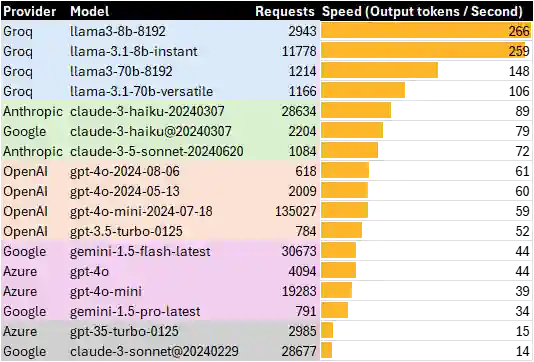
How fast are LLMs in production?
At Straive, we use an LLM Router. Since ChatGPT, etc. are blocked for most people, this is the main way to access LLMs. One thing we measure is the speed of models, i.e. output tokens per second. Fast models deliver a much smoother experience for users. This is a different methodology than ArtificialAnalysis.ai. I’m not looking purely at the generation time but the total time (including making the connection and the initial wait time) for all successful requests. So, if the provider is having a slow day or is slowing down responses, these numbers will be different. ...