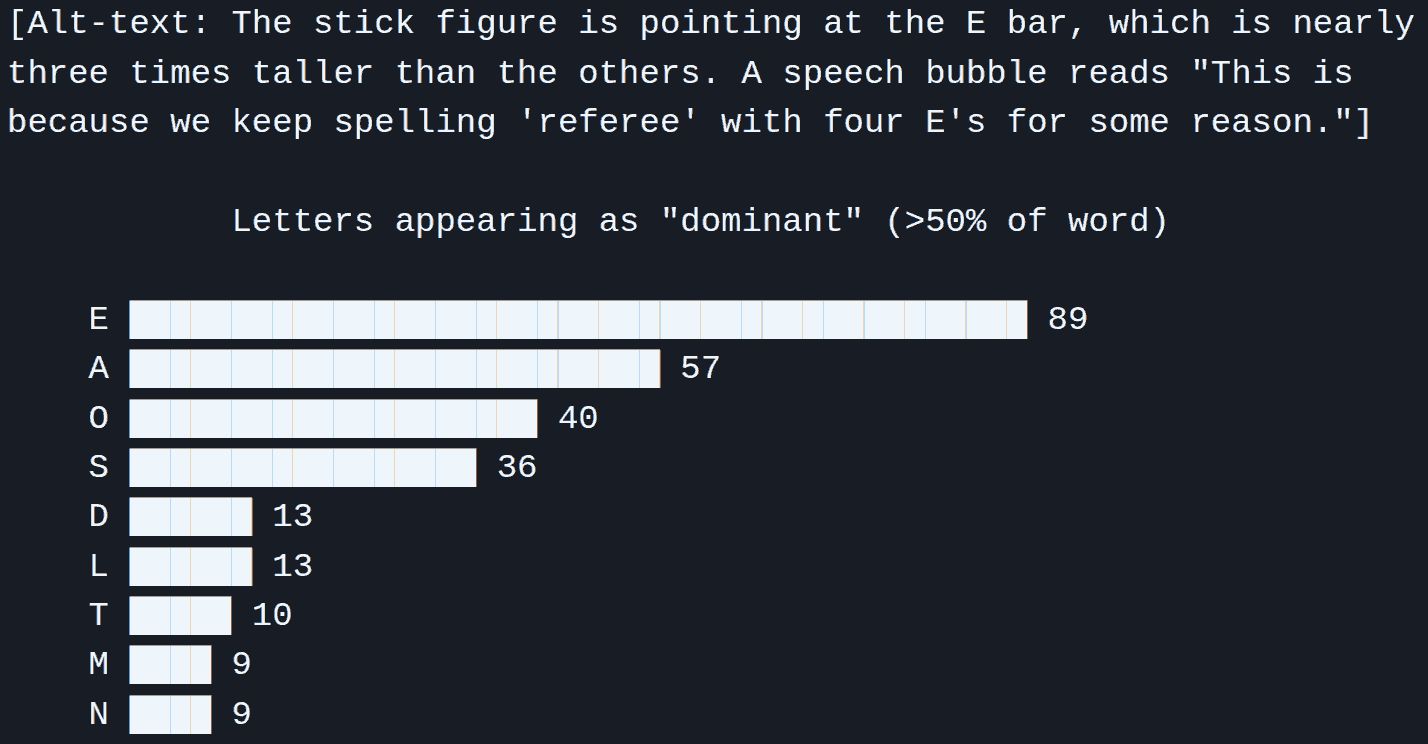
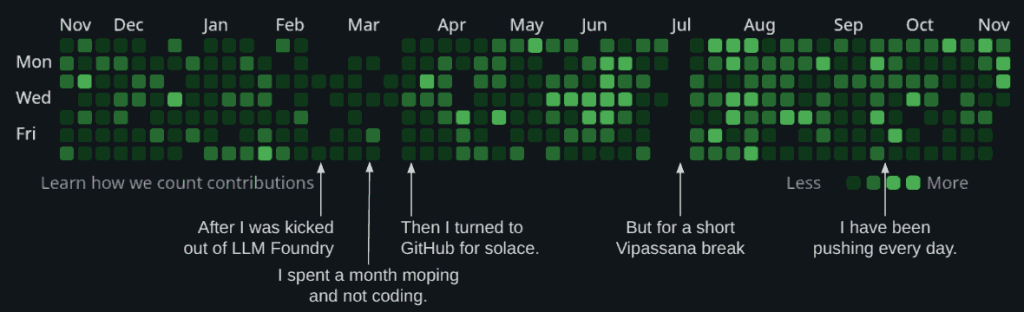
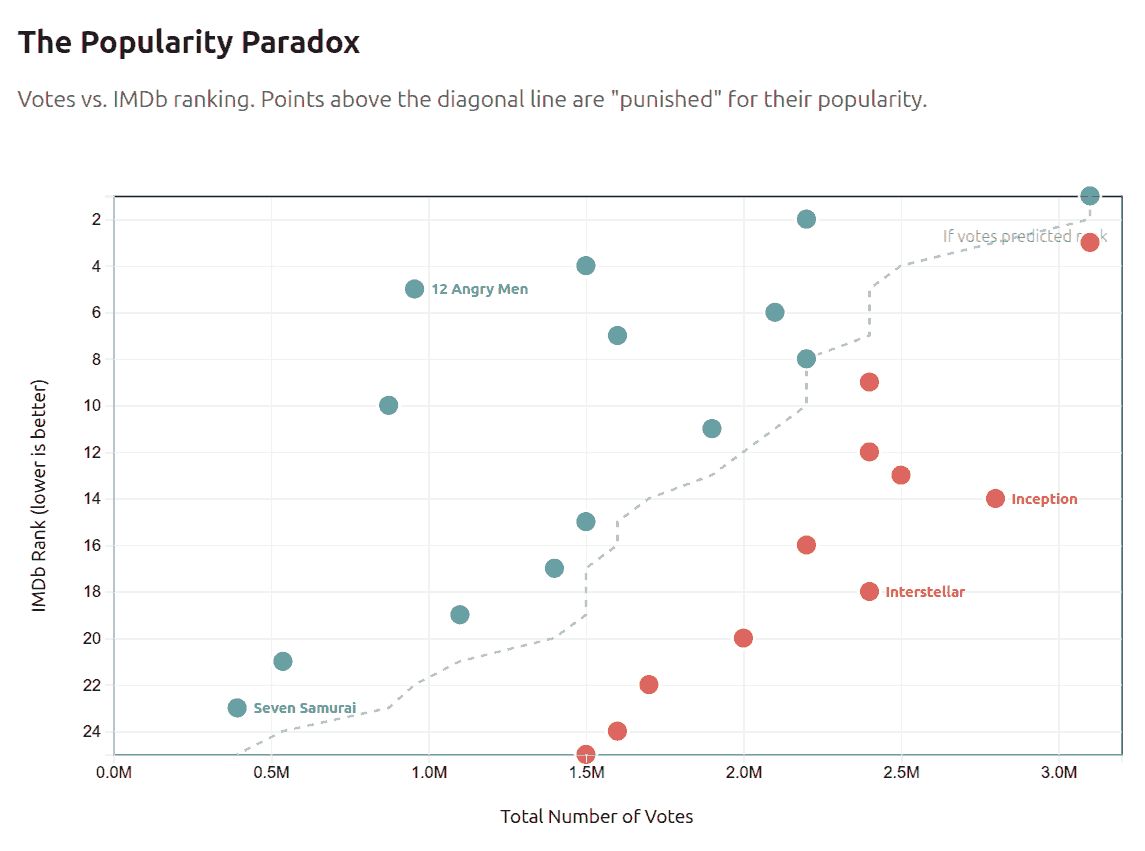
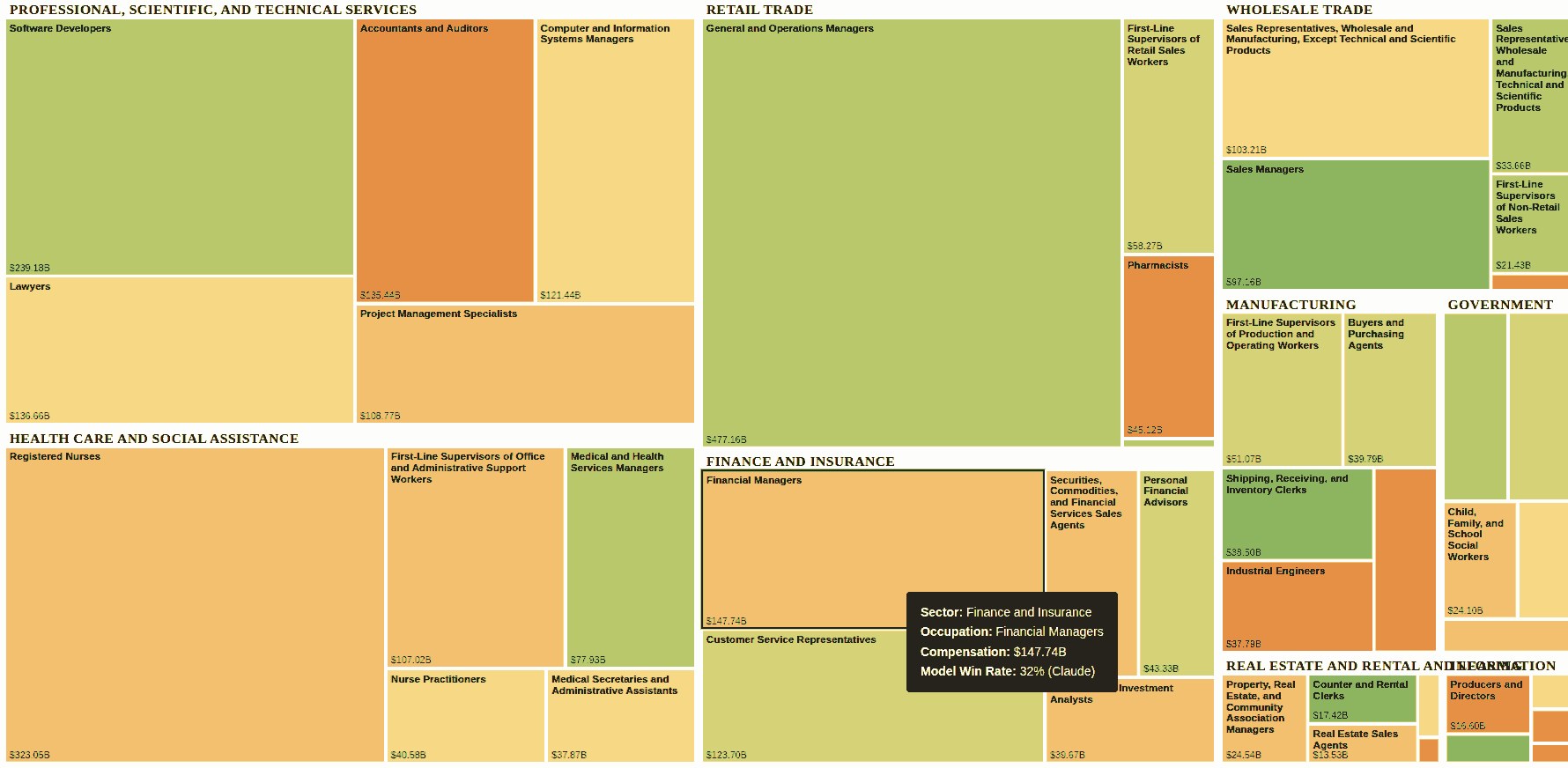
Things I Learned - 23 Nov 2025
This week, I learned: Here are some new CLI tools I installed: vd (visidata): Terminal spreadsheet viewer & editor for CSV, Excel, JSON, SQL, Parquet, etc. qsv: Fast CSV command line toolkit for slicing, filtering, aggregating, and analyzing CSV files. rga (ripgrep-all): ripgrep that searches PDFs, Office docs, EPUBs, zip files. pdfcpu: PDF processor for splitting, merging, optimizing, and manipulating PDF files. gum: Stylish CLI tool for creating interactive prompts, confirmations, and more. Models read pretty fast, consuming input tokens at ~4K-20K words per second. It’s the “speaking” (output token rate) that is the bottleneck. So shortening input doesn’t matter as much as shortening output for latence. ChatGPT When building agents, as of now, prefer native provider SDKs (OpenAI Agents SDK, Anthropic SDK) over even light abstractions like Vercel AI SDK or Pydantic. There are subtle issues related to error messages, response handling, cache handling, etc. that trip up