Excel - Avoid manual labour 3
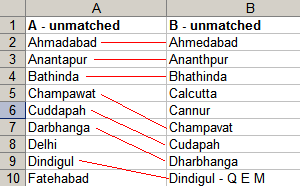
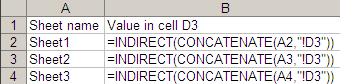
A corollary of Rule 3: Never type the same formula twice. Design the formula so that if you cut and paste it elsewhere, it works correctly. The $ symbol and the F4 key for cell references help in 90% of the cases. For complex requirements and large data, 5 functions come in handy: INDIRECT, OFFSET, ADDRESS, ROW and COLUMN. I once did a survey, and had data spread across 300 sheets (same format on all sheets). I needed cell D3 across all sheets in a column, to summarise the results. The image explains what I did. ...