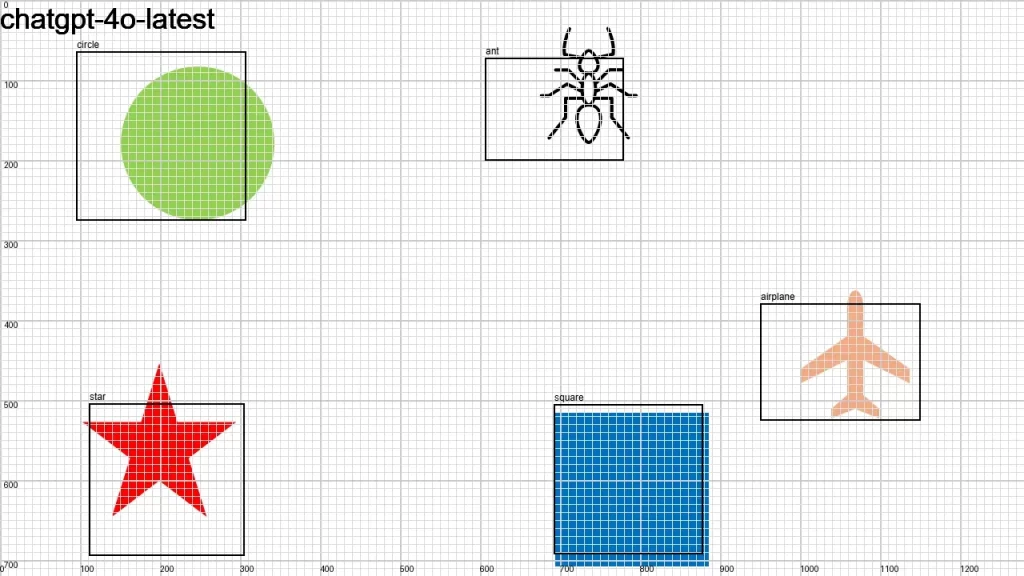
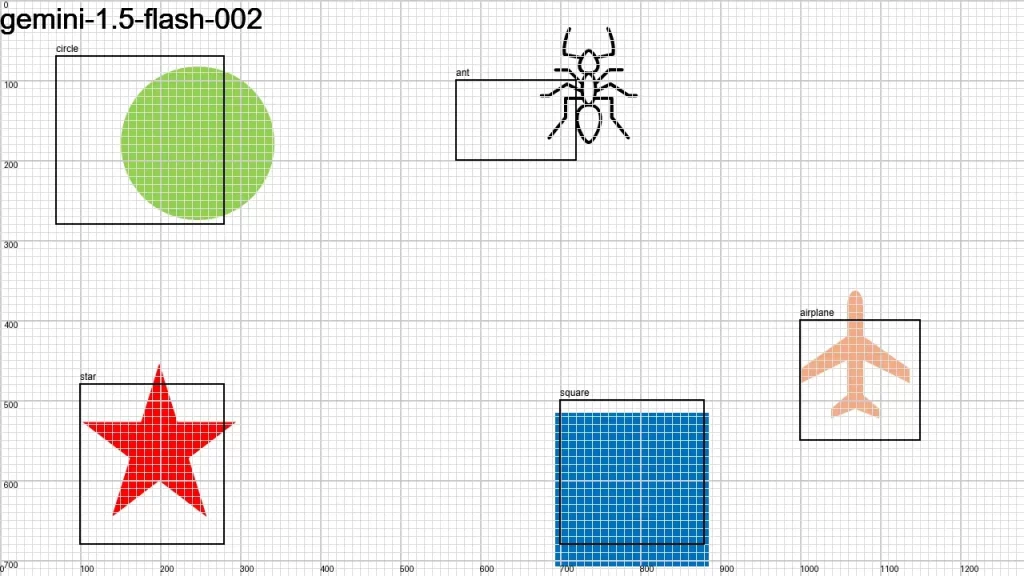
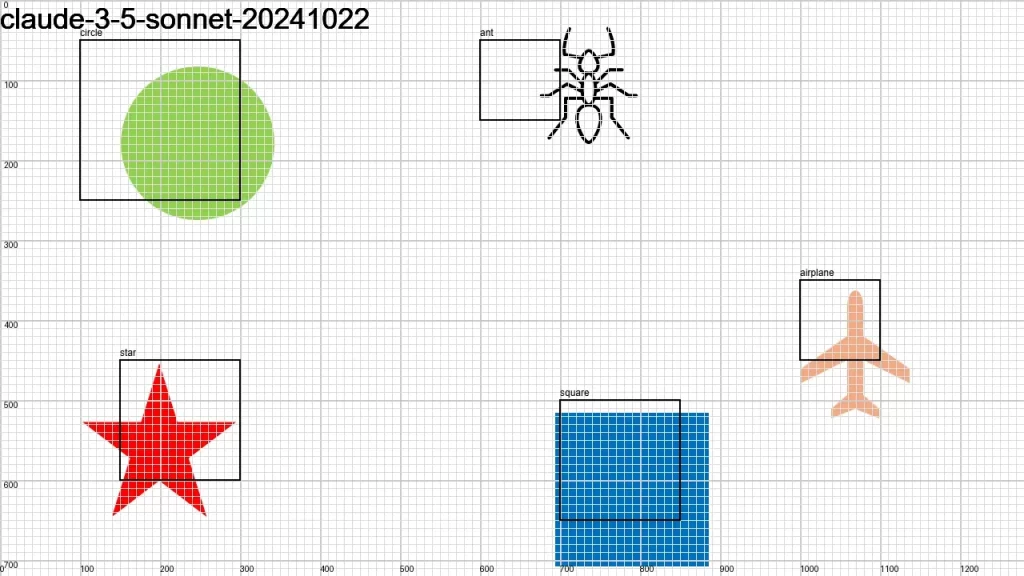
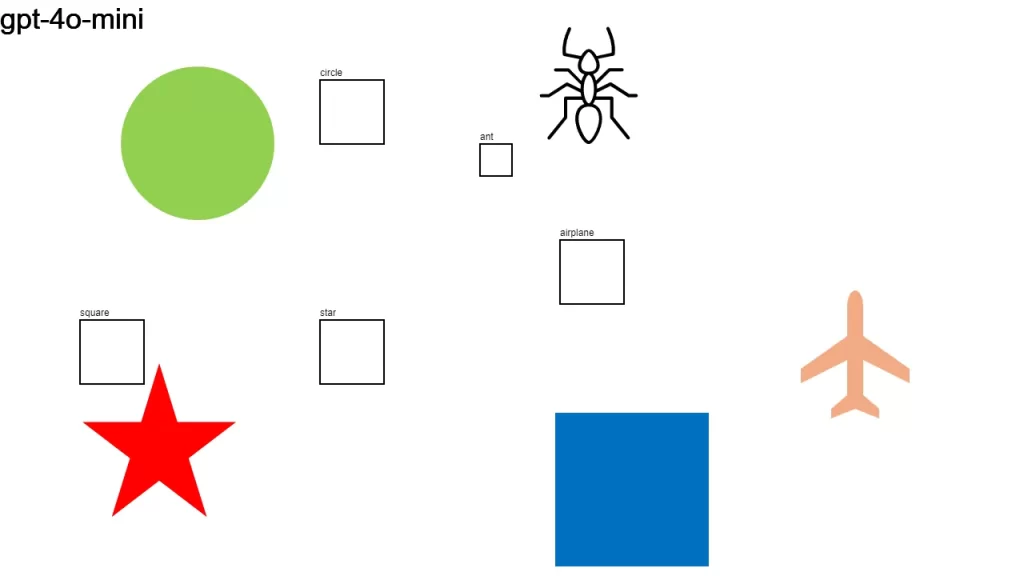
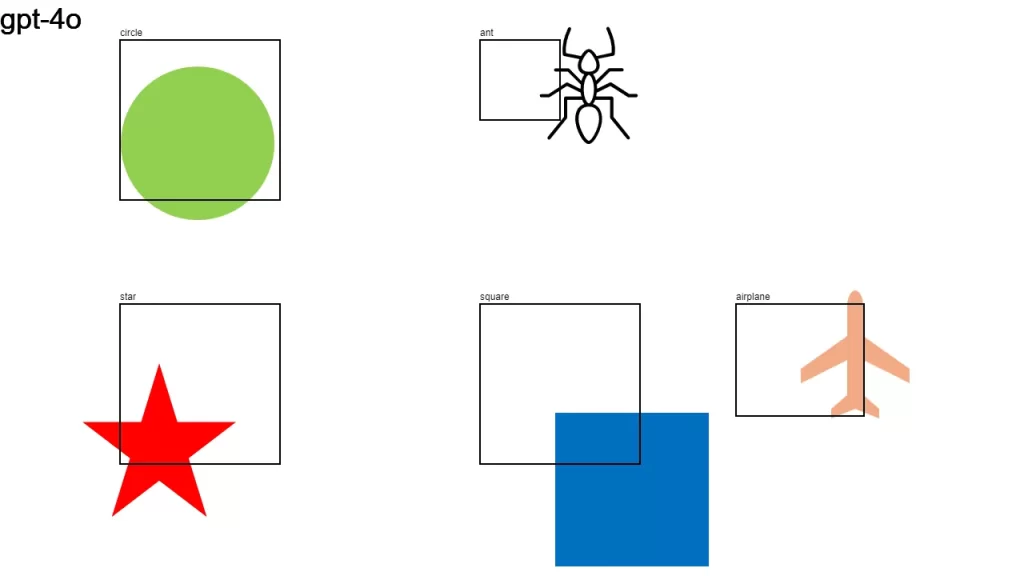