abstractions given how early things are. Armin Ronacher Gone are the times when LLMs couldn’t do mental math. Now they’re computing base64 and SHA256 from memory, without needing code! Example Organizing a round table event in Singapore costs ~$75-150. Here’s what drives the cost variation # 50%: brand/location. 25%: food and beverage. 15%: duration (full day is only slightly more expensive than half day) 10%: date, demand, etc. 10%: add-ons: AV, etc. OpenRouter supports embedding models. BGE base seems pareto optimal with 0.5 cents / MTok and a good MTEB ranking. TOON vs JSON. Early days, and TOON seems to be marketing a lot, so I’m wary, but for large tabular data where input tokens are crunched, it seems a readable alternative to multiple CSVs, but not worth the hype. 0 19 Nov 2025. Always use GPT-5.1-Codex-Max instead of GPT-5.1-Codex. At every thinking level, it takes fewer tokens for similar or higher accuracy. Tibo ug -i --smart-case --bool 'word1 word2 ...' seems the cleanest way to find files that have all words. –smart-case uses case-insensitive if all words are lowercase, else case-sensitive. Examples: ug --bool '"exact phrase" word2' # exact phrase + other tokens anywhere ug --bool 'word1 word2 -word3' # must contain word1 AND word2, but NOT word3 ug --bool '("foo bar") OR baz' # grouped expressions and OR ug --bool 'word1 NEAR/5 word2' # match when words are within 5 tokens/words ug -Z2 'word' # allows up to 2 typos in 'word' ⭐ ug -i --smart-case --bool -Q lets you interactively search within files. This is the coolest feature! Fixing laptop issues is clearly a whole lot easier with an AI chatbot. I fixed these Ubuntu issues purely using Claude. It told me what to run. I ran it, shared the output, it diagnosed, told me what to do next, etc. until the issues were fixed. For example: My keyboard shortcuts stopped working. It turned out I edited my media-keys.dconf and removed the trailing slash. # A 3-finger tap mapped to a middle click and I couldn’t remove it. It turned out my touchegg.conf explicitly had this mapping. I disabled it. # My gnome extensions would get disabled every time the screen went to sleep. It turned out my extension cache was corrupted or stale. sudo apt install --reinstall gnome-shell-extension-manager and rm -rf ~/.cache/gnome-shell/ fixed it. # GhostScript seems the best way to compress PDFs via the CLI. Example: gs -sDEVICE=pdfwrite -dCompatibilityLevel=1.4 -dPDFSETTINGS=/screen -dNOPAUSE -dQUIET -dBATCH -sOutputFile=output.pdf input.pdf Pandoc supports Lua filters which are a powerful way to customize the document conversion process. Here is a Lua filter that converts horizontal rules in a markdown document to page breaks and preserve in a Word document (OpenXML format) function HorizontalRule() return pandoc.RawBlock('openxml', '<w:p><w:r><w:br w:type="page"/></w:r></w:p>') end readpst - via sudo apt install pst-utils - extracts emails from Outlook PST files to mbox format. Useful for email migrations. Write tutorials or blog posts as you learn. Steve Klabnik Running a coding agent post mortem, e.g. “what worked well, what didn’t, and why? Next time, what are a few bullets I could include that will avoid these problems?” helps me prompt better next time. For example, Claude Code suggested: Use Firefox for headless browser automation (Chromium often crashes) Set HOME=/root when running Playwright with Firefox Start a local HTTP server rather than using file:// protocol External images may not load in screenshots due to network isolation