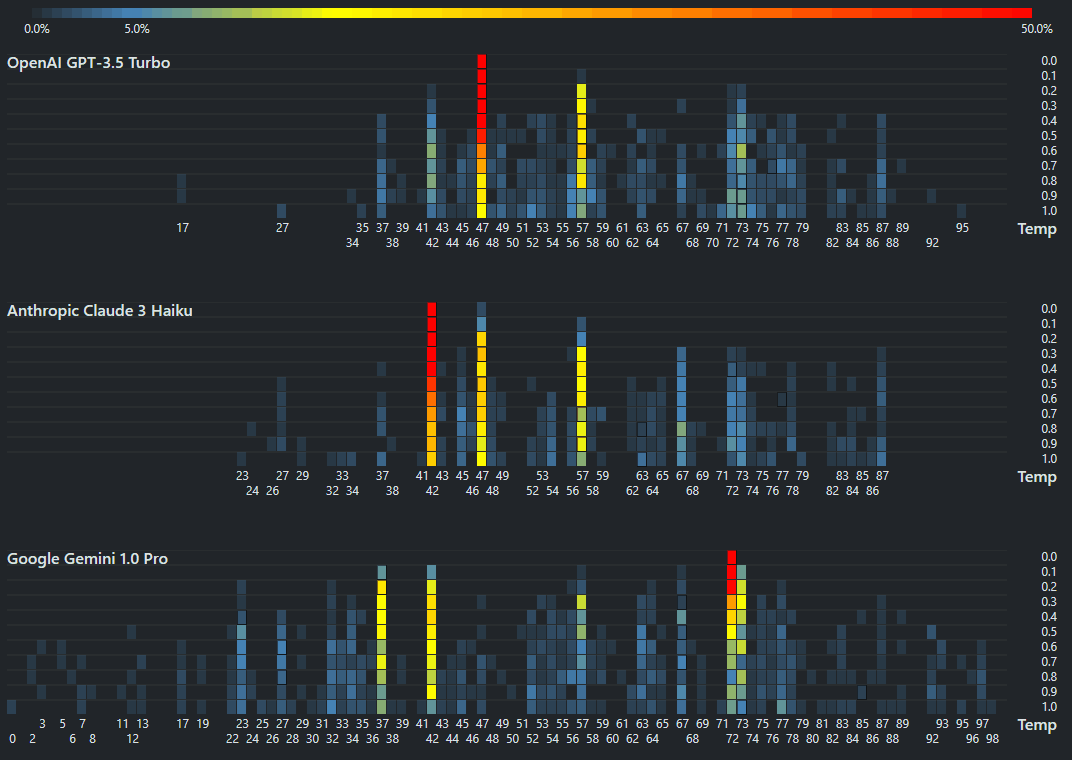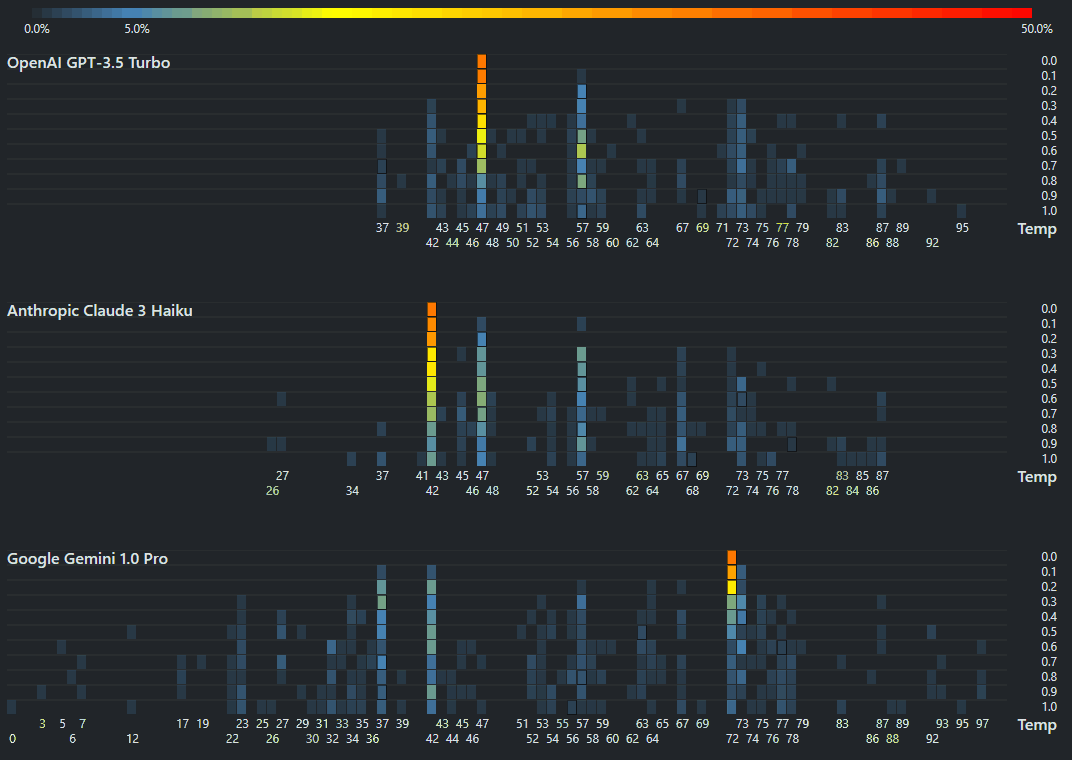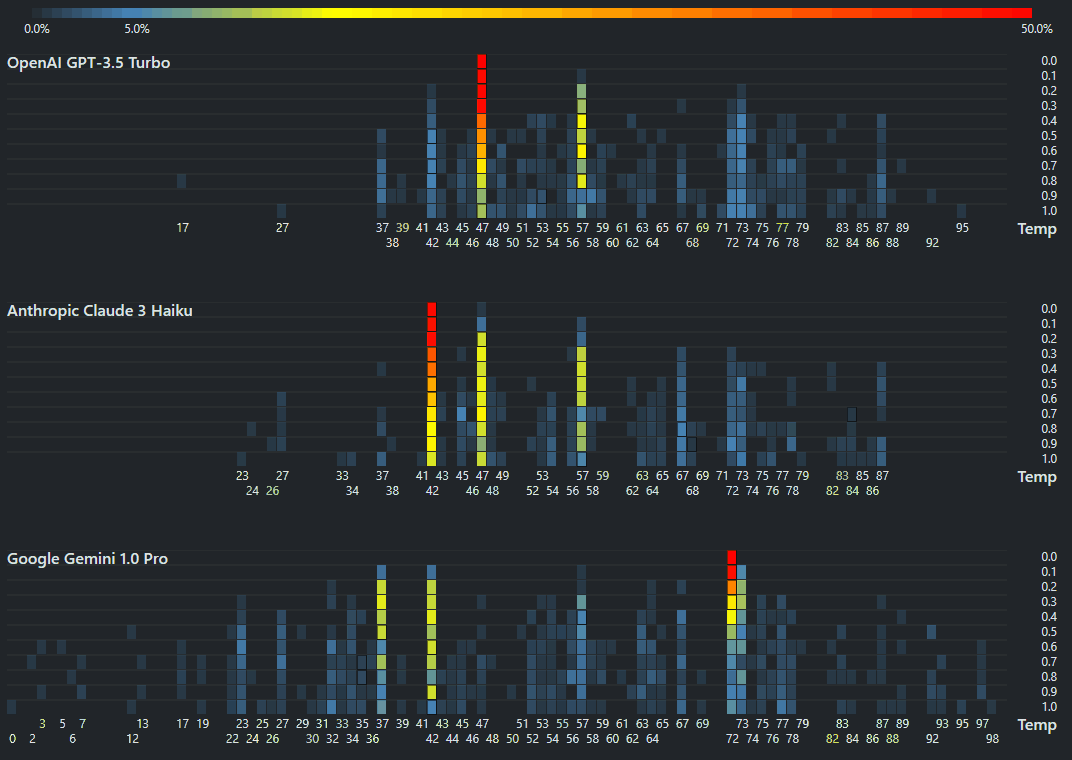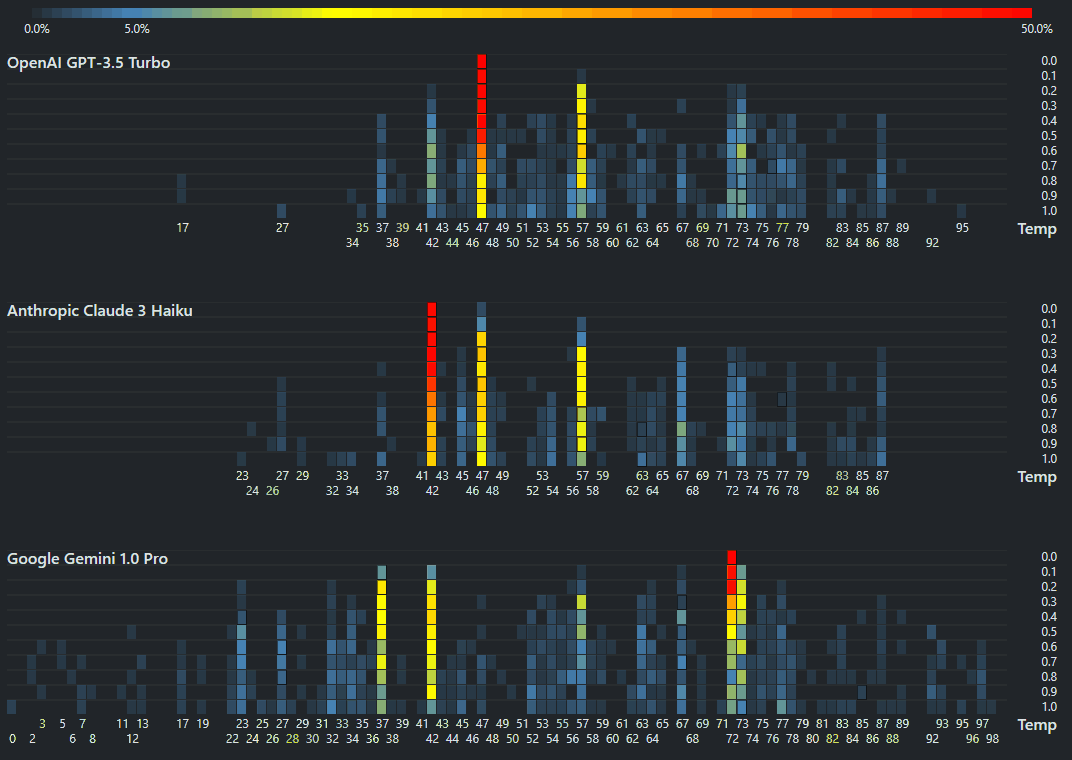
A quick way to assess LLM capabilities
Simon Willison initiated this very interesting Twitter thread that asks, “What prompt can instantly tell us how good an LLM model is?” The Sally-Anne Test is a popular test that asks: Sally hides a marble in her basket and leaves the room. While she is away, Anne moves the marble from Sally’s basket to her own box. When Sally returns, where will she look for her marble?" ...