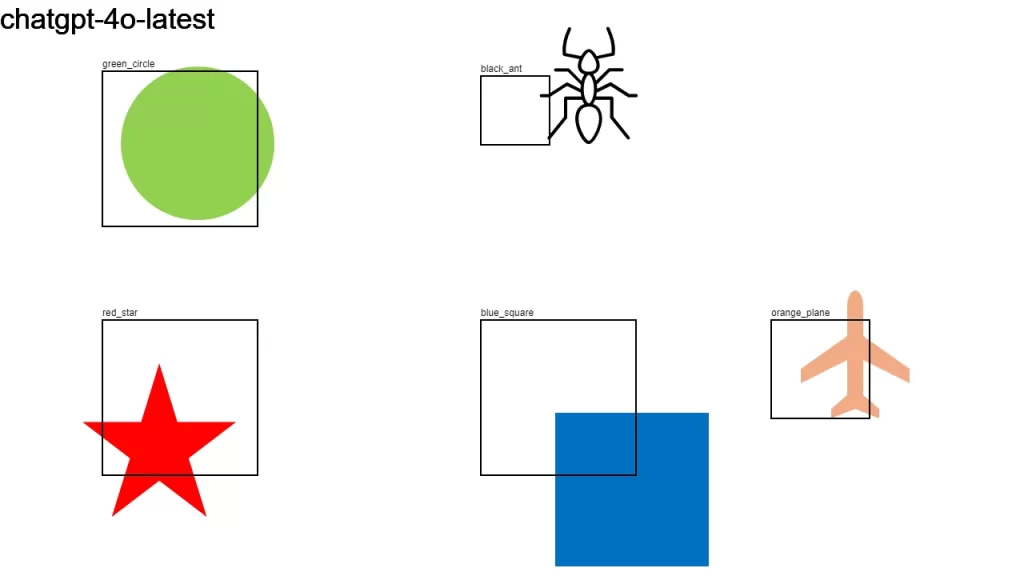
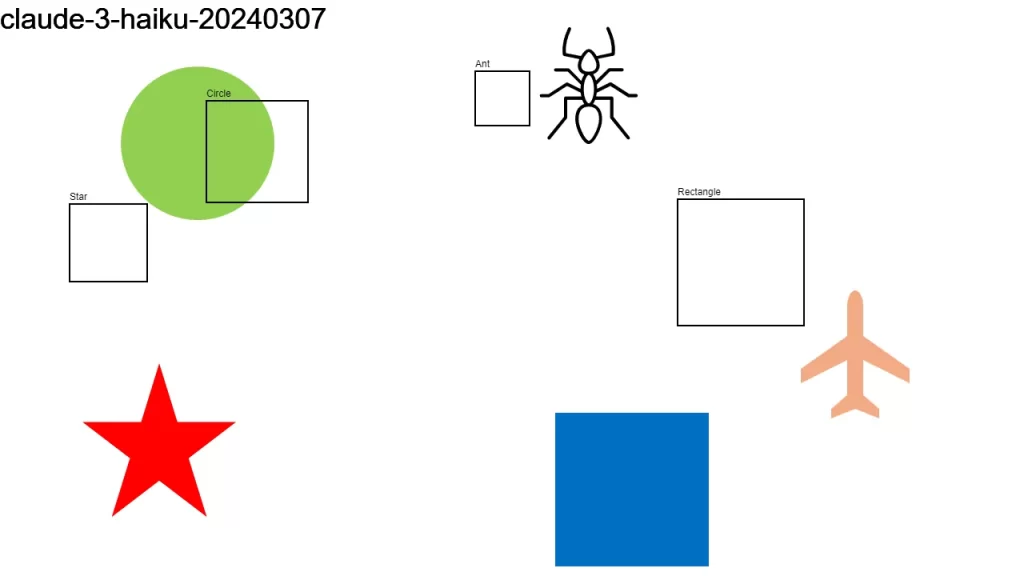
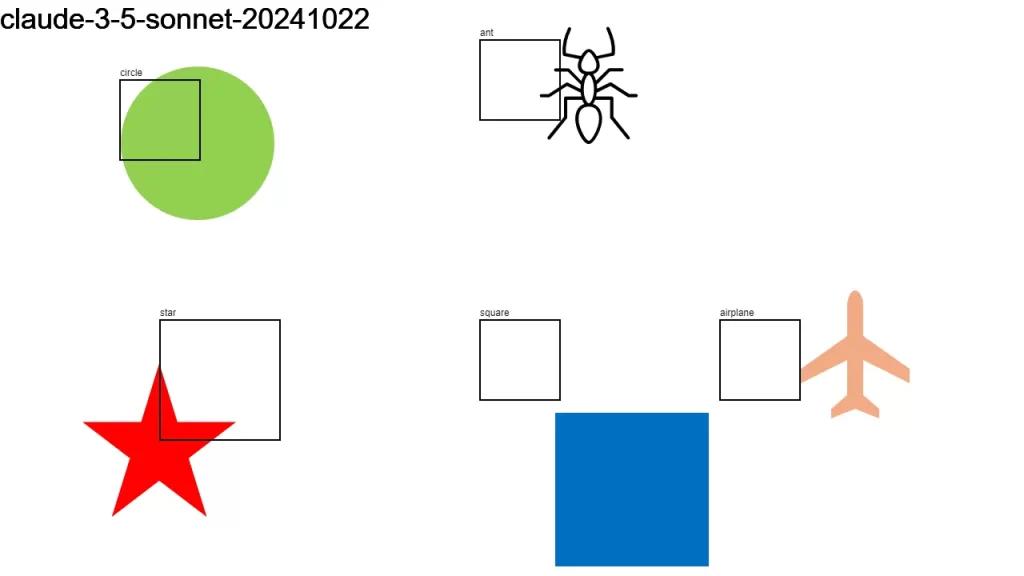
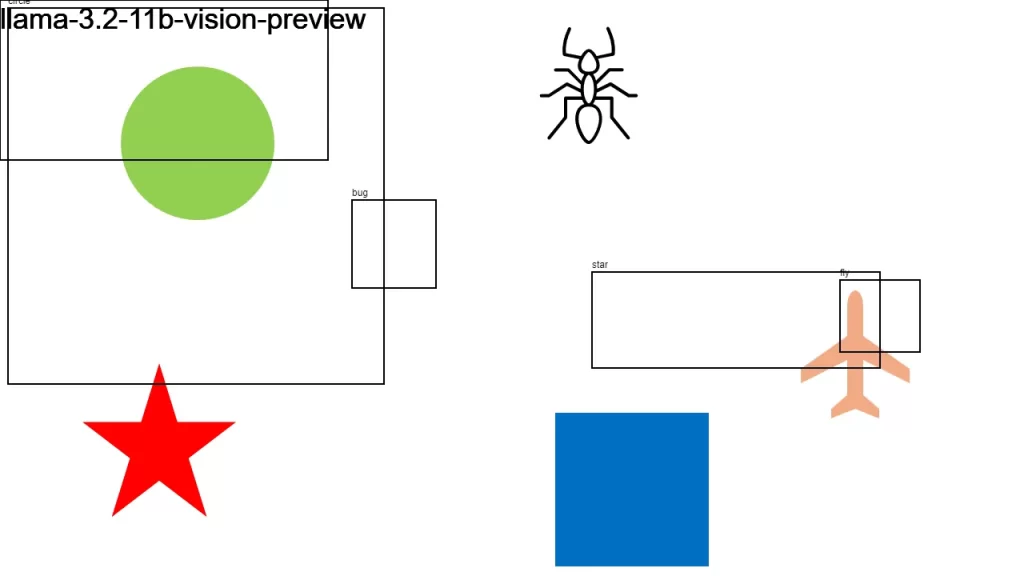
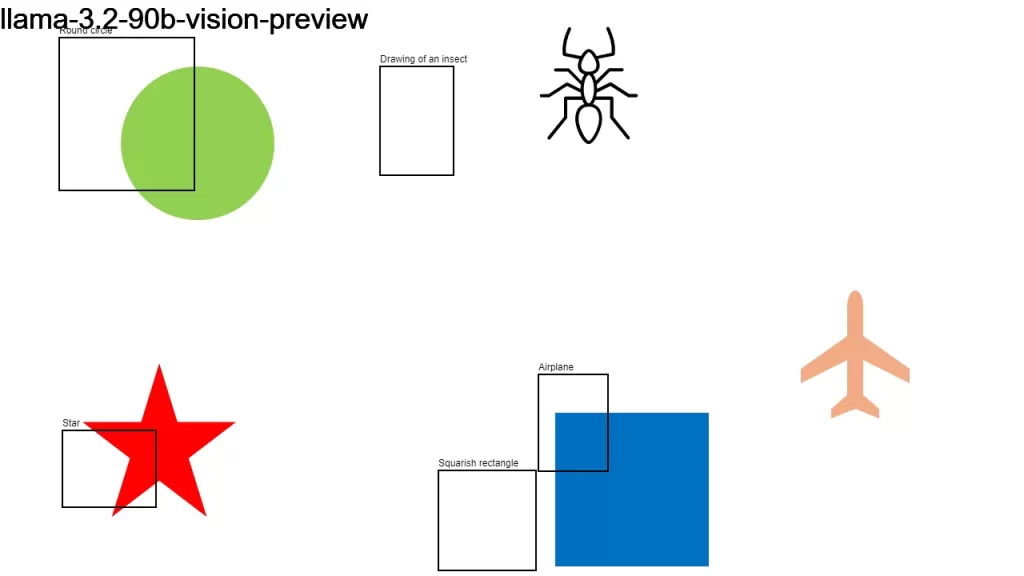
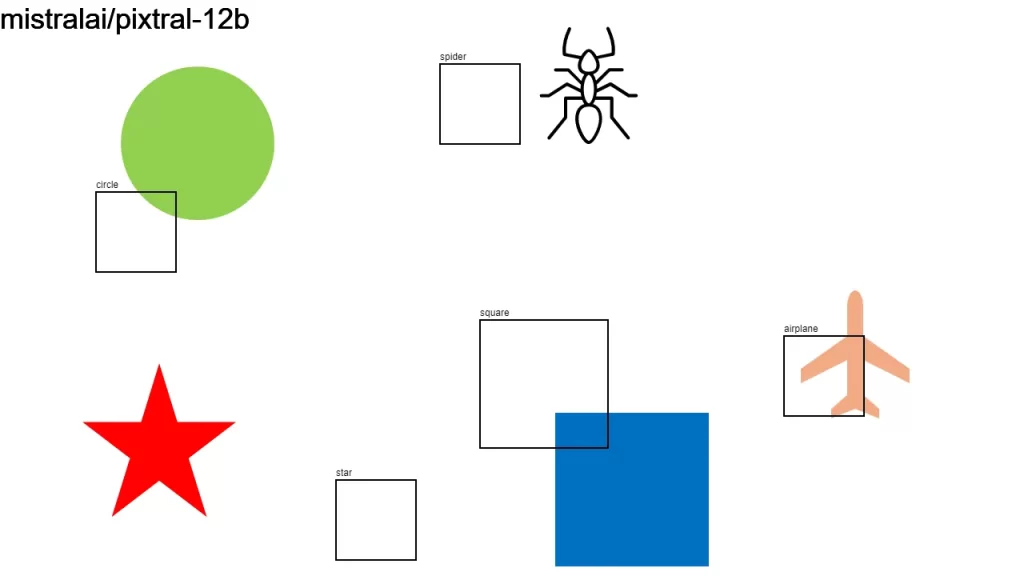
