Yesterday, I discovered how much reasoning improves model quality.
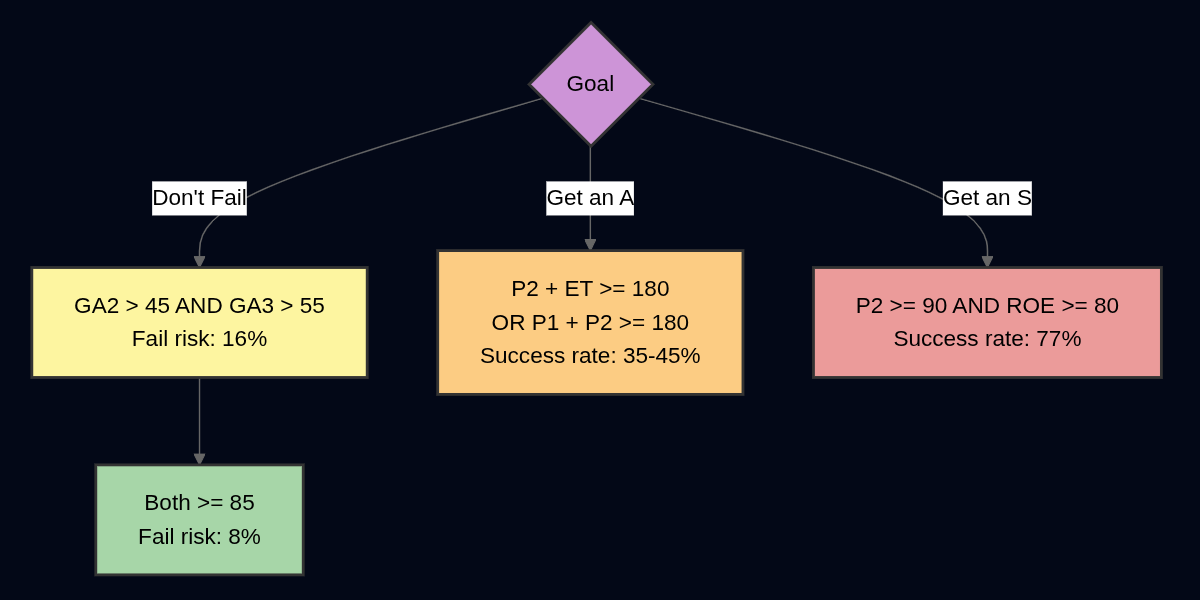
My Tools in Data Science assignment asks students to draft an llms.txt file for ipify and auto-checks with GPT-5 Nano - a fast, cheap reasoning model.
I set reasoning_effort to minimal and ran this checklist:
1. Starts with "# ipify" and explains ipify. 2. Markdown sections on API access, support (e.g. GitHub, libraries). 3. Covers API endpoints (IPv4, IPv6, universal) and formats (text, JSON, JSONP). 4. Mentions free, no-auth usage, availability, open-source, safeguards. 5. Has maintenance metadata (e.g. "Last updated: <Month YYYY>"). 6. Mentions robots.txt alignment. Stay concise (no filler, <= ~15 links). If even one checklist item is missing or wrong, fail it. Respond with EXACTLY one line: PASS - <brief justification> or FAIL - <brief explanation of the first failed item>. With a perfect llms.txt, it claimed “Metadata section is missing” and “JSONP not mentioned” – though both were present.
...