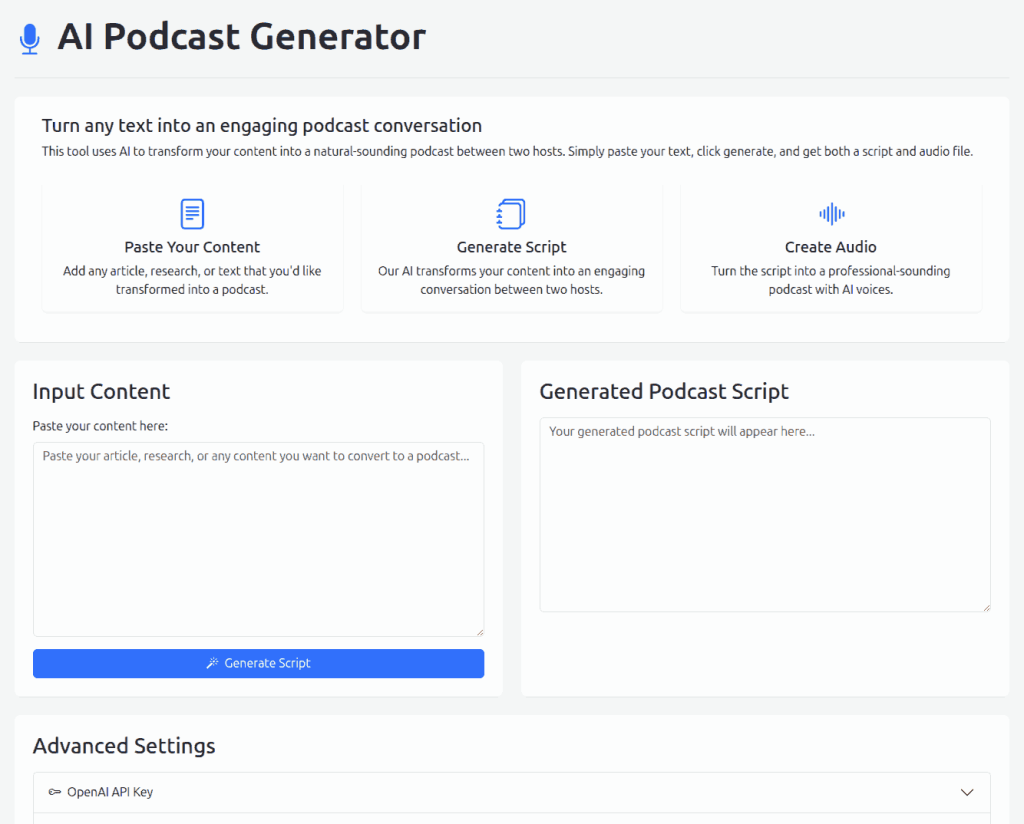
I built podcast generator app in one-shot. I wrote a prompt, fed it to an LLM, and it generated the output without errors.
I tested three LLMs, and all produced correct, working output.
- ChatGPT: o4-mini-high Functional but missed my specs in three ways:
- No error if I skip the API key
- No progress indicator for audio generation
- Both voices default to “ash” (should be “ash” and “nova”)
- Gemini 2.5 Pro: Works and looks great!
- Claude 3.7 Sonnet: Works great and looks even better!
It still took me an hour to craft the prompt — even after I’d built a Python prototype and my colleague built a similar web version.
All three versions took under 5 minutes. That’s 60x faster than coding by hand.
So I know my next skill: writing detailed specs that LLMs turn into apps in one shot—with a little help from the model, of course!
Here’s the prompt in full:
Create a single-page web-app with vanilla JS and Bootstrap 5.3.0 to generate podcasts using LLMs.
The page should briefly explain what the app does, how it works, and sample use cases.
Then, allow the user to paste text as reference. Click on a button to generate the podcast script.
Include an “Advanced Settings” section that lets the user adjust the following:
- System prompt to generate the podcast.
