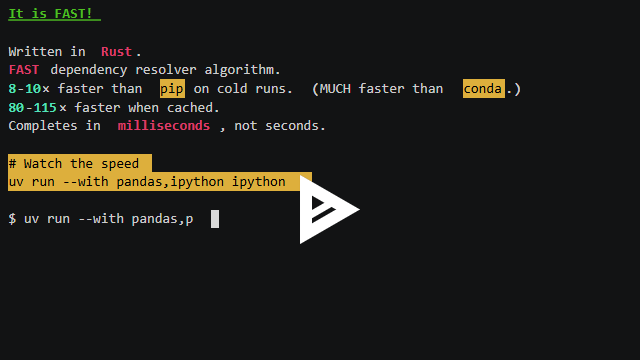
This week, I learned:
Lessons from discussions at IIT Madras: Even in recorded video tutorials, asking students a question and pausing to give them time to think can be effective. When you put students in front of real clients, engagement increases dramatically. Most teaching assistants would like to help diligent students among the bottom half (more than the top decile of students). However, there is a fraction of poor performers who do not care, and are best ignored. Their engagement and effort is a good measure of their interest. Defining a minimal set of principles that we want to teach helps us measure if we’ve helped the bottom half at least meet those objectives. Teaching is hard. Even after explanations, students, even ENGAGED students, tend to make basic mistakes ChatGPT does a good job of spotting errors in architectural and structural diagrams. In fact, the whole theme of spotting errors in large diagram is a theme that can have potential use cases. Source: Dan Becker. R1 seems good at text-to-CAD. Even better than Sonnet. Source: Dan Becker OpenAI advices a few different prompting techniques for reasoning models. OpenAI: Avoid examples unless zero-shot prompting fails. Avoid chain-of-thought. These models do that internally anyway. Short, direct prompts are better than detailed prompts. GitHub models is free for anyone to try. The model catalog us extensive and even includes o3-mini which was launched this week (though in limited preview). The data catalog space is led by proprietary solutions: Alation Data Catalog: Market leader; growing steadily in enterprise use Collibra Data Catalog: Widely adopted with steady growth AWS Glue Data Catalog: Growing rapidly as AWS expands its data services Informatica Enterprise Data Catalog: Long established and stable, though facing newer alternatives Microsoft Purview Unified Catalog: Experiencing fast growth driven by cloud momentum Atlan Data Catalog: Relatively new but gaining fast traction among tech-forward organizations OpusClip automatically creates short clips from long videos. I ran it on Programming Minecraft with WebSockets in Python to get this short 30-second clip. 30 minutes. 100% automated. Alternatives to Postman: Hoppscotch – A web‑based/desktop API client supporting REST, GraphQL, and WebSockets. It’s lightweight, open-source, and self‑hostable. HTTPie – A web-based API along with a friendly command-line tool for API interaction. Insomnia (or its fork Insomnium) – A popular cross‑platform API client with a minimal interface and plugin ecosystem. Bruno – A desktop open-source API client that stores collections as files (ideal for Git versioning). Milkman – A desktop open‑source workbench for managing API requests. Here is the summary of DuckCon #6 on 31 Jan 2025 in Amsterdam. I copied the transcript from YouTubeTranscript and passed it through Gemini 2.0 Flash Exp with the system prompt: “Summarize this transcript from the DuckDB conference without missing any points. Cover every point mentioned. A lot of spelling errors that sound like DuckDB are likely to be DuckDB”. Introduction & Welcome: DuckCon #6: This is the 6th DuckDB conference, held in their hometown. The first DuckCon was online due to the pandemic. Live Streaming: This is the first time DuckCon is being live-streamed, chosen to accommodate global time zones (especially China and the US). Global Reach: The live stream is intended to reach users in areas where in-person DuckCons are unlikely. Q&A: Slido (qa.duckdb.org) will be used for Q&A, with upvoting to prioritize questions. Sponsors: Thanks to gold sponsor monday.com and silver sponsors Real and Crunchy Data. DuckCon Purpose: DuckCon is a place for users to connect, share experiences, and provide feedback to the DuckDB team. Inspiration: The team is inspired by the community’s use of DuckDB and how far the project has come. Mission Statement: DuckDB aims to make large datasets less intimidating and more accessible, moving away from fear of data to confidence in handling it. Motivation: The project was born from seeing people struggle with data that didn’t fit in Excel and the lack of user-friendly tools. Industry Trends: Single-node processing capabilities have grown faster than the size of useful datasets. Data Singularity: A prediction that most data analysis queries can run on a single node is now a reality. Real-World Data Sizes: Analysis of Snowflake and Redshift data shows that 99.9% of datasets are under 300GB. Raspberry Pi Benchmark: The industry-standard TPCH benchmark (scale factor 300, ~300GB) can run on a Raspberry Pi using DuckDB. Single Node Growth: Single-node processing power is rapidly increasing, allowing for larger datasets to be handled. Adoption Numbers: 32 Million Extension Installs: 32 million DuckDB extension installs in the last month. 1.8 Million Unique Website Visitors: 1.8 million unique visitors per month to the DuckDB website. Blue Sky Community: Growing community on Blue Sky, with the hashtag #dataBS. Technical Updates (Mark): Extension Ecosystem: Focus on enabling the community to build and share extensions. Community Extensions: Making it easier to create and use community-built extensions. DuckDB v1.2 (Harlequin Duck): Releasing next week, named after the Harlequin duck. CSV Reader Improvements: Significant improvements to the CSV reader. Friendlier SQL: Improvements to the SQL experience. CLI Autocomplete: Reworked and improved CLI autocomplete. Performance Optimizations: Many queries are now faster due to performance work. C API for Extensions: Introducing a C API to make building extensions easier. Logging Features: Improved logging for production use. Lakehouse Focus: The main focus for the year is on lakehouse formats and related features. Q&A (Mark & Hanis): Doubling Team: If the team doubled, they would focus on client integrations and other projects, not a major architectural change. Partitioning: Near-term plans to add support for partitioning, related to lakehouse formats. DuckDB WASM: The WASM ecosystem is evolving, with exciting possibilities for in-browser use. Financial/Pharmaceutical Industries: DuckDB could replace some SAS workflows due to its cost-effectiveness and capabilities. Lakehouse & MotherDuck: Lakehouse work is separate from MotherDuck, though MotherDuck will likely support lakehouse features. Contributing to Extensions: Plans to make it easier to contribute to extensions, including support for Rust and Go. Airport Extension (Rusty): Analogy: The airport extension allows DuckDB to “fly” to remote servers using Apache Arrow Flight. Functionality: Supports select, insert, update, and delete operations on remote data sources. Motivation: To reduce the burden of writing extensions and enable faster development using existing code. Arrow Flight: Uses Arrow Flight for communication, enabling connections to various data sources. Demo 1: Delta Lake: Attaches to a flight server for Delta Lake access. Allows creating schemas, tables, and performing standard SQL operations. Uses Python and deltars (Rust implementation of Delta Lake). Supports predicate pushdown and C integration with the DuckDB catalog. Demo 2: AutoGluon: Integrates the AutoGluon AutoML package. Predicts Hacker News post votes using a trained model. Demonstrates table-returning functions for model fitting and prediction. No C++ code required, just Python. Demo 3: Geocoding: Uses a geocoder service to convert addresses to coordinates and vice versa. Demonstrates scalar UDFs for vectorized requests. Uses a Python example for a simple uppercase function. Features: List flights, take flights. Catalog integration. Select, update, delete. Scalar UDFs. Table in/out functions. Authentication for row/column filtering. Availability: Requires DuckDB 1.2, MIT licensed, available on GitHub. Q&A (Rusty): Most Proud Extension: Airport is the most fun, but the AWS API wrapper also brings joy. Extension Resources: The GitHub DuckDB extension template and reading others’ source code are helpful. Airport & Other Extensions: Airport is separate and can be used alongside other extensions like spatial or httpfs. Graph Support: Graph database support is planned, with examples like Kuzu, Neptune, and Neo4j. Licensing: Airport is MIT licensed, compatible with Apache license. Scaling Out: Airport can be used to query multiple DuckDB instances on different machines. Ibis & Geospatial (Nati): Nati Clementi: Senior software engineer at Nvidia, working on open-source projects like Ibis. Ibis: Open-source Python library for data wrangling, with a DataFrame API and interfaces to 15+ engines, including DuckDB. DuckDB for Geospatial: DuckDB is fast, has a geospatial extension, and supports various geospatial formats. Geop Parquet: Becoming a standard for geospatial data, enabling cloud data warehouse interoperability and compression. Geo Arrow: A way of representing geospatial vector data in memory for faster processing. Ibis Benefits: Allows writing Python instead of SQL, with deferred execution determined by the engine. Demo: Uses OverTour Maps data in geop parquet format. Filters data using bounding boxes. Demonstrates geospatial operations like ST_Distance and ST_Transform. Plots data using Lumber. Shows how to find points of interest near a location (e.g., the Van Gogh Museum). Ibis & DuckDB: Ibis uses DuckDB for the parquet reader and lets DuckDB do the heavy lifting. Ibis Optimizations: Ibis does type checking but doesn’t do query optimization, leaving that to the engine. Ibis in Browser: Ibis works in the browser through DuckDB WASM. Q&A (Nati): Linear Interpolation: Ibis ML module can help with regression-related tasks. Missing Features: No major features are missing in the DuckDB/Ibis geospatial setup, with minimal overhead. Parquet Reader: Ibis uses DuckDB’s parquet reader. Query Optimization: Ibis does not optimize SQL queries, leaving that to DuckDB. Ibis in Browser: Ibis works in the browser through DuckDB WASM. Rill & Metrics Layer (Mike): Rill: A BI tool optimized for DuckDB, with instant slicing and dicing, BI as code, and a metrics-first philosophy. Metrics-First: Design metrics models, and Rill autogenerates dashboards and user experiences. Live Demo: Downloaded Rill using a curl command. Created a new project called “DuckCon 6”. Imported a parquet file of GitHub commit data. Used AI to generate a metrics model and dashboard. Showed the dashboard with trends and filtering. Metrics as Building Blocks: Metrics are flexible, fast, and intuitive. SQL for Metrics: Metrics should be defined in SQL, not other languages. Visual Metrics Editor: Rill has a visual editor for defining metrics using DuckDB SQL. Metric Stack: Legacy: Data warehouses, traditional BI tools, inconsistent metrics, full table scans. DuckDB Powered: Consistent metrics, fast olap queries, SQL everywhere. Challenges: Data modeling is hard, metric changes can be expensive, single-node scale has limits. AI & Metrics: AI can assist in metrics modeling, optimization, and conversational data exploration. Q&A (Mike): Complex Metrics: Rill works well with complex metrics involving multiple sources and transformations by joining tables in DuckDB. 60 FPS Dashboards: Users can feel the difference with faster dashboards. Defining Metrics: Metrics are defined in the Rill UI using SQL expressions. Replacing ChatGPT: Considering locally run self-hosted models for privacy. Stock Data Analysis (Ryan): Two Takeaways: Simple finance data flows with trade data and a tool called Q Studio. Ryan Hamilton: 14 years building large data platforms in banks. Bank Data: Data from exchanges, market data providers, and internal systems. Use Cases: Backtesting, data analysis, and report generation. Q Studio: A Java desktop application that connects to 30 databases, including DuckDB. Demo: Loaded a 6GB CSV file of trade data into DuckDB. Showed basic queries, pivoting, and Candlestick charts. Demonstrated time-based aggregation and moving averages. Showed a basic trading strategy using window functions. DuckDB Benefits: Fast, easy to use, great for time-based analysis. Q&A (Ryan): KDB+ vs. DuckDB: KDB+ is for large data, DuckDB is more approachable with strong Python integration. XML Files: Offloading processing to DuckDB, not planning XML integration. Lightning Talks: Zuk (Jared): Search engine research using DuckDB. Python-based experiments with SQL. Removing document lengths for faster search engines. DuckPGQ (Daniel): Graph analytics in DuckDB using SQL property graph queries (pgq). Visual graph syntax for pattern matching and path finding. Outperforms Neo4j on analytical queries. Yat (Kristoff): Smallest DuckDB SQL orchestrator. Runs SQL queries in a folder in the correct order. Generates a mermaid diagram for lineage. Grafana & DuckDB (Sam): Lessons learned from using DuckDB in Grafana. Security incident due to shell commands and file access. Importance of reading the documentation. Cloud Slur (Adam): Syncing query engine for bank transaction data. Uses LLM to convert human language to SQL. Uses DuckDB in the browser, Node.js, and Python. Healthcare Data (Tony): Data engineering use cases in healthcare. Dynamic data masking system using DuckDB and Snowflake. Data integration pipeline using DuckDB and Arrow streams. Closing Remarks: Michel Simmons: Author of the DuckDB in Action book, will be signing books. Poster Session: A poster session will follow the talks. Sponsors: Thanks again to the sponsors. Social Event: The conference will now move to the social event. ibis is a Python library that works with multiple dataframe backends like DuckDB, Polars, and Pandas. With just 3 annotators and 50-100 samples, you can figure out if an LLM can replace human annotators systematically.Arxiv ChatGPT explanation Curiosity and agency may be the differentiator in a world of LLMs (not experience, knowledge, or ability), since LLMs will democratize expertise. Jack Clark “AI/human combined work can be copyrighted as long as a human is adding, changing or selecting elements. Prompts alone do not usually produce copyrighted work.” - Copyright and Artificial Intelligence, Jan 2025, US Copyright Office via Ethan Mollick Human Authorship is Essential: Works created solely by AI are not copyrightable. AI can be used as a Tool: Using AI as a tool does not negate copyright protection, as long as the final work reflects sufficient human creativity. Prompts Alone are Insufficient: Simply providing prompts to an AI system, even detailed ones, is generally not enough to establish authorship. Prompts are considered instructions or ideas, which are not copyrightable. Expressive Inputs: When a human author provides their own expressive content (like a drawing, photo, or text) as input to an AI system, and that content is perceptible in the output, the human author can claim copyright in that portion of the output. Modifying and Arranging AI-Generated Content: Humans can claim copyright in the creative selection, coordination, and arrangement of AI-generated material, as well as in creative modifications to AI-generated outputs. No Need for New Legislation: The report concludes that existing copyright law is adequate to address the copyrightability of AI-generated works, and no new legislation is needed at this time. Case-by-Case Analysis: Copyrightability will be determined on a case-by-case basis, considering the specific facts of each work and the extent of human contribution.