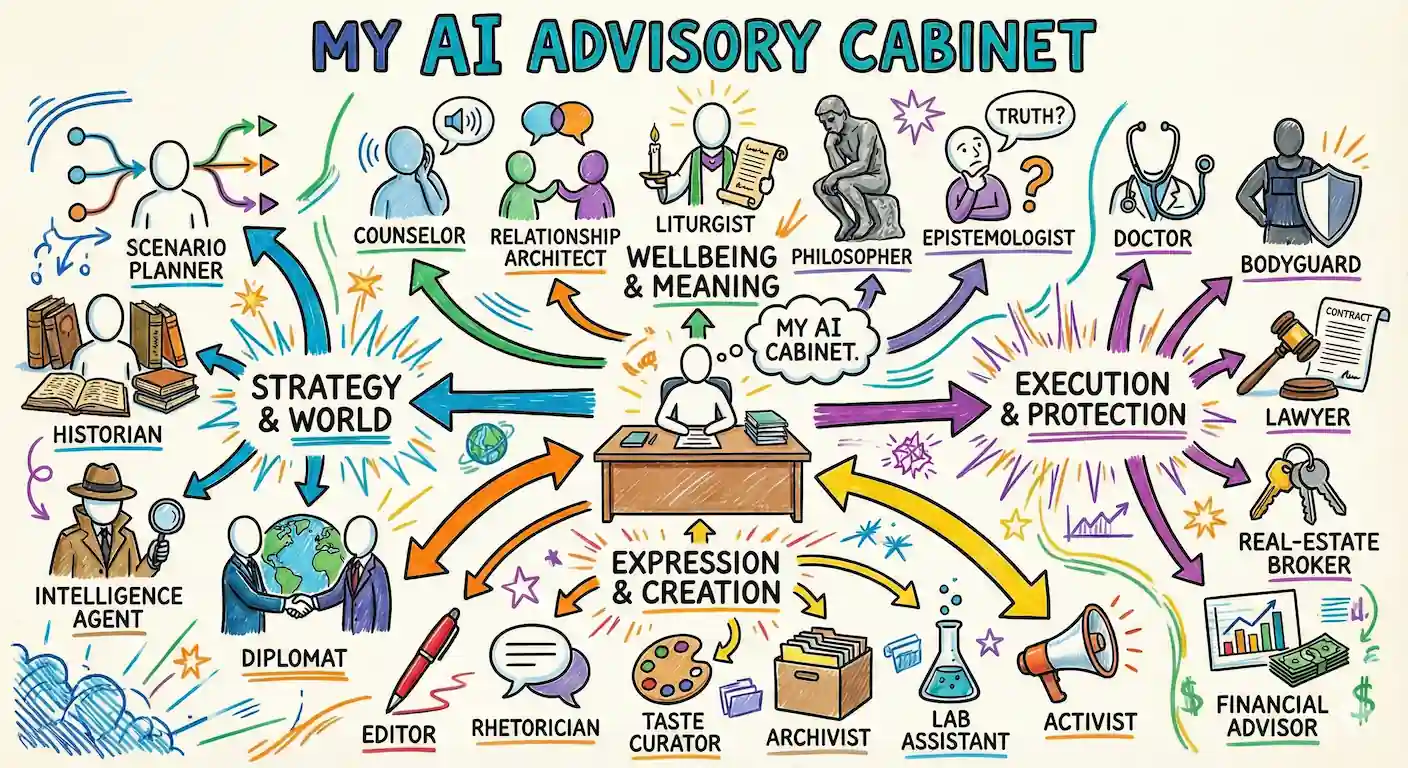
It’s incredible how hostile LinkedIn is for reading / writing content.
Posts containing links to external websites (like my blog) get significantly less reach. That’s why you see links in comments, not the post! You can’t copy content from posts on their mobile app. You can’t even easily select the entire article on the web app! Selecting a part, and then shift-clicking elsewhere (which works almost everywhere) doesn’t work. Also, the copied text isn’t clean. It’s filled with hidden text (e.g. “Skip to search”), duplicated text (e.g. author name repeated), and other junk. It’s hard to export content. For example, the export feature does not include the original links in your articles, nor the links to images you posted! It’s hard to scrape content. LinkedIn actively tries to prevent scraping, and their TOS prohibits it. No formatting. You have to embed unicode characters. Search is terrible. You can’t search for posts by keyword, date, or author easily. No public posting - so you need to log in to read anything. ...