Terence Tao said, “We haven’t done many experiments … large-scale studies where we take a thousand problems and just test them.”
So I told Claude: You know my style. Suggest some innovative experiments I could run.
The first suggestion was cool! The Polya Audit. Polya’s How to Solve It lists 20 heuristics (work backwards, induction, analogy, etc.). Mathematicians treat these as wisdom. Nobody has ever measured which ones actually work, and on what problem types.
So I prompted Copilot running Claude Sonnet 4.6 to run the LeanDojo Benchmark through an LLM n times, with different Polya heuristic system prompts and compare success rates.
Not-surprisingly different heuristics help different problems.
- Almost every heuristic helps Prealgebra - except “Start from the desired answer and reason step by step back toward the given information.”.
- Almost no heuristics helps Number Theory - except “Focus on the largest, smallest, or boundary element. Extremal elements often have special properties.”.
- Geometry has an enormous swing. “First strip away complexity and solve an easier version. Observe the pattern, then generalize” helps a lot. But “Find a quantity that can be counted in two different ways. Set up both expressions and equate them” hurts a lot.
The impact of each heuristic is also quite varied.
- The most reliable heuristic is segmentation: “Identify the key condition that splits the problem. List all possible cases exhaustively. Handle each with a complete argument.”
- The worst heuristic on average is pattern recognition: “Compute several specific instances. Tabulate results. Identify a pattern. State the conjecture. Then prove or use it.” Induction and pigeonhole do pretty bad, too.
Also not-surprisingly, different models respond differently to the same heuristic.
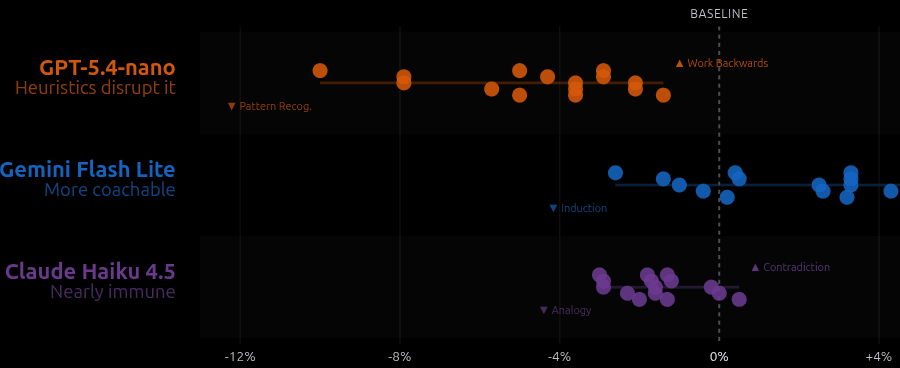
- GPT-5.4-nano: Heuristics disurpt it. Its built-in problem-solving strategy is already good. Heuristic just make things worse, almost always.
- Gemini 2.5 Flash Lite: More coachable. Like a student who benefits from advice: it gains up to 6 percentage points from the right heuristic.
- Claude Haiku: Nearly immune. It seems to just ignore the heuristic. Its performance barely moves regardless of what you tell it.
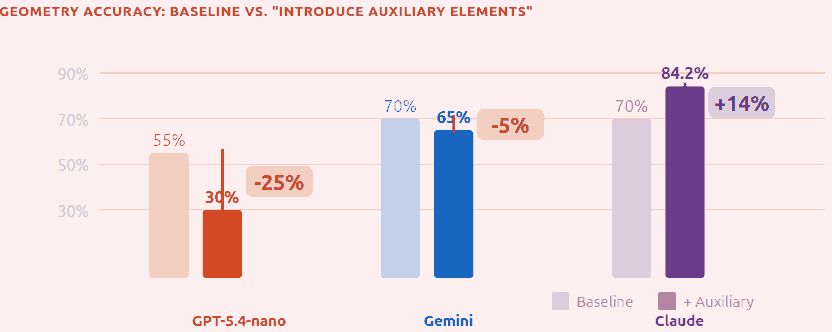
The same heuristic on the same problem affects models quite differently, too. For example “Introduce Auxiliary Elements” hurts GPT -25% but helps Claude +14%!
So yes, different heuristics work for different problems, and different models respond differently to the same heuristic.
But finally, at least for LLMs, we can measure. We can find out which heuristics work for which problems, and which heuristics get varied responses vs which ones are more universally helpful / harmful. And maybe teach humans.
Or maybe not.
