Most of my screen-scraping so far has been through Perl (typically WWW::Mechanize). The big problem is that it doesn’t support Javascript, which can often be an issue:
- The content may be Javascript-based. For example, Amazon.com shows the bestseller book list only if you have Javascript enabled. So if you’re scraping the Amazon main page for the books bestseller list, you won’t get it from the static HTML.
- The navigation may require Javascript. Instead of links or buttons in forms, you might have Javascript functions. Many pages use these, and not all of them degrade gracefully into HTML. (Try using Google Video without Javascript.)
- The login page uses Javascript. It creates some crazy session ID, and you need Javascript to reproduce what it does.
- You might be testing a Javascript-based web-page. This was my main problem: how do I automate testing my pages, given that I make a lot of mistakes?
There are many approaches to overcoming this. The easiest is to use Win32::IE::Mechanize, which uses Internet Explorer in the background to actually load the page and do the scraping. It’s a bit slower than scraping just the HTML, but it’ll get the job done.
Another is to use Rhino. John Resig has written env.js that mimics the browser environment, and on most simple pages, it handles the Javascript quite well.
I would rather have a hybrid of both approaches. I don’t like the WWW::Mechanize interface. I’ve gotten used to jQuery‘s rather powerful selectors and chainability. So I’ll tell you a way of using jQuery to screen-scrape offline using Python. (It doesn’t have to be Python. Perl, Ruby, Javascript… any scripting language that can use COM on Windows will work.)
Let’s take Google Video. Currently, it relies almost entirely on Javascript. The video marked in red below appears only if you have Javascript.
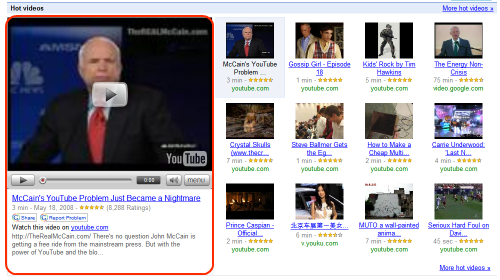
I’d like an automated way of checking what video is on top on Google Video every hour, and save the details. Clearly a task for automation, and clearly not one for pure HTML-scraping.
I know the video’s details are stored in elements with the following IDs (thanks to XPath checker):
| ID |
What’s there |
| hs_title_link |
Link to the video |
| hs_duration_date |
Duration and date |
| hs_ratings |
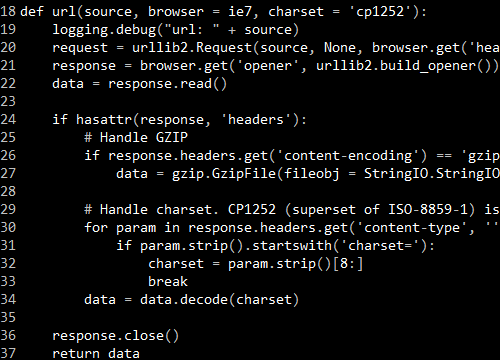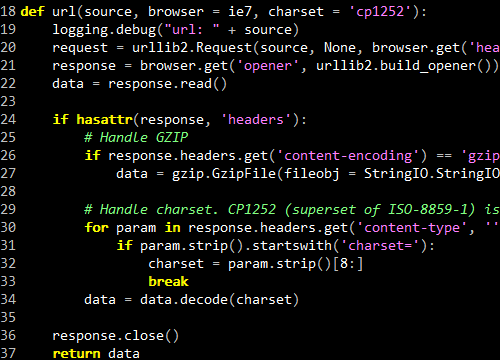
Ratings. The stars indicate the rating and the span.Votes element inside it has the number of people who rated it. |
| hs_site |
The site that hosts the video |
| hs_description |
Short description |
So I could do the following on Win32::IE::Mechanize.
use Win32::IE::Mechanize;
my $ie = Win32::IE::Mechanize->new( visible => 1 );
$ie->get("http://video.google.com/");
my @links = $ie->links
# ... then what? |
use Win32::IE::Mechanize;
my $ie = Win32::IE::Mechanize->new( visible => 1 );
$ie->get("http://video.google.com/");
my @links = $ie->links
# ... then what?
I could go through each link to extract the hs_title_link, but there’s no way to get the other stuff.
