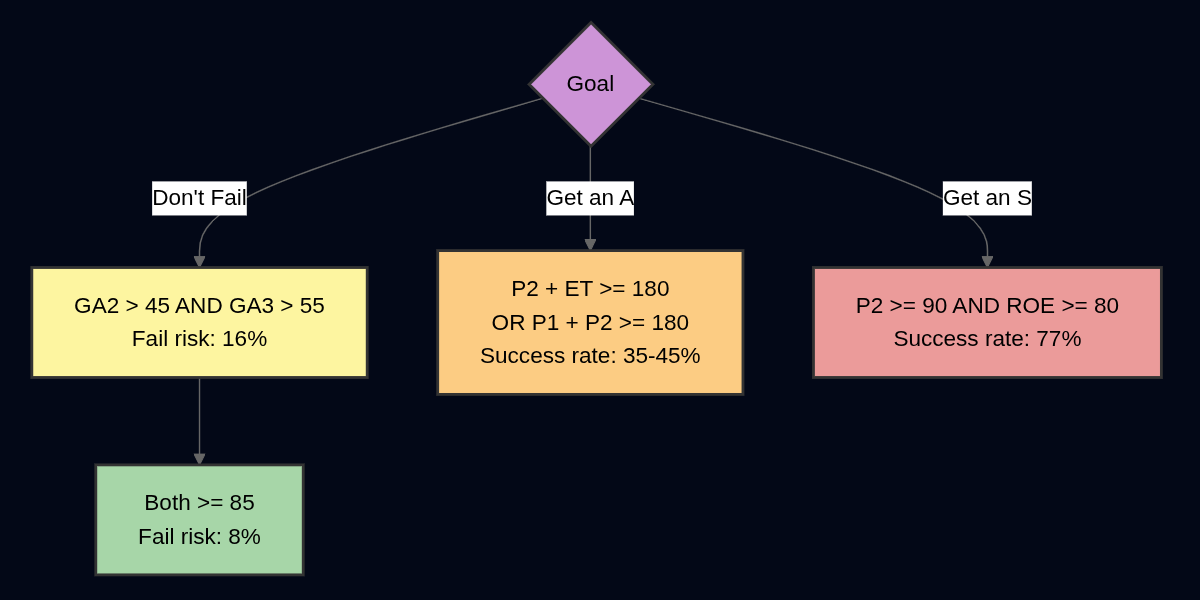
Things I Learned - 12 Oct 2025
This week, I learned: ‘…as few as 250 malicious documents can produce a “backdoor” vulnerability in a large language model… data-poisoning attacks might be more practical than believed." Anthropic Tim Urban’s 2015 article, The AI Revolution: The Road to Superintelligence, is surprisingly relevant. A key theme is that post artificial-super-intelligence, pretty much anything we know / predict is probably wrong. LLMs are bad at asking questions, so you need to plan on their bahlf first. LLMs are bad at copy paste, so giving them a scaffolding to edit helps. Two things LLM coding agents are still bad at The VPN industry is a consolidating oligopoly that doesn’t offer much security and biases towards affiliates. Who Owns Express VPN, Nord, Surfshark? As of 2025, a fine-tuned DeBERTa-v3-Large / RoBERTa-Large model is better than an LLM at emotion classification. roberta-base-go_emotions is a good starting point if you don’t want to fine-tune. ChatGPT OpenAI defines an AI agent as “a system that can do work independently on behalf of the user”. swyx Brain coding is the new term for human coding - as opposed to vibe-coding (AI codes, human doesn’t review code) and AI coding (AI codes, human reviews code). npx -y emoj lets you type text and pick a relevant emoji. Many people who shifted away from conflict aversion did so by systematizing it. ChatGPT Martin Luther King Jr institutionalized not stepping back from conflicts in his movement. Kim Scott (Radical Candor) practiced caring more via short, specific feedback loops. Kwame Christian (Compassionate Curiosity) practiced ask open questions. Ed Catmull (Pixar) instituted Braintrust to ask candid questions. Ray Dalio (Bridgewater) instituted radical transparency. Many people who adopted a failure-seeking mindset made failure frequent, small, cheap, and informative. ChatGPT Jia Jiang ran a 100-day rejection challenge, acclimatizing himself to failure. Kim Liao (writer) moved from submission-avoidance to “100 rejections/year”. Reshma Saujani (Girls Who Code) built a practice of “brave, not perfect” - ship before perfect. Ray Dalio (Bridgewater) instituted mistake logs and “pain + reflection = progress”. Astro Teller (X, the Moonshot Factory) rewired incentives so teams are rewarded for killing their own ideas early. Sara Blakely (Spanx) set weekly failure quotas. Kathryn Schulz (author of Being Wrong) converts failures into teaching methods. Sindre Sorhus has already created a micro-framework css-extras using CSS @functions. Today, if I had to build agents, here are the tools and environment capabilities I’d ask for: Ask user (for clarifications) Internet tools Search Fetch (CORS-piercing) Scraper with XPath/CSS Selectors Access to llms.txt LLM APIs Summarizer (condenses chat) Sub-agents Coding tools Markdown convertor Code execution (including tests) Browser + DevTools for testing Memory / storage Tool/MCP directory with search Noting a few things that I find #impossible to do today with LLMs: LLMs can’t run experiments / explorations, like trying out on a new tool or web app in an environment, the way I would. LLMs can’t move stuff on my machine, e.g. notes from one list to another, when they’re only on my laptop, not GitHub. LLMs can’t capture the past wisdom in my head, e.g. the distilled principles of data visualization that we applied at Gramener. LLMs can’t prioritize my to-do list based on my preferences and what’s important to me. LLMs cannot write a blog post in my style of writing. When recruiting for people in the LLM era, look for questioning ability, sensible thinking, and how they use AI. Give them lots of fluff and context. Can they cut through it? Is their answer concise and to the point or waffling? Like post the industrial revolution, more people will become operators looking after AI, not craftsmen. This includes coding. zx is a nice JS-based alternative to shell scripts. const branch = await $`git branch --show-current`; await $`dep deploy --branch=${branch}`; docker run -it --name test --user vscode mcr.microsoft.com/devcontainers/base:ubuntu gives you a test Ubuntu image closer to a desktop / user setup rather than a server. Useful to try out apps.