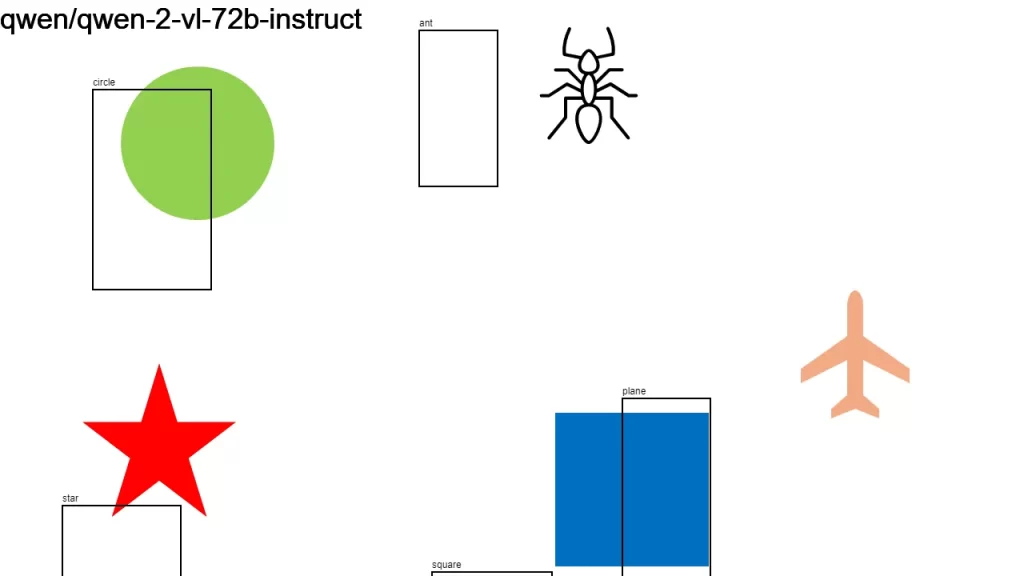
I sent an image to over a dozen LLMs that support vision, asking them:
Detect objects in this 1280×720 px image and return their color and bounding boxes in pixels. Respond as a JSON object: {[label]: [color, x1, y1, x2, y2], …}
None of the models did a good-enough job. It looks like we have some time to go before LLMs become good at bounding boxes.
I’ve given them a subjective rating on a 1-5 scale below.
| Model | Positions | Sizes |
|---|---|---|
| gemini-1.5-flash-001 |   | |
| gemini-1.5-flash-8b | | |
| gemini-1.5-flash-002 | | |
| gemini-1.5-pro-002 | | |
| gpt-4o-mini | | |
| gpt-4o | | |
| chatgpt-4o-latest | | |
| claude-3-haiku-20240307 | | |
| claude-3=5-sonnet-20241022 | | |
| llama-3.2-11b-vision-preview | | |
| llama-3.2-90b-vision-preview | | |
| qwen-2-vl-72b-instruct | | |
| pixtral-12b | | |
I used an app I built for this.
