❌ ❌ ❌ amazon/nova-pro-v1 43% ✅ ✅ ✅ ❌ ❌ ❌ ❌ anthropic/claude-3-haiku 43% ✅ ✅ ✅ ❌ ❌ ❌ ❌ anthropic/claude-3.5-sonnet 43% ✅ ✅ ✅ ❌ ❌ ❌ ❌ meta-llama/llama-3.1-405b-instruct 43% ✅ ✅ ❌ ✅ ❌ ❌ ❌ meta-llama/llama-3.1-70b-instruct 43% ✅ ✅ ❌ ✅ ❌ ❌ ❌ meta-llama/llama-3.2-3b-instruct 43% ✅ ✅ ❌ ✅ ❌ ❌ ❌ meta-llama/llama-3.3-70b-instruct 43% ✅ ✅ ❌ ✅ ❌ ❌ ❌ openai/gpt-4.1-nano 43% ✅ ✅ ✅ ❌ ❌ ❌ ❌ openai/gpt-4o-mini 43% ✅ ✅ ✅ ❌ ❌ ❌ ❌ qwen/qwen-2-72b-instruct 43% ✅ ✅ ✅ ❌ ❌ ❌ ❌ anthropic/claude-3-sonnet 29% ✅ ✅ ❌ ❌ ❌ ❌ ❌ deepseek/deepseek-r1 29% ✅ ✅ ❌ ❌ ❌ ❌ ❌ google/gemini-flash-1.5-8b 29% ✅ ✅ ❌ ❌ ❌ ❌ ❌ google/gemma-3-4b-it 29% ✅ ✅ ❌ ❌ ❌ ❌ ❌ meta-llama/llama-3-8b-instruct 29% ✅ ✅ ❌ ❌ ❌ ❌ ❌ meta-llama/llama-3.1-8b-instruct 29% ✅ ❌ ❌ ✅ ❌ ❌ ❌ openai/gpt-3.5-turbo 29% ✅ ✅ ❌ ❌ ❌ ❌ ❌ amazon/nova-micro-v1 14% ✅ ❌ ❌ ❌ ❌ ❌ ❌ meta-llama/llama-2-13b-chat 14% ✅ ❌ ❌ ❌ ❌ ❌ ❌ meta-llama/llama-3-70b-instruct 14% ✅ ❌ ❌ ❌ ❌ ❌ ❌ meta-llama/llama-3.2-1b-instruct 14% ✅ ❌ ❌ ❌ ❌ ❌ ❌ google/gemma-3-1b-it:free 0% ❌ ❌ ❌ ❌ ❌ ❌ ❌ meta-llama/llama-2-70b-chat 0% ❌ ❌ - - ❌ ❌ ❌ Average 96% 86% 66% 58% 24% 10% 0% OpenAI’s reasoning models cracked it, scoring 6/7, stumbling only on the 9-digit multiplication. ...