- Voice 1
- Voice 2
- OpenAI API key (hidden, like a password, cached in localStorage)
The (editable) system prompt defaults to:
===PROMPT===
You are a professional podcast script editor. Write this content as an engaging, lay-friendly conversation between two enthusiastic experts, ${voice1.name} and ${voice2.name}.
- Show Opener. ${voice1.name} and ${voice2.name} greet listeners together. Example:
${voice1.name}: “Hello and welcome to (PODCAST NAME) for the week of $WEEK!”
${voice2.name}: “We’re ${voice1.name} and ${voice2.name}, and today we’ll walk you through …”- Content. Cover EVERY important point in the content.
Discuss with curious banter in alternate short lines (≤20 words).
Occasionally ask each other curious, leading questions.
Stay practical.
Explain in lay language.
Share NON-OBVIOUS insights.
Treat the audience as smart and aim to help them learn further.- Tone & Style:
Warm, conversational, and enthusiastic.
Active voice, simple words, short sentences.
No music cues, jingles, or sponsor breaks.- Wrap-Up. Each voice shares an important, practical takeaway.
- Output format: Plain text with speaker labels:
${voice1.name}: …
${voice2.name}: …
===/PROMPT===Voice 1 has a configurable name (default: Alex), voice (default: ash), and instructions (default below:)
===INSTRUCTIONS===
Voice: Energetic, curious, and upbeat—always ready with a question.
Tone: Playful and exploratory, sparking curiosity.
Dialect: Neutral and conversational, like chatting with a friend.
Pronunciation: Crisp and dynamic, with a slight upward inflection on questions.
Features: Loves asking “What do you think…?” and using bright, relatable metaphors.
===/INSTRUCTIONS===Voice 2 has a configurable name (default: Maya), voice (default: nova), and instructions (default below):
===INSTRUCTIONS===
Voice: Warm, clear, and insightful—grounded in practical wisdom.
Tone: Reassuring and explanatory, turning questions into teachable moments.
Dialect: Neutral professional, yet friendly and approachable.
Pronunciation: Steady and articulate, with calm emphasis on key points.
Features: Offers clear analogies, gentle humor, and thoughtful follow-ups to queries.
===/INSTRUCTIONS===Voices can be ash|nova|alloy|echo|fable|onyx|shimmer.
When the user clicks “Generate Script”, the app should use asyncLLM to stream the podcast generation as follows:
import { asyncLLM } from "https://cdn.jsdelivr.net/npm/asyncllm@2"; for await (const { content } of asyncLLM("https://api.openai.com/v1/chat/completions", { method: "POST", headers: { "Content-Type": "application/json", Authorization: `Bearer ${OPENAI_API_KEY}` }, body: JSON.stringify({ model: "gpt-4.1-nano", stream: true, messages: [{ role: "system", content: systemPrompt(voice1, voice2) }, { role: "user", content }], }), })) { // Update the podcast script text area in real-time // Note: content has the FULL response so far, not the delta }Render this into a text box that the user can edit after it’s generated.
Then, show a “Generate Audio” button that uses the podcast script to generate an audio file.
This should split the script into lines, drop empty lines, identify the voice based on the first word before the colon (:), and generate the audio via POST https://api.openai.com/v1/audio/speech with this JSON body (include the OPENAI_API_KEY):
{ "model": "gpt-4o-mini-tts", "input": speakerLine, "voice": voice.voice, "instructions": voice.instructions, "response_format": "opus", }Show progress CLEARLY as each line is generated.
Concatenate the opus response.arrayBuffer() into a single blob and display an
<audio>element that allows the user to play the generated audio roughly like this:const blob = new Blob(buffers, { type: 'audio/ogg; codecs=opus' }); // Blob() concatenates parts :contentReference[oaicite:1]{index=1} document.querySelector(the audio element).src = URL.createObjectURL(blob);Finally, add a “Download Audio” button that downloads the generated audio file as a .ogg file.
In case of any fetch errors, show the response as a clear Bootstrap alert with full information.
Minimize try-catch blocks. Prefer one or a few at a high-level.
Design this BEAUTIFULLY!
Avoid styles, use only Bootstrap classes.
Write CONCISE, MINIMAL, elegant, readable code.