Here is the original image along with the individual results.

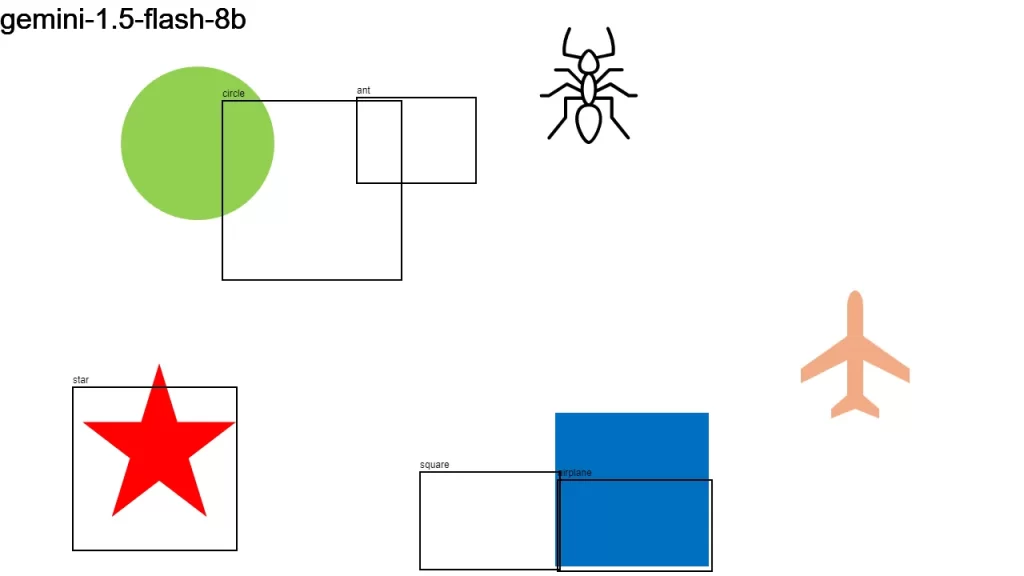
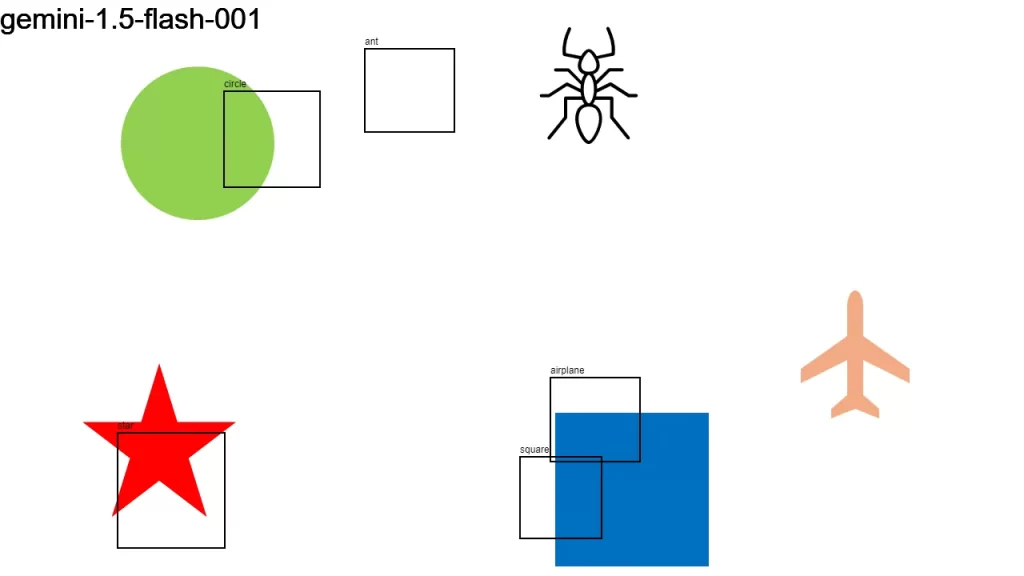
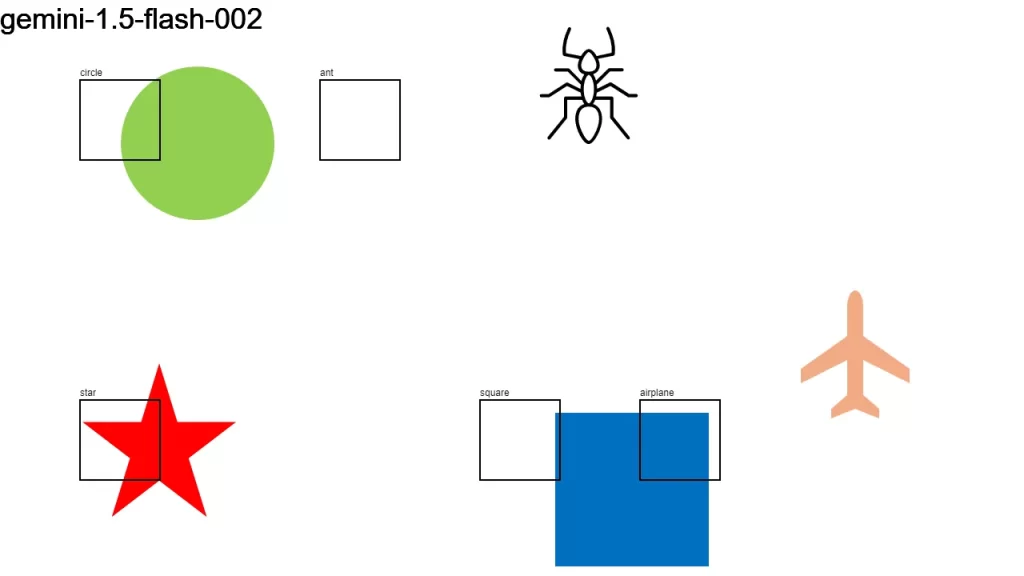