Instead, we could take advantage of a couple of facts:
- Internet Explorer exposes a COM interface. That’s what Win32::IE::Mechanize uses. You can use it in any scripting language (Perl, Ruby, Javascript, …) on Windows to control IE.
- You can load jQuery on to any page. Just add a
<script> tag pointing to jQuery. Then, you can call jQuery from the scripting language!
Let’s take this step by step. This Python program opens IE, loads Google Video and prints the text.
# Start Internet Explorer
import win32com.client
ie = win32com.client.Dispatch("InternetExplorer.Application")
# Display IE, so you'll know what's happening
ie.visible = 1
# Go to Google Video
ie.navigate("http://video.google.com/")
# Wait till the page is loaded
from time import sleep
while ie.Busy: sleep(0.2)
# Print the contents
# Watch out for Unicode
print ie.document.body.innertext.encode("utf-8") |
# Start Internet Explorer
import win32com.client
ie = win32com.client.Dispatch("InternetExplorer.Application")
# Display IE, so you'll know what's happening
ie.visible = 1
# Go to Google Video
ie.navigate("http://video.google.com/")
# Wait till the page is loaded
from time import sleep
while ie.Busy: sleep(0.2)
# Print the contents
# Watch out for Unicode
print ie.document.body.innertext.encode("utf-8")
The next step is to add jQuery to the Google Video page.
# Add the jQuery script to the browser
def addJQuery(browser,
url="http://jqueryjs.googlecode.com/files/jquery-1.2.4.js"
document = browser.document
window = document.parentWindow
head = document.getElementsByTagName("head")[0]
script = document.createElement("script")
script.type = "text/javascript"
script.src = url
head.appendChild(script)
while not window.jQuery: sleep(0.1)
return window.jQuery
jQuery = addJQuery(ie) |
# Add the jQuery script to the browser
def addJQuery(browser,
url="http://jqueryjs.googlecode.com/files/jquery-1.2.4.js"
document = browser.document
window = document.parentWindow
head = document.getElementsByTagName("head")[0]
script = document.createElement("script")
script.type = "text/javascript"
script.src = url
head.appendChild(script)
while not window.jQuery: sleep(0.1)
return window.jQuery
jQuery = addJQuery(ie)
Now the variable jQuery contains the Javascript jQuery object. From here on, you can hardly tell if you’re working in Javascript or Python. Below are the expressions (in Python!) to get the video’s details.
# Video title: "McCain's YouTube Problem ..."
jQuery("#hs_title_link").text()
# Title link: '/videoplay?docid=1750591377151076231'
jQuery("#hs_title_link").attr("href")
# Duration and date: '3 min - May 18, 2008 - '
jQuery("#hs_duration_date").text()
# Rating: 5.0
jQuery("#hs_ratings img").length
# Number of ratings '(8,288 Ratings) '
jQuery("#hs_ratings span.Votes").text()
# Site: 'Watch this video on youtube.com'
jQuery("#hs_site").text()
# Video description
jQuery("#hs_description").text() |
# Video title: "McCain's YouTube Problem ..."
jQuery("#hs_title_link").text()
# Title link: '/videoplay?docid=1750591377151076231'
jQuery("#hs_title_link").attr("href")
# Duration and date: '3 min - May 18, 2008 - '
jQuery("#hs_duration_date").text()
# Rating: 5.0
jQuery("#hs_ratings img").length
# Number of ratings '(8,288 Ratings) '
jQuery("#hs_ratings span.Votes").text()
# Site: 'Watch this video on youtube.com'
jQuery("#hs_site").text()
# Video description
jQuery("#hs_description").text()
This wouldn’t have worked out as neatly in Perl, simply because you’d need to use -> instead of . (dot). With Python (and with Ruby and Javascript on cscript), you can almost cut-and-paste jQuery code.
If you want to click on the top video link, use:
jQuery("#hs_title_link").get(0).click() |
jQuery("#hs_title_link").get(0).click()
In addition, you can use the keyboard as well. If you want to type username TAB password, use this:
shell = win32com.client.Dispatch("WScript.Shell")
shell.sendkeys("username{TAB}password") |
shell = win32com.client.Dispatch("WScript.Shell")
shell.sendkeys("username{TAB}password")
You can use any of the arrow keys, control keys, etc. Refer to the SendKeys Method on MSDN.