For those in #Singapore and interested in #datavisualization & #llms, I’m talking about Visualizing LLM Hallucinations at SUTD on Thu 8 Feb at 7 pm SGT. This is for a non-technical audience. We’ll visualize the basics of how LLMs work, how they make mistakes, and at least one technique on how to spot these. https://www.meetup.com/data-vis-singapore/events/298902921/ LinkedIn
February 2024
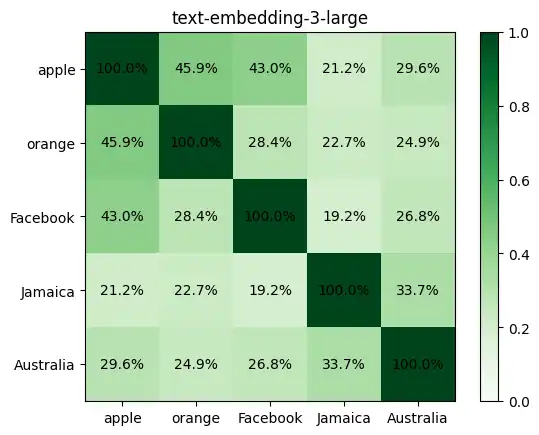
Embeddings similarity threshold
text-embedding-ada-002 used to give high cosine similarity between texts. I used to consider 85% a reasonable threshold for similarity. I almost never got a similarity less than 50%. text-embedding-3-small and text-embedding-3-large give much lower cosine similarities between texts. For example, take these 5 words: “apple”, “orange”, “Facebook”, “Jamaica”, “Australia”. Here is the similarity between every pair of words across the 3 models: For our words, new text-embedding-3-* models have an average similarity of ~43% while the older text-embedding-ada-002 model had ~85%. ...