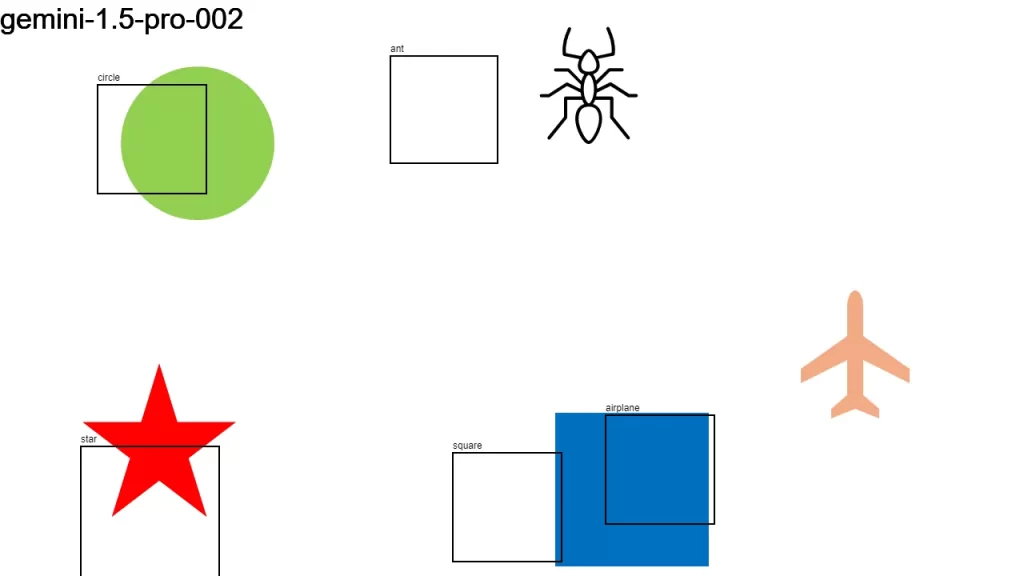
Update
Adding gridlines with labeled axes helps the LLMs. (Thanks @Bijan Mishra.) Here are a few examples: